
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
消費者向けGPUでも高性能GPUに近いパフォーマンスでLLMを動かす手法「PowerInfer」を開発したと報告されています。 活発なニューロンだけGPUに割り当て、それ以外はCPUで処理するハイブリッド方式とのことです。
参照論文情報
- タイトル:PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
- 著者:Yixin Song, Zeyu Mi, Haotong Xie, Haibo Chen
- 所属:Shanghai Jiao Tong University
- URL:https://doi.org/10.48550/arXiv.2312.12456
- GitHub:https://github.com/SJTU-IPADS/PowerInfer
本記事の関連研究:Microsoftの研究者ら、比較的小さなサイズでもタスクによってはOpenAIのGPT-4を凌駕する言語モデル『Orca2』を開発
大規模言語モデル(LLM)運用上の課題
LLMを効率的に運用する上では課題があります。代表的な課題の一つは、モデルを動かすためには高性能なGPUが必要とされている点です。
LLMは、数十億から数百億のパラメータを持つことがあり、推論を実行するには相応の計算能力が要求されます。
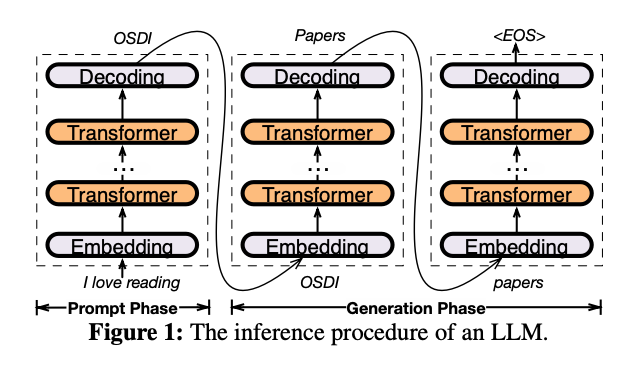
下の図はLLMの推論手順を示しています。ユーザーの入力(プロンプト)からモデルが出力を生成するまでの流れを図解しています。embedding、トランスフォーマー層を経て、デコーディングにより最終的なテキストが生成されます。
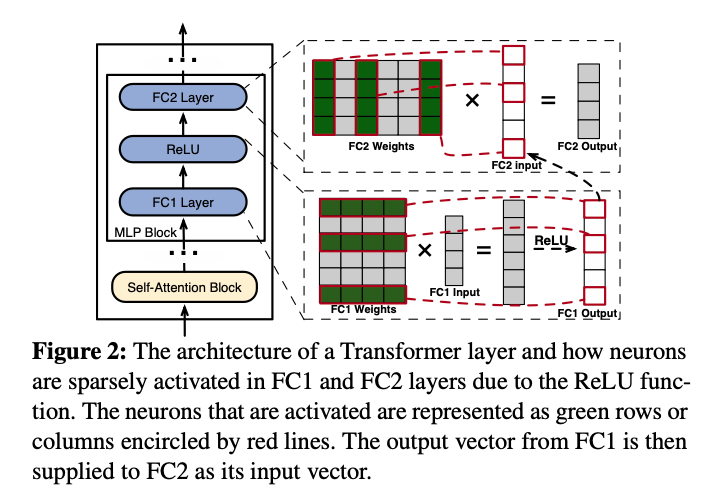
また、トランスフォーマー層のアーキテクチャと活性化パターンは以下のように示すことができます。活性化されるニューロンの挙動と、それらが次の層の入力としてどのように用いられるかを示しています。
上記のような仕組みに対応する機械的部品として、GPUが適しているというのが現状になります。
しかし、高性能なGPUは、高価です。例えばハイエンドな製品であるNVIDIAのA100(80GB)は現在数百万円もの高値で販売されており、需要の高まりから品薄な地域では定価よりも高額で取引されているといった事態も生じています。
研究者や開発者にとっては、高性能なGPUを仕入れるのは負担になっています。そしてコストが原因で、LLMの利用は特定の機関に限定されがちです。
というわけで、現状では一般的な消費者向けのコンピュータではLLMの運用は困難ですが、その実現を目指す新しいアプローチの開発が求められています。
そこで研究者らが目をつけたのがCPU-GPUハイブリッドの手法です。
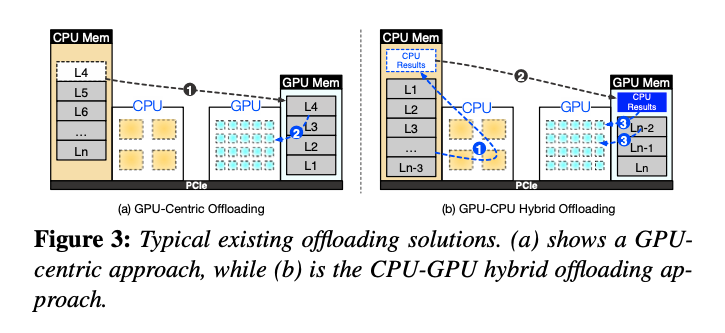
