
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
画像分析機能を持つ新しいオープンソースの大規模言語モデル(LLM)「LLaVA-1.5」が登場しました。このモデルは、ウィスコンシン大学とMicrosoftによって開発され、多くの業界と研究者に進展をもたらす可能性があります。
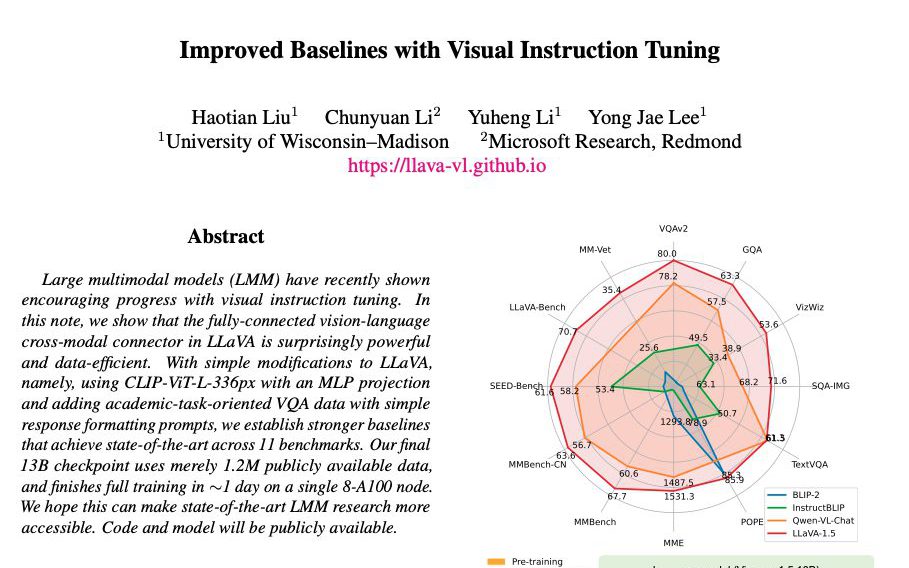
LLaVA-1.5は、GPT-4(V)の競合的なモデルで、視覚と言語の理解において優れたパフォーマンスを発揮します。LLaVA-1.5のデモは公開されており、手持ちの画像を分析させることができます。
参照論文情報
- タイトル:Improved Baselines with Visual Instruction Tuning
- 著者:Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
- 所属:University of Wisconsin–Madison, Microsoft Research, Redmond
- URL:https://doi.org/10.48550/arXiv.2310.03744
- プロジェクトページ:https://llava-vl.github.io/
- コード:https://github.com/haotian-liu/LLaVA
- デモ:
・https://llava.hliu.cc/
・https://huggingface.co/spaces/badayvedat/LLaVA - データセット:https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
- モデル:https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md
関連研究(続きは記事末尾にあります)
■OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化
■Microsoftの画像セグメンテーション新技術「SEEM(Segment Everything Everywhere Model)」の凄さ、Meta AIのSAMとの違い
従来の課題
視覚情報の処理能力不足
従来のLLMは、言語タスクに対する能力は優れていましたが、多モーダル(視覚と言語)のアップデートはあまり行われていませんでした。要するに、視覚的な情報を処理する能力には限界がありました。
高性能な画像分析LLMの需要
多くの開発者や研究者が高性能な画像分析LLMを求めていましたが、これまでのところそのようなモデルは一般に提供されていませんでした。
これらの課題を解決するために、LLaVA-1.5が開発されました。このモデルは、視覚エンコーダと大規模言語モデルを組み合わせて、一般的な視覚と言語の理解を目的としています。
LLaVA-1.5の特徴
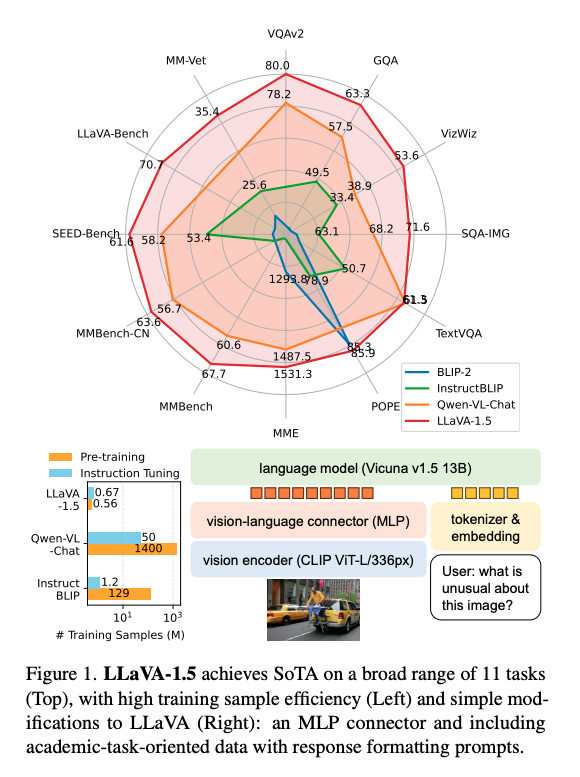
マルチモーダルな能力
LLaVA-1.5は、画像分析とテキスト処理機能を統合しています。画像内のオブジェクトを認識し、そのオブジェクトに関するテキスト説明を生成することができます。
