
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
LLMは知識が不足しているときに不正確な出力をしてしまうことがあります。そして知識を足すために検索を活用する手法(RAG)では、「検索結果の正確性」が鍵となります。
そこでGoogleなどの研究者らは今回、モデルが検索した結果の信頼性を評価する手法を提案しています。もし不正確だと思われる場合には補完することで、より正確な文章生成を実現する仕組みになっています。
研究者らが行った評価実験により、本手法の性能が実証されています。
参照論文情報
- タイトル:Corrective Retrieval Augmented Generation
- 著者:Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, Zhen-Hua Ling
- 所属:University of Science and Technology of China, University of California, Google Research
背景
LLMは文章生成などを中心に様々なタスクで優れた能力を発揮しますが、誤った情報や知識を出力してしまう「ハルシネーション」という問題を抱えています。
そんな知識不足の問題に対処することを目的の一つとして、モデルが関連する情報を取り込む手法「RAG:Retrieval-Augmented Generation」が出現しました。Metaなどの研究者らによる2020年の考案に端を発するものです。
しかしRAGは有効な手段ではあるものの、取り込んだ文書が間違っていた場合、かえって誤りを助長するという課題があります。
最近の研究では、必要な時に必要な外部知識を取り込むなど、RAGの改善が進められています。これまで、「RAGをより便利に」「そもそも使うべきか」という点を中心に探求されてきました。
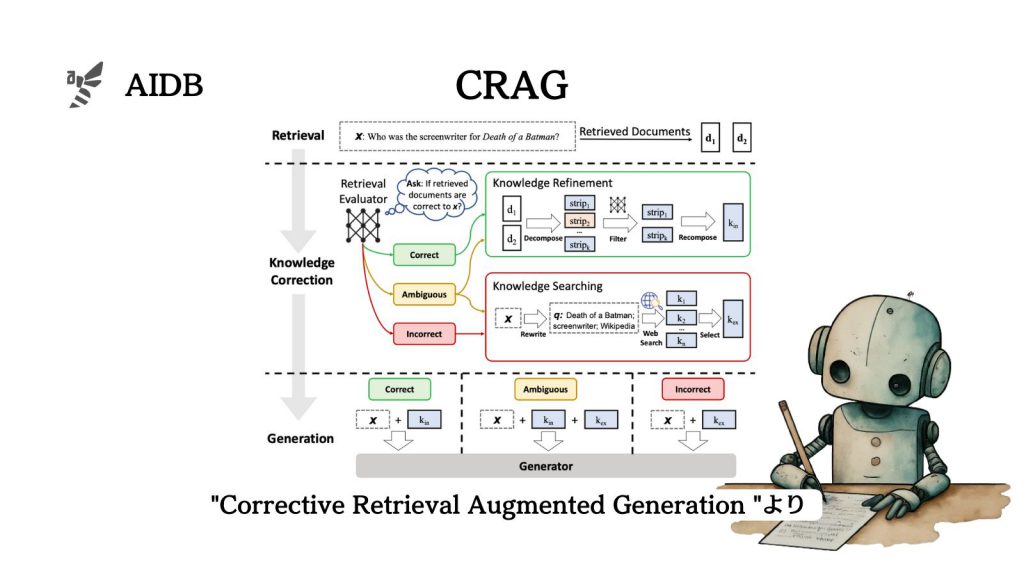
そして今回、Googleなどの研究者らは「取り込んだ情報が間違っている場合」に焦点を当て、従来の手法とは異なるアプローチ「修正型検索拡張生成(CRAG:Corrective Retrieval Augmented Generation)」を提案しています。
CRAGの利点は以下にようにまとめられるとのことです。
- 不正確な情報を排除し、信頼できる情報のみを使用する
- 取得された情報から重要な情報のみを抽出し、不要な部分を削除する
- 他のLLM手法と容易に統合することができ、さまざまなタスクに適用することができる
本記事では詳細を紹介します。