以下は、既存のオフローディング手法とCPU-GPUハイブリッドオフローディングアプローチを比較した図です。従来のGPU中心のオフローディングと、CPUとGPUのリソースを組み合わせたハイブリッドオフローディングの違いを示しています。今回発明されたPowerInferの設計理念を支えるコンセプトです。
本記事の関連研究:Appleが、LLMのパラメータを「SSDなどの外部フラッシュメモリに保存し」PCで効率的にモデルを使用する手法を開発
PowerInferの主要な特徴
研究者らは、LLMの推論を消費者向けGPUおよびCPUで効率的に行うためのシステムPowerInferを開発しました。このシステムのポイントは、以下の三つの主要な要素に集約されます。
メモリ使用量の削減
PowerInferは、ニューロンの活性化の偏りを利用して、頻繁に活性化されるニューロン(ホットニューロン)をGPUに、そうでないニューロン(コールドニューロン)をCPUに割り当てることで、GPUのメモリ使用量を大幅に削減します。
下のグラフは、LLMのモデル内でのニューロン活性分布例を示しています。ニューロンの活性化パターンは、リソース配分と計算効率に直結しています。
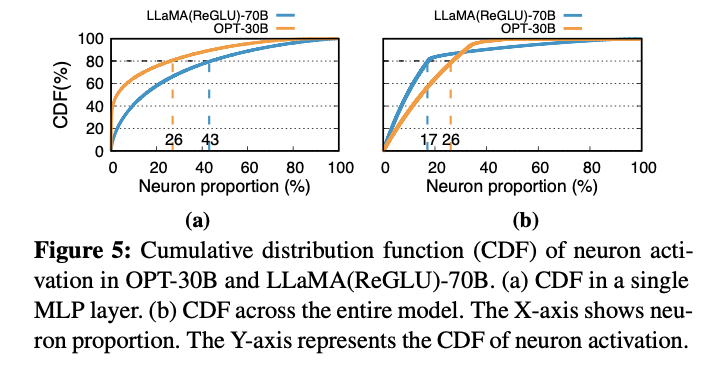
そして下のグラフは、OPT-30Bを例にして、10%と60%のニューロン重みがCPU上にある際の、ロード後実行と直接実行を比較しています。

推論処理速度の向上
このアプローチにより、GPUとCPUの双方の計算リソースが最適に活用され、推論処理の全体的な速度が向上します。
GPUとCPUのハイブリッド実行
PowerInferは、GPUとCPUのハイブリッド実行を実現しています。両方のプロセッサの長所を組み合わせ、全体的な推論性能を最大化するためにアーキテクチャが工夫されています。
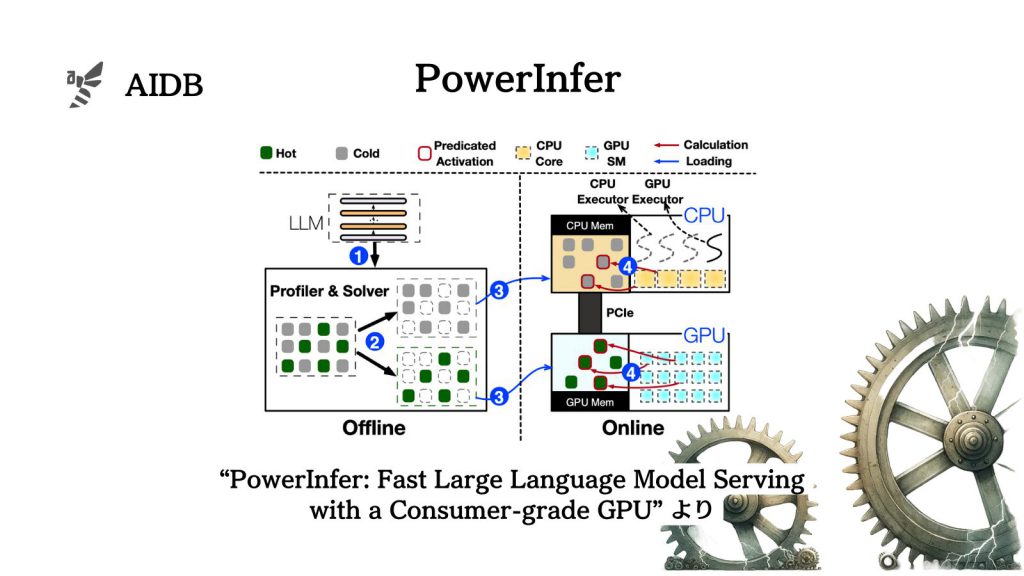
下図は、PowerInferのアーキテクチャ概観と推論ワークフローです。オフラインでのプロファイラーとソルバーの適用から、オンラインでの予測アクティベーション、CPUとGPUの役割分担までの流れを示しています。効率的な推論ワークフローが本アプローチの核心的な部分とされています。

なお、PowerInferは、現在ReLU(Rectified Linear Unit)やReGLU(Rectified Linear Unitの一種)など、特定の活性化関数を使用するモデルでのみ動作するように設計されています。
ReLUは非常にシンプルな計算で、ニューラルネットワークのトレーニングにおいて好ましい特性を持つため、多くのモデルでデフォルトの活性化関数として広く採用されています。
本記事の関連研究:LLMへの入力プロンプトを「意味を保持したまま」高度に圧縮する技術『LLMLingua』
実験内容
アプローチの有効性は、以下のような設定の実験で検証されました。

