ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
大規模言語モデル(LLM)のサイズを効率的に小さくする技術『SLICEGPT』が発表されました。
この技術は、モデルの重要でない部分を剪定(切り取り)することで、計算資源とメモリの使用量を減らしながらも、高い性能を維持するものです。
実験では巨大なモデルを最大30%圧縮でき、生成タスクや様々なダウンストリームタスクにおいて、元のモデルの性能の90%以上を維持することが可能だと示されました。
参照論文情報
- 論文タイトル:SliceGPT: Compress Large Language Models by Deleting Rows and Columns
- URL:https://arxiv.org/abs/2401.15024
- 機関:ETH Zurich, Microsoft Research, Microsoft
- 著者:Saleh Ashkboos, Maximilian L. Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, James Hensman
- コード:https://github.com/microsoft/TransformerCompression
研究背景
LLMは、文章生成や翻訳など様々なタスクで高い能力を発揮しますが、サイズが巨大であるため、多くの計算資源とメモリを必要とするのが課題です。
そこで「基盤モデル」という考え方が注目されています。学習済みのLLMをベースに、それぞれのタスクに特化したモデルを構築することで、開発や計算のコストを削減する方法です。しかし、それでもまだ高額な費用がかかってしまうと言われています。複数の高性能コンピュータで何度もモデルを動かす度にコストは膨れ上がります。
そうした中、LLMの計算量を削減する「モデル圧縮」と呼ばれる技術が開発されています。モデル圧縮は、LLMのサイズを小さくすることで、必要な計算資源やメモリを減らすことができる技術です。
モデル圧縮の4つの方法
モデル圧縮には、大きく4つの方法があります。
- 知識蒸留:大きなモデルから小さなモデルへ知識を移転する方法
- テンソル分解:行列を複数の小さな行列に分解する方法
- 剪定:不要なパラメータを削除する方法
- 量子化:パラメータを低精度化する方法
今回、研究者らは3の剪定に着目し、これまでよりもさらに効果的な手法を開発することにしました。
剪定を改善したい
剪定自体はLLM以前から使用されてきた手法ですが、性能を維持するためには剪定後に再度微調整する必要があり、非常に手間がかかるという欠点がありました。
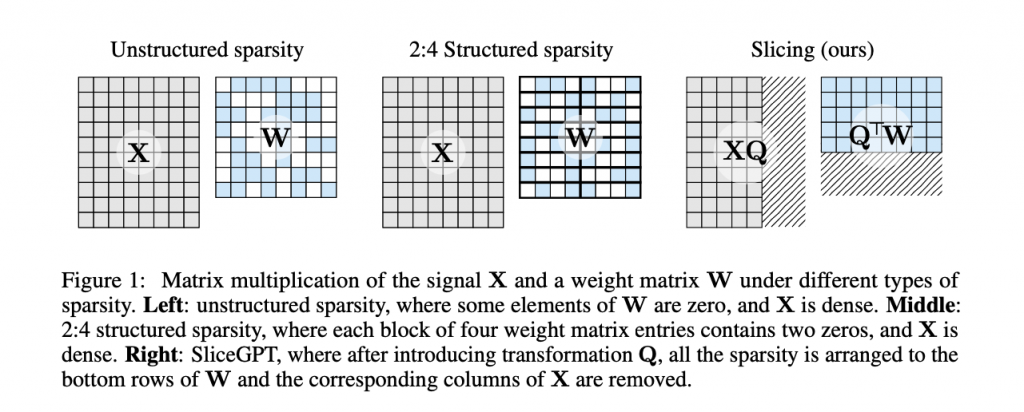
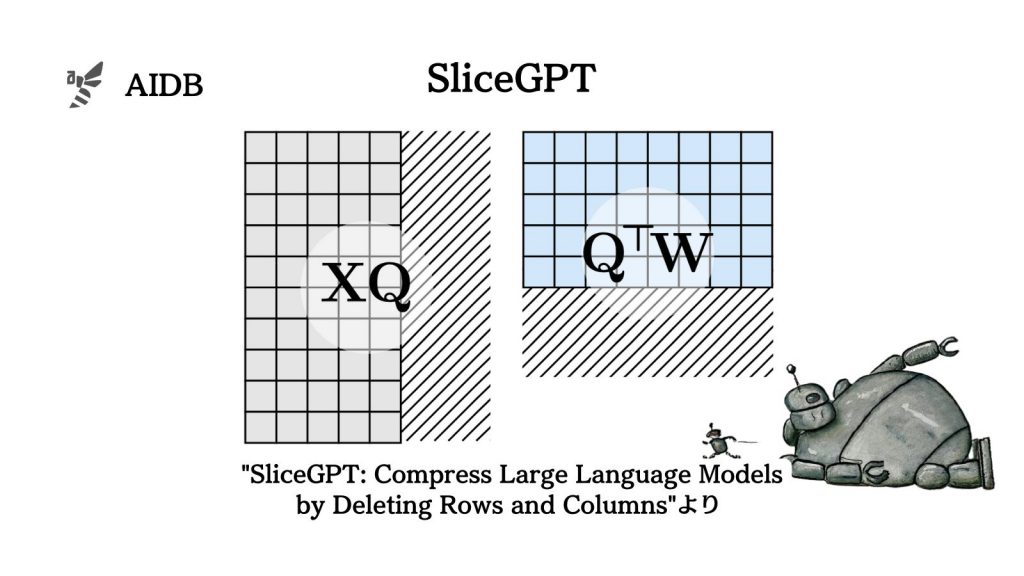
今回発表された「SliceGPT」は、従来の剪定法とは異なり、単一のGPUを使って数時間で巨大なモデルを圧縮でき、微調整を行わなくても下流タスクで高い性能を維持することができるものだと述べられています。