
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
RAGを効率化する新しいフレームワーク「FIT-RAG」が提案されました。FIT-RAGでは、不必要な拡張を避け、トークン数をできる限り削減します。
実験により、様々な分野で幅広く応用できる可能性が示されました。

参照論文情報
- タイトル:FIT-RAG: Black-Box RAG with Factual Information and Token Reduction
- 機関:Zhejiang University, Zhejiang Gongshang University
- 著者:Yuren Mao, Xuemei Dong, Wenyi Xu, Yunjun Gao, Bin Wei, Ying Zhang
背景
最近のLLMは、GPT-4に代表されるように、人間に近い洗練された文章生成能力を持っています。しかし、LLMのパラメータに保存されている知識が古くなったり、そもそも不完全だったりする可能性もあります。知識を更新する手段としてファインチューニングもありますが、頻繁に実行するのは現実的ではありません。
この問題に対処する有望なアプローチが、検索データを付加する「RAG」です。RAGは、LLMの事前知識だけに頼るのではなく、大規模コーパスやデータベースを活用します。(参考:LLMのRAG(外部知識検索による強化)をまとめた調査報告)
従来のRAGシステムの理論は、検索器と生成モデルの両方を調整し、下流のタスクに適応させるのが一般的です。しかし、多くの高性能LLMはAPIを通じてのみアクセス可能で、ファインチューニングができません。
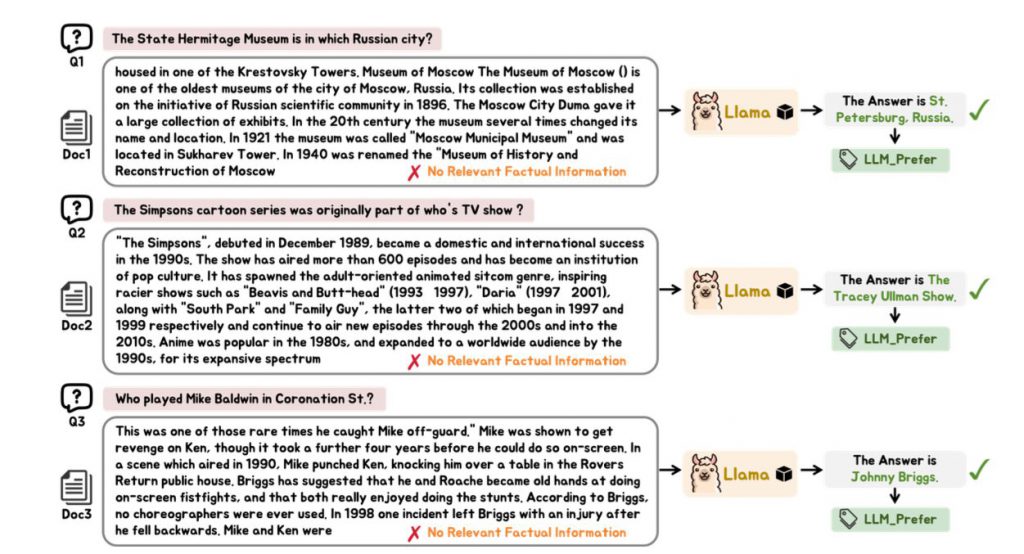
そこで、ブラックボックスLLMをRAGで拡張する「ブラックボックスRAG」が注目されています。LLMの好みに基づいて検索器をファインチューニングし、検索したドキュメントを入力に連結するものです。
しかし、まだ問題があります。検索でLLMの好みのみを考慮すると、事実情報が無視され、RAGの効果が低下します。例えば検索されたドキュメント自体、実際には役立つ事実情報を含んでいない場合があります。不必要なドキュメントで検索器を報酬付けすると、検索器を誤った方向に導いてしまいます。
また、検索したすべてのドキュメントを入力すると、大量の不必要なトークンが生成され、RAGの効率が損なわれることになります。
今回研究者らが解決したいと考えたのは上記の問題です。

