
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
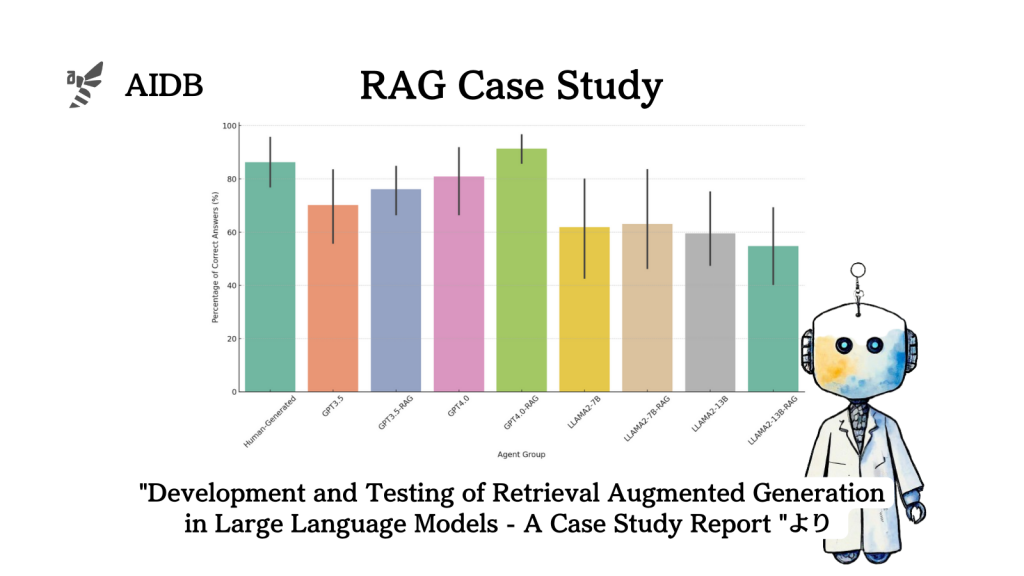
GPT-4にRAG(検索拡張生成)を適用することで、ある分野での臨床医学の問題において、人間の専門医師よりも高い精度が達成できたと報告されています。
適切なRAGシステム設計により、GPT-4単体よりも10%以上精度が向上し、人間医師よりも5%以上高いスコアを出しています。
参照論文情報
- タイトル:Development and Testing of Retrieval Augmented Generation in Large Language Models — A Case Study Report
- 著者:YuHe Ke, Liyuan Jin, Kabilan Elangovan, Hairil Rizal Abdullah, Nan Liu, Alex Tiong Heng Sia, Chai Rick Soh, Joshua Yi Min Tung, Jasmine Chiat Ling Ong, Daniel Shu Wei Ting
- 所属:Singapore General Hospital, Duke-NUS Medical School, Singapore National Eye Centre, Singapore Eye Research Institute, Singapore Health Services Artificial Intelligence Office, KK Women’s and Children’s Hospital
- URL:https://arxiv.org/abs/2402.01733
背景
LLMを実用する上では、事前知識が豊富でも現場に適した知識を持っている必要がある場合が多いです。例えば臨床評価や管理などにおいては、LLMの回答は実際の医療機関のガイドラインに基づいていなければいけません。
もしLLMから誤情報が出ると、安全性と倫理的な問題が起こります。LLMを臨床で使用する上でハルシネーションが発生すれば、手術当日の患者の不適合による手術キャンセル、医師の指示の誤り、術前指示への非遵守などは、経済的な損失も大きい問題に繋がってしまいます。
複雑で難しい問題にLLMを適用する際においては、RAGやファインチューニングで実用的なものにするアプローチが注目されています。
ファインチューニングは、既存のモデルを小規模なデータセットで再訓練する方法です。モデル出力の誤情報を軽減する有効な手段ですが、複雑な分野での正確な回答生成には大規模なデータセットや技術的な障壁があります。
一方、RAGは検索エンジンのように機能し、クエリに応じた関連するカスタマイズされたテキストデータを取得する革新的なアプローチです。RAGは特化した知識をLLMに統合するツールとして機能し、ヘルスケア分野など広範な専門知識が必要な場面での正確性を向上させます。
今回研究者らは、術前医学に特化したLLM-RAGパイプラインを開発し、患者の手術適合性を判断するLLM-RAGの精度を評価することを目的として実験を行いました。
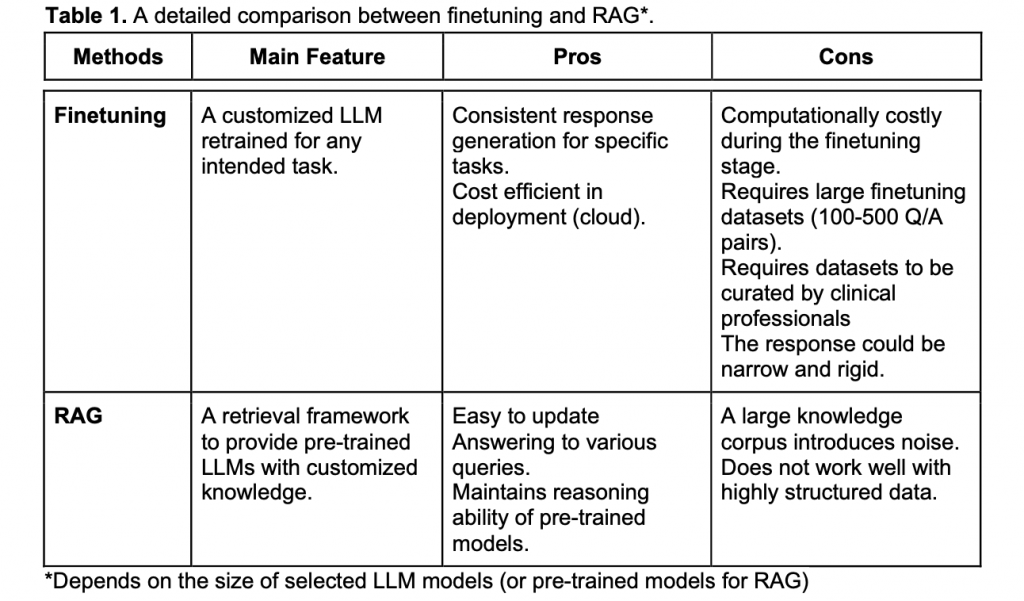
下記の表はファインチューニングとRAGの比較結果です。
方法論
以下はRAGフレームワークのための前処理とベクトル化・埋め込み、検索エージェントに関する一般的な知見と本研究での実際の作業内容を紹介しています。

