
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
Google DeepMindとスタンフォード大学の研究者らは、LLMの長文における事実性を評価するための新しい手法を提案しました。
なお事実性とは、言語モデルの出力が事実と矛盾していないことを意味します。
研究者らは、数千の質問からなるプロンプトセットLongFactと、長文の応答を個別の事実に分解して各事実の正確性をGoogle検索を用いた多段階の推論プロセスで評価する『SAFE』を開発しました。
参照論文情報
- タイトル:Long-form factuality in large language models
- 機関:Google DeepMind, Stanford University
- 著者:Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, Quoc V. Le
背景
LLMは、まだ「事実と異なる内容を生成することがある」という問題が指摘されており、実社会で活用するためには、この”事実性”を高める必要があります。
長文(複数の段落で構成される文章)生成は短文生成に比べて、事実性の維持が特に難しいと考えられています。長文になるほど言及する事実の数が増える上に、文脈や論理の一貫性を保ちながら事実を述べる必要があるためです。
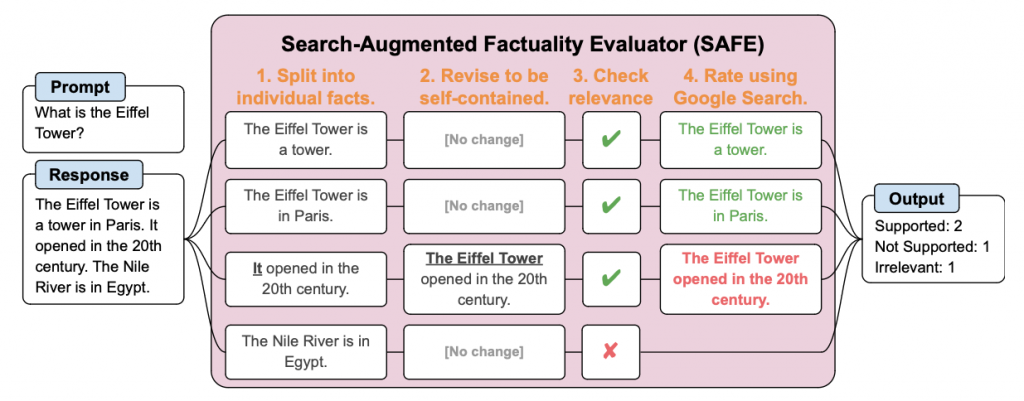
そこで重要になるのが、事実性評価です。従来はプロンプトセット(言語モデルに入力する質問や指示のデータセット)が使用されてきましたが、その多くは長文の回答の評価には適していませんでした。また、回答の評価も人手に頼ることが多く、コストと手間がかかるという問題がありました。
こうした背景から、研究者らはLLMの長文での事実性を評価するための新たな手法の構築に取り組みました。
以下で詳しく紹介します。

