
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
「LLMのアライメントは、実はプロンプトで少し指示を与えるだけでも実現できるのではないか?」と考えたワシントン大学とAI2の研究者らは、最低2行のプロンプトから実効性のある新しいアライメント手法『URIAL』を考案しました。
なおアライメントとは、AIが持つべき道徳的価値観や行動指針を定めて、人間社会の倫理に合わせるプロセスです。
本記事では、『URIAL』の手法や効果などを見ていきます。

参照論文情報
- タイトル:The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
- 著者:Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, Yejin Choi
- 所属:Allen Institute for Artificial Intelligence, University of Washington
- URL:https://doi.org/10.48550/arXiv.2312.01552
- GitHub:https://allenai.github.io/re-align/
本記事の関連研究:AGI(汎用人工知能)の原則6箇条とレベル5段階
研究の背景
従来のアライメント手法
これまで大規模言語モデル(LLM)のアライメント調整(人間の倫理観や道徳観に沿った行動を取るようにする手法)には、主に2つの方法が用いられていました。
1つ目は人間のフィードバックに基づく強化学習(RLHF)、2つ目は監督付きファインチューニング(SFT)です。
しかし、従来のアライメント手法は下記のような課題を抱えています。
(1)大量の計算リソースが必要
RLHFやSFTは膨大な計算能力を必要とし、コストが高くなる傾向があります。
(2)長期間にわたる学習が必要
長時間の学習プロセスを要するため、モデルの迅速な開発やイテレーションが困難になります。
(3)特定のタスクやデータセットに過度に適合
調整しすぎた結果、多様なシナリオでの一般化性能が低下することがあります。
研究者の疑問
研究者たちは「より簡単な方法で同じアライメントを実現できないか?」という疑問を持ちました。
そして、従来の手法はLLMの表面的な部分にのみ影響を及ぼすことに着目しました。そもそもLLMは人間の指示に正確に従うことは困難だとも認識していました。
そこで、無調整モデルで同様のアライメントを達成する方法として、プロンプトだけを使ってLLMのアライメントを改善する新しい手法「URIAL」の開発に着手しました。
なお下の画像は、アライメントを調整したLLMと調整していないLLMがどのように応答を生成するかの違いを分析しています。また、アライメント調整によってどのようなトークンが選ばれる傾向にあるかを示しています。

本記事の関連研究:大規模言語モデルのセーフガードを故意に突破する「脱獄プロンプト」とは
『URIAL』のメインアイデア
研究者らは、LLMの重みを調整することなくアライメントする手法を、『URIAL』(Untuned LLMs with Restyled In-context ALignment)と名付けました。
インコンテキスト学習(ICL)、つまりシステムプロンプトを用いて実現されます。
下の図は、『URIAL』で調整したLLMの応答例を示しています。

『URIAL』のポイント
(1)大規模データや複雑な学習を必要としない
大量のデータセットや時間を要する複雑な学習プロセスを必要としません。代わりに、わずか数行のインコンテキスト学習を使用します。
(2)インコンテキスト学習を用いた細かい調整
学習させたいテーマに関する具体的な質問とその答えの例をいくつかモデルに示します。すると似たような新しい質問に対しても、適切な応答を生成できるようになります。
(3)様々なタスクや応答スタイルに柔軟に適応
さまざまなタスクや応答スタイルに柔軟に対応できるように設計されています。ユーザーのニーズに合わせてモデルを調整することが可能です。
技術的フレームワーク
『URIAL』は、下記のように既存のアライメント手法と比較して、よりシンプルで効率的なアプローチです。
(1)ベースLLMの使用
まず、基礎となるLLMを選択します。性能や学習済みのデータ、使用環境要件、計算コストやリソースなどを考慮します。
(2)特定のプロンプトの導入
次に、モデルにプロンプトで特定の指示や例を与えます。特定のタイプの応答やスタイルを教えるために必要なだけの簡単な文章や質問です。
(3)インコンテキスト学習の活用
モデルは、与えられたプロンプトを元に、そのスタイルや内容に合わせた応答を学びます。
なお、「従来の手法であるRLHFやSFTはLLMの表面的な部分しか改善していないのではないか」と研究者らが考えたのには背景があります。
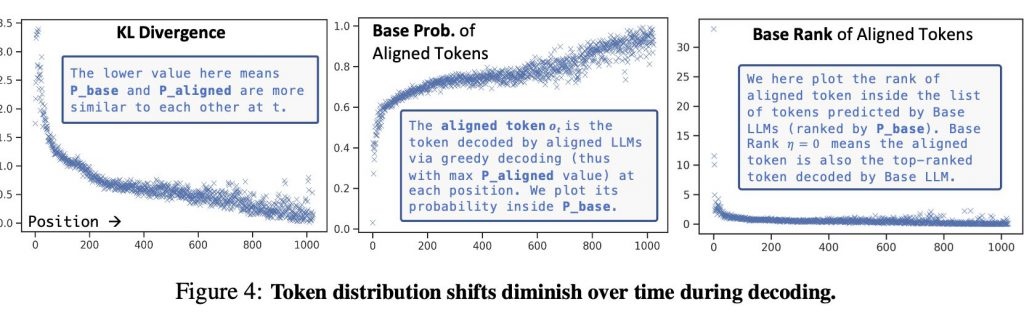
ベースとなるLLMと調整済みLLMの間のトークン分布のシフトに関する詳細な分析を行った結果、アライメントがトークン選択のわずかな部分(スタイルや安全に関する方針など)にのみ主に影響を与えると考察されたのです。
下の図は、異なるLLMの間でトークン分布の変化を示しており、アライメント調整前後でトークンの選択がどのように変わるかを比較しています。

また下のグラフは、言語モデルのアライメント調整によるトークンの分布の変化を数値的に分析した結果を示しています。
本記事の関連研究:現時点でのLLMに対する網羅的な評価分析が行われました。
実験と結果
実験内容
『URIAL』の効果を検証するため、研究者たちは様々なLLMに対して、

