
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
小型の言語モデルを極めて大きいデータ量でトレーニングすると、類似サイズのモデルよりもシンプルに著しく優れた性能になったことが明らかにされました。
研究者らは1.1Bパラメータの「TinyLlama」を約3兆トークンで訓練して様々なタスク(常識推論や問題解決)で実験した結果を報告しています
本記事では研究の詳細を見ていきます。
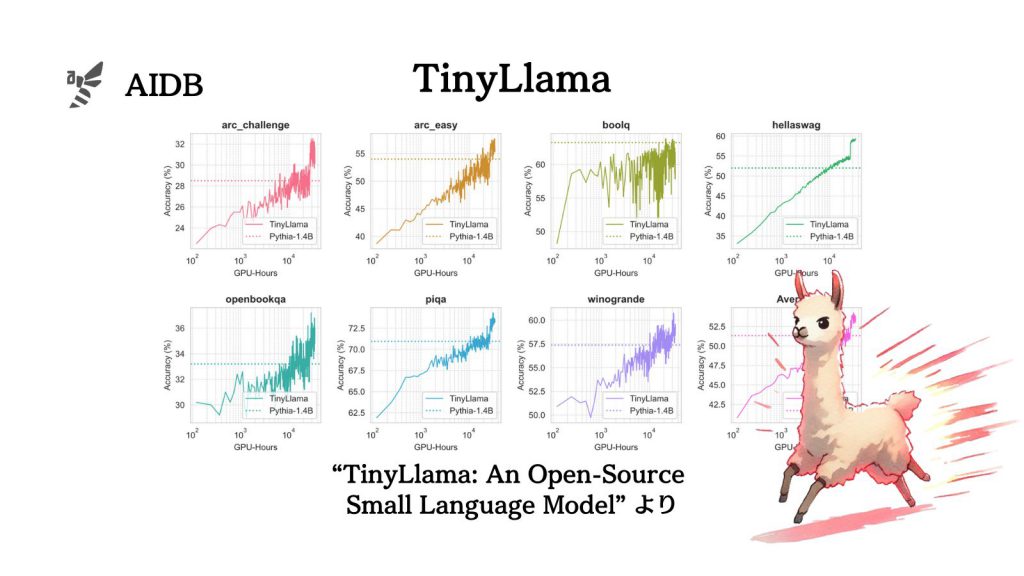
参照論文情報
- タイトル:TinyLlama: An Open-Source Small Language Model
- 著者:Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu
- 所属:StatNLP Research Group, Singapore University of Technology and Design
- URL:https://doi.org/10.48550/arXiv.2401.02385
- GitHub:https://github.com/jzhang38/TinyLlama
背景
自然言語処理の分野では、パラメータ数が多いモデルが注目されています。たとえば、GPT-3は175B(1750億)パラメータ、Llama-2は7B(70億)から70B(700億)パラメータです。
一般的には、パラメータ数が多いほどモデルの性能が高いと考えられています。しかし、パラメータ数が多いモデルにはいくつかデメリットがあります。
例えば、トレーニングや推論において多くの計算リソース(時間とコスト)を消費します。また、実行時に多くのメモリを必要とするため、高性能なハードウェアを持つことが条件になってしまいます。
おまけに、パラメータ数に見合ったトレーニングデータが用意できない場合には過学習が発生する恐れもあると言われています。
上記の背景から、パラメータ数が少なくても高いパフォーマンスを発揮するモデルの研究が重要になってきています。
そこで今回、そのような研究の最先端として登場したのがTinyLlamaです。研究者らは、比較的小さなモデルでも、十分なデータ量でトレーニングすれば高い性能が得られるのではないかと仮説を立てました。
本記事の関連研究:
- LLMのLlama-2を分解したところ、1057個のパーツから「抑制」に影響する部品が明らかに
- Microsoftの研究者ら、比較的小さなサイズでもタスクによってはOpenAIのGPT-4を凌駕する言語モデル『Orca2』を開発
- 消費者向けGPUでも高性能GPUに近いパフォーマンスでLLMを動かす手法「PowerInfer」
- オフラインで動作する様々なオープンソースLLMのインタフェース『GPT4All』が開発され公開
- 従来の小さなニューラルネットワークでも「メタ学習」でChatGPTを凌駕するほど高度な生成AIができるとの報告、Nature誌
- 「ChatGPTの1周年を記念して」、オープンソースLLMがChatGPTにどこまで追いついているか体系的調査報告
TinyLlamaはいかにして作られたか
訓練用データの用意
TinyLlamaの訓練データは、

