
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
Googleは、人間の専門家のパフォーマンスを上回る最初の大規模言語モデル(LLM)として「Gemini」を発表しました。LLMの主要なベンチマークの一つであるMMLU(多領域の学術ベンチマーク)をはじめとするほとんどのベンチマークでGPT-4を凌駕しています。
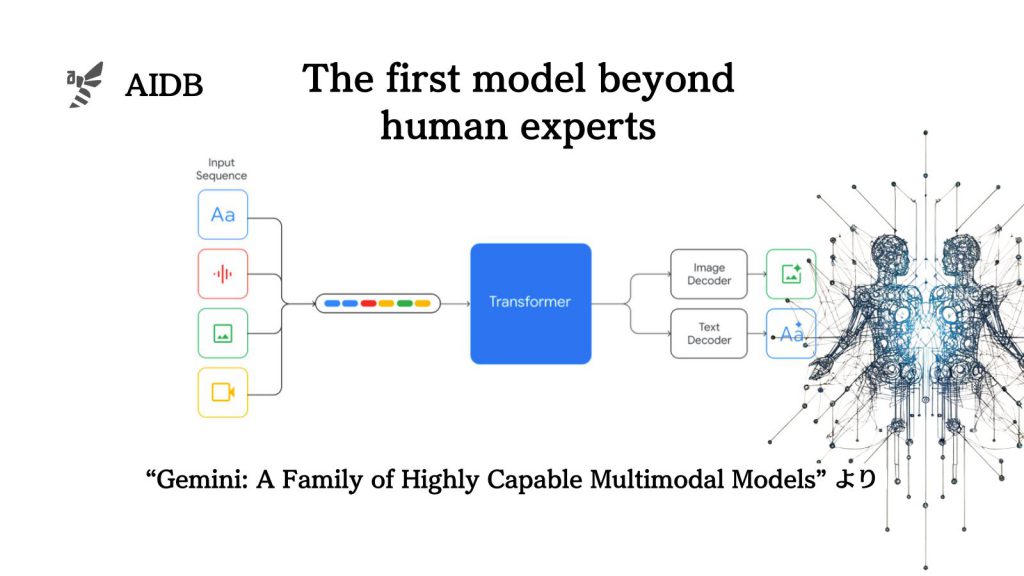
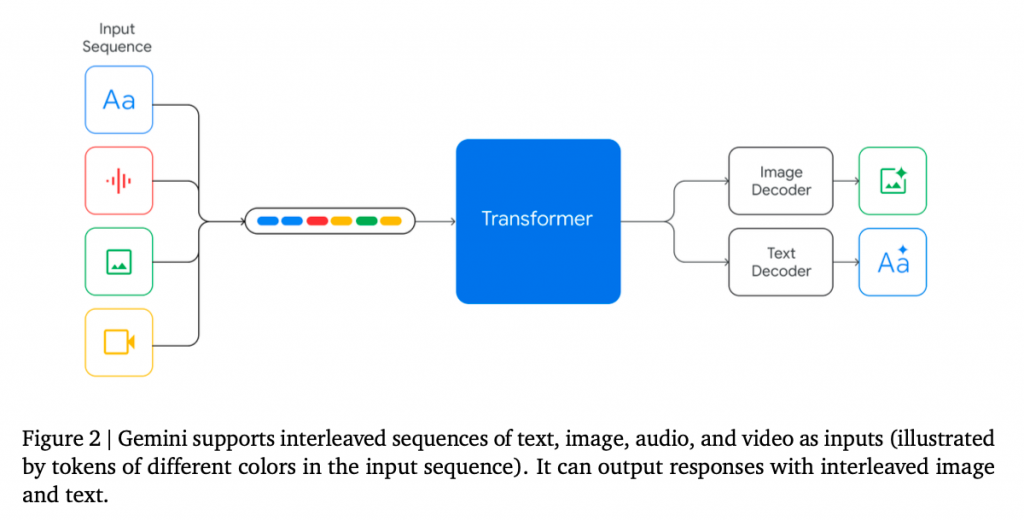
Geminiは、画像、音声、動画の理解を含むマルチモーダルタスクでも最先端の性能を示しています。テストに使用された20のマルチモーダルベンチマーク全てで最高の水準を達成しています。
また、複数のソースからの情報を統合して、より正確で詳細に理解する能力に優れているとのことです。
なお、Ultra、Pro、Nanoの3つのサイズがあり、それぞれ異なる計算要件に特化して設計されています(例えばモバイル向けにはNanoなど)。Ultraは最も高度に複雑なタスクをこなし、研究報告では主にUltraの性能が他モデルと比較されています。
本記事では、テクニカルレポートをもとにGeminiを紹介します。
参照論文(テクニカルレポート)情報
- タイトル:Gemini: A Family of Highly Capable Multimodal Models
- 著者:Gemini Team(詳細な著者一覧は論文内のコントリビュートに記載)
- 所属:Google
- URL:https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
- ブログ:https://blog.google/technology/ai/google-gemini-ai/
