
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事はマルチモーダル大規模言語モデルについての調査報告を紹介します。
「マルチモーダル」とは、異なる種類のデータ(例えば、テキスト、画像、音声など)を組み合わせて扱うことを意味します。元々は言葉だけを扱っていたLLMが、複数の種類のデータの入力や出力に対応できるようになってきたのが現状です。
今回Tencentや京都大学などの研究者らは、マルチモーダルLLMに関する広範な調査を行った結果を報告しています。設計や訓練方法、26種類の既存モデルなどに言及しています。

参照論文情報
- タイトル:MM-LLMs: Recent Advances in MultiModal Large Language Models
- 著者:Duzhen Zhang, Yahan Yu, Chenxing Li, Jiahua Dong, Dan Su, Chenhui Chu, Dong Yu
- 所属:Tencent AI Lab, 京都大学, Mohamed Bin Zayed University of Artificial Intelligence
- URL:https://doi.org/10.48550/arXiv.2401.13601
研究背景
LLMは、大量のテキストデータから学び、人間の言葉を理解し、生成する技術です。そんなLLMが、多様な形式のデータを扱えるように発展した「マルチモーダルLLM」と呼ばれるモデルが注目されるようになってきました。
LLMがもともと持つ強力な言語生成能力や、新しいタスクにもゼロショットですぐに対応できる能力などが他のモダリティに活かされ強化されている状況です。研究者たちは異なる種類のデータを統合して協力し解析する方法を模索しています。例えば、画像からテキストを生成したり、音声を生成したりするなど、さまざまなデータ間での変換が可能になってきています。
研究が非常に進んできたため、今回研究者らは現況を下記の軸でまとめました。
- マルチモーダルLLMの設計や訓練方法
- 26種類の最先端モデルの特徴や開発トレンド
- タスク性能
- より効果的なモデルのための方向性
なお下記の図はマルチモーダル大規模言語モデル(MM-LLMs)の発展を示しています。2022年初頭から2023年末まで、短期間に多くの新しいモデルが導入されていることがわかります。
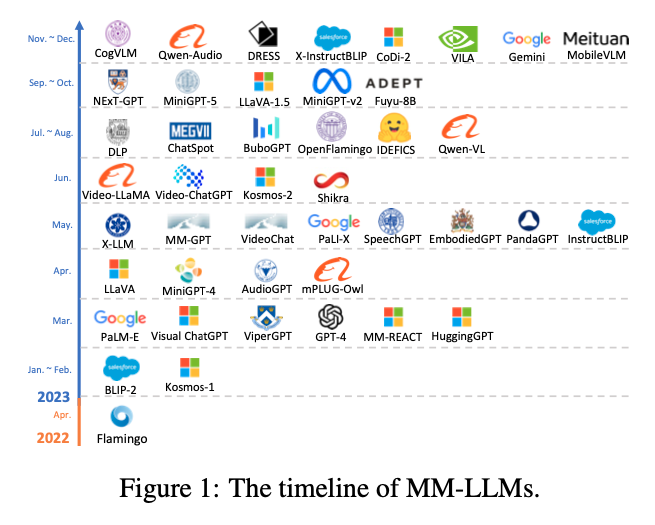
以下では、マルチモーダルLLMの仕組み、訓練のステップ、モデル事例(26種類、リンク付き)とベンチマーク、今後の展望について紹介します。
仕組み
マルチモーダルLLMは、主に、

