
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
Mistral AIから、最新のモデルであるMixtral 8x7Bについての論文が公開されました。
タスクに応じて専門家を選ぶ仕組みによって、大きなパラメータでも計算コストを効率よくするのが特徴とのことです。
Mixtral 8x7Bは、Llama 2 70BやGPT-3.5に匹敵あるいは上回る性能を示すとされています。また、商用利用も可能です。
参照論文情報
- タイトル:Mixtral of Experts
- 著者:Albert Q. Jiang et al. (多数)
- 所属:Mistral AI
- URL:https://doi.org/10.48550/arXiv.2401.04088
- GitHub:https://github.com/mistralai/mistral-src
- プロジェクトページ:https://mistral.ai/news/mixtral-of-experts/
Mixtral 8x7B登場
新たな大規模言語モデル『Mixtral 8x7B』が公開されました。このモデルは言うなれば「なんでもできる」とされています。8人の専門家が、与えられたタスクを手分けしてこなすのが特徴です。また、日本語にも対応しています。
下の図はMixtralのMixture of Experts Layer(専門家レイヤーの混合部分)の構造を示しています。それぞれ異なる特徴を持つ8つのexpert networkの中から、入力されたtokenに応じて、2つ選ばれます。
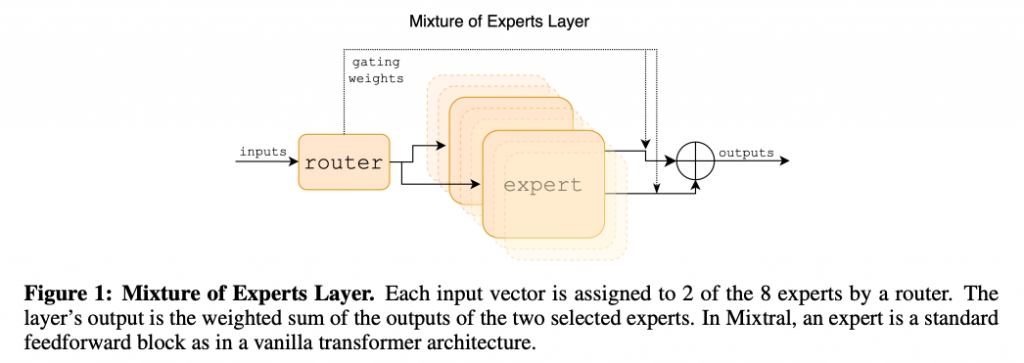
研究者らは、Mixtralは簡単なタスクだけでなく複雑なタスクもこなし、数学やプログラムなども対象としていると述べています。また大量のテキストを記憶できるとのことです。
以下にアーキテクチャの特徴とメリットを簡単にまとめます。
アーキテクチャの特徴
- 8人の専門家がチームを組んで、仕事を分担して行う
- 世界中の言葉を理解でき、難しい計算やプログラムの作成も得意
- 1つのGPUだけでなく、複数のCPUを使って仕事をこなす
- 仕事量を均等に分散して、誰もがパンクしないよう配慮している
この仕組みのメリット
- 1人1人の負担が減るため、仕事が効率的に進む
- 専門家の得意分野が異なるため、広範なタスクで精度の高い結果が得られる
- 複数のコンピュータで処理するため、大がかりな仕事も高速に処理できる
下記の表はモデルの主要なパラメータをまとめて表示しています。
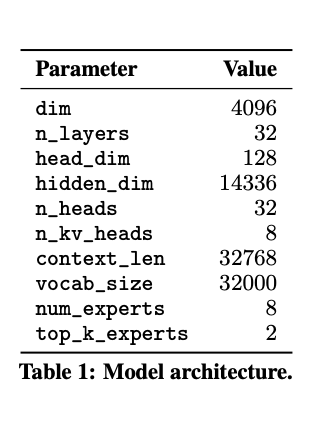
非常に大きな次元数とレイヤー数を持っていることがわかります。なお次元数が大きいのは、モデルがよりリッチな特徴表現を学習できることを意味しており、またレイヤー数が多いということは、モデルがより多くの抽象化レベルで情報を処理できることを意味します。
以下ではMixtralの性能を細かく評価した実験の結果や、情報処理の特徴などを紹介します。
Mixtralの実験結果
研究者らはMixtralの性能を評価するために、