- プロジェクトページ:https://deepmind.google/technologies/gemini/
研究背景
近年、AI研究においては、画像や音声、ビデオ、テキストなどのさまざまなデータを組み合わせて、人間よりも優れた理解と推論能力を持つモデルを開発する取り組みが進められています。
さまざまな情報を組み合わせて理解する能力を持つモデルはマルチモーダルモデルと呼ばれており、人間の認知における重要な能力を模倣するものです。
マルチモーダルを理解する機械知能の研究は、以前から行われており、初めは画像とテキストを組み合わせた理解や、音声とテキストを組み合わせた理解などの研究が行われていました。
その後、画像認識や音声認識などの技術が急速に進歩し、マルチモーダルの研究も進展しました。
さらに重要な分岐点として、トランスフォーマーモデルと呼ばれる技術が開発されました。トランスフォーマーモデルは、マルチモーダル理解に適した技術であり、マルチモーダルの研究に大きな進歩をもたらしました。
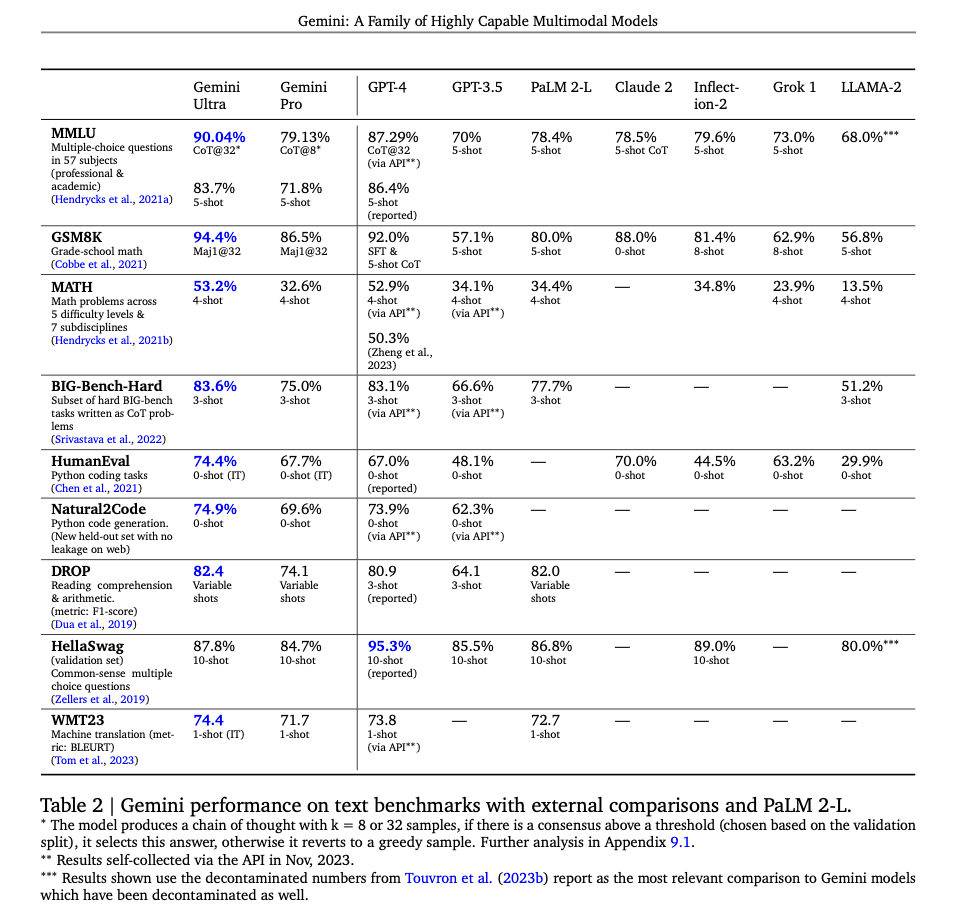
そして今回、Googleはマルチモーダルでトランスフォーマーを訓練し、様々な形式のデータを扱う最先端のモデルGeminiを開発しました。Gemini(のUltraモデル)は、MMLU(多領域の学術ベンチマーク)で90.04%の正確さを達成し、GPT-4を含むすべての既存モデルを上回る性能を発揮しています。
本記事の関連研究:Microsoftの研究者ら、比較的小さなサイズでもタスクによってはOpenAIのGPT-4を凌駕する言語モデル『Orca2』を開発
『Gemini』の特徴
Geminiには、以下の特徴があります。
3つのサイズがある
Geminiには、用途に応じて使い分けるための3種類の大きさが用意されています。
