
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
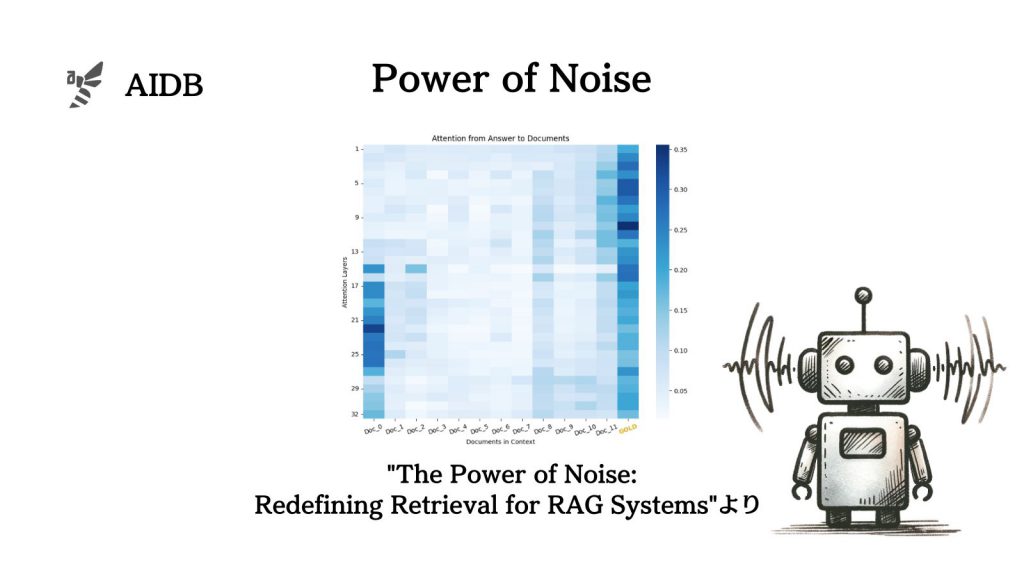
「無関係な」文書を混ぜたほうが出力精度が上がる可能性がRAGシステムの検証で示唆されました。
これまでになかった視点だと述べられています。
通常RAGシステムではRetrieverによってタスクに関係する文書を取り出してLLMにコンテキストとして与えるのが一般的です。しかし今回の実験では、あえて無関係な文書も「ノイズ」として乗せる実験を行なっています。
参照論文情報
- タイトル:The Power of Noise: Redefining Retrieval for RAG Systems
- 著者:Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, Fabrizio Silvestri
- 所属:Sapienza University of Rom, Technology Innovation Institute, University of Pisa
LLMとRAG
LLMは、長い文章や複雑な質問への対応にはまだ課題があると言われています。そこで注目されているのが、LLMと情報検索技術を融合したRAGシステムです。
RAGシステムは、LLMに情報を提供することで、より正確で文脈に沿ったテキスト生成を実現するものです。主に以下2つのコンポーネントから構成されます。
・Retriever:外部情報源からクエリに関連する情報を検索します。
・Generator:Retrieverから得られた情報に基づいて、文脈に沿ったテキストを生成します。今回はLLMのことを指します。
今回紹介する論文では、研究者らがLLMにおけるRAGシステムの新しい知見を得たことが報告されています。
結論から紹介すると、以下のことが分かりました。
1. 検索フェーズにおいて関連文書の追加は必ずしも有益とは限らない
2. コンテキストにノイズを含めることが精度向上に貢献する
この結論は、RAGシステム特有の情報処理メカニズムが従来の情報検索とは異なることを示唆するものです。
実験内容に詳しく触れる前に、LLMの発展の経緯やRAGの登場について少しおさらいします。