GPT-4との連携
LLaVA-1.5は、GPT-4の強力なテキスト生成エンジンを活用しています。GPT-4を使用して合成データを生成することで、高度なテキスト生成と解析が可能になっています。GPT-4との連携により、より複雑な問題解決も手軽に行えます。
高度な処理能力
LLaVA-1.5は、未見の画像や新しい指示に対しても、GPT-4と同様に高度な処理が可能です。多様なタスクでの適用性を高めており、リアルタイムでの画像解析や自然言語処理タスクにおいて、能力を発揮します。
科学的な質問への対応
GPT-4とのシナジーにより、LLaVA-1.5は科学的な質問や複雑な問題にも高度に対応しています。研究者や専門家が専門的な質問を投げかけた場合でも、精度高く回答することが可能です。
オープンソースの提供
LLaVA-1.5はオープンソースで公開されており、モデルとコード、データセットも含まれています。研究者や開発者が容易にアクセスし、独自の研究や開発に利用することができます。また、コミュニティによる継続的な改善と拡張が期待されます。
LLaVA-1.5の性能

GPT-4との比較
LLaVA-1.5は、GPT-4(ただしGPT-4Vではなくtext onlyのモデル)と比較して85.1%の相対スコアを達成しています。LLaVA-1.5がGPT-4と同等の高い性能を持っていることを示しています。
科学的な質問への対応
科学的な質問に対して、LLaVA-1.5は単体でも90.92%のスコアを達成しています。これは、特定の専門的な問題に対して、GPT-4とのシナジーを外しても高い性能を発揮することを意味します。
ベンチマークテストの結果
LLaVA-1.5は11のベンチマークで最先端(SoTA)のパフォーマンスを達成しています。これにより、多様なタスクと環境での高い適用性が確認されています。
LLaVAのバージョンやライセンス

LLaVA-1.5とLLaVA-v1の選択
LLaVA-1.5とLLaVA-v1のどちらを使用するかは、目的に応じて選択が可能です。特定のタスクや目標に対してどちらがより適しているかを考慮する必要があります。
性能面での比較
基本的には、LLaVA-1.5がLLaVA-v1よりも高性能であるとされています。LLaVA-1.5が多くのベンチマークで最先端の性能を達成しているためです。
ライセンスについて
モデルの使用にはライセンスに準拠する必要があります。商用利用や研究目的での使用に際して、特定の条件や制限がある場合があるためです。
考察
活用の可能性
LLaVAシリーズは、その高度な画像分析とテキスト処理能力により、多様な産業や研究での活用が期待されます。オープンソースとして公開されているため、多くの開発者が参入し、継続的な改善が見込まれます。
参入障壁とコスト
一方で、LLaVA-1.5のような高性能モデルは計算コストが高く、参入障壁となっています。小規模な研究機関やスタートアップにとっては、このコストは無視できない問題です。
データと倫理的課題
さらに、データの偏りやバイアス、プライバシーに関するリスクも存在します。これらのリスクはLLaVAに特有なものではなく、画像分析機能を備えるモデル全てに伴うものだと言えます。いずれにせよ、十分な検証と対策が必要であり、今後の研究や開発での重要な焦点となるでしょう。