Ultra:非常に複雑なタスクに幅広く対応する目的において最先端の性能を示すモデル
Pro:コストと遅延の観点から最適化された性能を持ち、広範囲のタスクにおいて強力な推論能力とマルチモーダル能力を示すモデル
Nano:デバイス上でのアプリケーションに向けて設計された、最も効率的なモデル
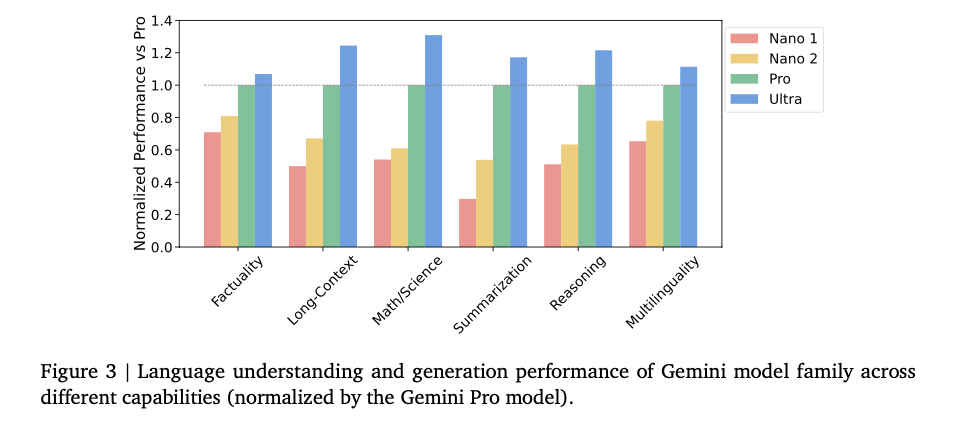
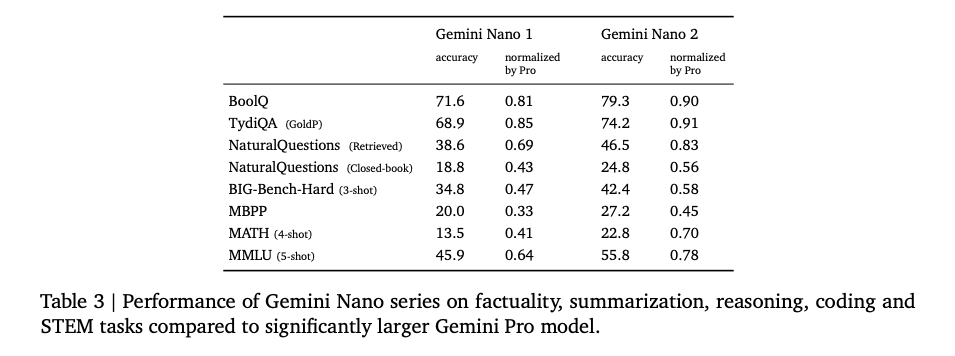
Ultraモデルは、ほとんどのカテゴリでProモデルを上回っており、推論と多言語性のタスクで特に顕著です。これらの情報から、特定のタスクに最適化された小さなモデル(Nanoシリーズ)と、より広範な応用が可能な大きなモデル(ProやUltra)の性能を比較し、実際の用途に応じて最適なモデルの選択することが求められます。
なお、NanoにはNano 1とNano 2があり、微量な性能の違いを示しています。
32のベンチマークのうち30で最先端の性能
Gemini Ultraは、自然言語ドメインで複数のベンチマークにおいて最高の水準に到達しているとの評価結果が報告されています。代表的なものとして、MMLUテストベンチマークで90.0%のスコアを達成し、人間の専門家のパフォーマンスを上回りました。
マルチモーダルのベンチマークでは20個全てで最先端
また、画像理解、ビデオ理解、音声理解のベンチマークで、タスク固有の修正やチューニングなしで最高の水準に到達しています。マルチモーダルモデルとしての最先端に位置する格好になります。

本記事の関連研究:日常能力を試すテスト『GAIA』正答率、人間92%に対してGPT-4は15% 一般的なニーズに応えるAI開発の指針に
Geminiができること
Geminiには以下の主な機能があります。

