
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
Appleの研究者らは、LLMのパラメータをSSDなどの外部フラッシュメモリに保存し、接続したPCなどで読み込み使用する手法を開発しました。
本記事では論文を詳しく見ていきます。
参照論文情報
- タイトル:LLM in a flash: Efficient Large Language Model Inference with Limited Memory
- 著者:Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, Mehrdad Farajtabar
- 所属:Apple
- URL:https://arxiv.org/abs/2312.11514
本記事の関連研究:LLMへの入力プロンプトを「意味を保持したまま」高度に圧縮する技術『LLMLingua』
研究背景
LLMは高性能ですが、多くの計算能力とメモリ(情報を一時的に保存する部分)を必要とします。
そのためメモリ容量が限られているデバイスでは、モデルの運用が難しくなります。現在の方法では、モデル全体をDRAM(主要なメモリの一種)にロードする必要がありますが、DRAM次第でモデルサイズに制限が生じます。
そこでAppleの研究者らは、メモリ制限がある環境でもフラッシュメモリを活用してLLMを効率良く動かす新しい方法を模索しています。
本記事の関連研究:Microsoftの研究者ら、比較的小さなサイズでもタスクによってはOpenAIのGPT-4を凌駕する言語モデル『Orca2』を開発
手法の概要
この研究では、LLMの推論を効率化する新しい手法が提案されています。主な特徴は以下の通りです。
フラッシュメモリへのパラメータ格納
LLMのパラメータを外部フラッシュメモリに保存し、DRAMの容量制限を克服します。
DRAMへの動的転送
推論プロセス中に必要に応じて、フラッシュメモリからDRAMへパラメータを動的に転送します。
データ転送量の削減
計算に必要なパラメータのみを転送することで、データ転送量を減らし、推論速度を向上させます。
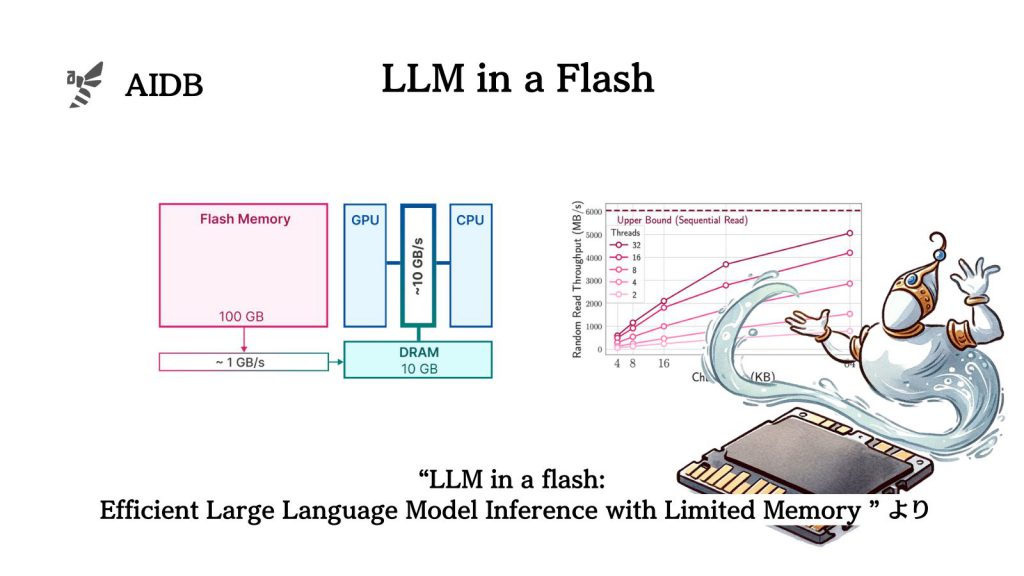
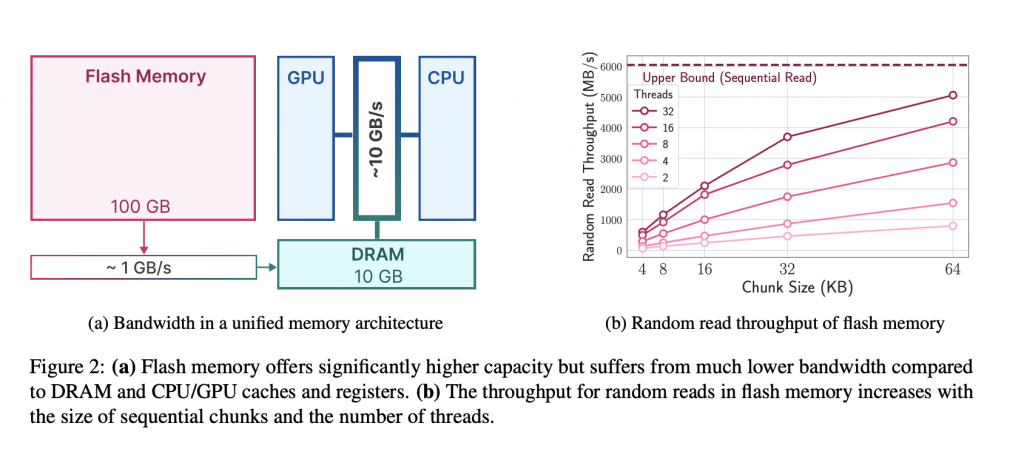
下の図は、フラッシュメモリからDRAMへのデータ転送速度と、フラッシュメモリ自体の読み込み速度がデータの塊(チャンク)の大きさや同時に作業を行うプロセス(スレッド)の数によってどのように変わるかを示しています。
フラッシュメモリは大容量でありながら、データの転送はDRAMより遅いですが、大きなデータブロックを一度に読み込むことで速度が向上します。この特性を利用するのが本研究のアイデアです。
本記事の関連研究:オフラインで動作する様々なオープンソースLLMのインタフェース『GPT4All』が開発され公開
技術の詳細
この研究で開発された技術の特徴は次の通りです。
計算済みのトークン活性化の再利用
(Windowing(Window化))
本アプローチは、計算されたトークンの活性化(処理結果)を再利用してデータ転送を削減します。
要するに過去のトークンデータを保持し、必要に応じて活用することで、新たなデータ転送の回数を減らし、効率を高めます。
フラッシュメモリの連続データアクセスの活用
(Row-Column Bundling)
また、フラッシュメモリの連続的なデータアクセスの強みを生かし、大きなデータチャンクを効率的に読み込むことを行っています。
データを一つの大きな塊として保存し、読み込むことで、データ読み込みの効率を上げるという内容です。
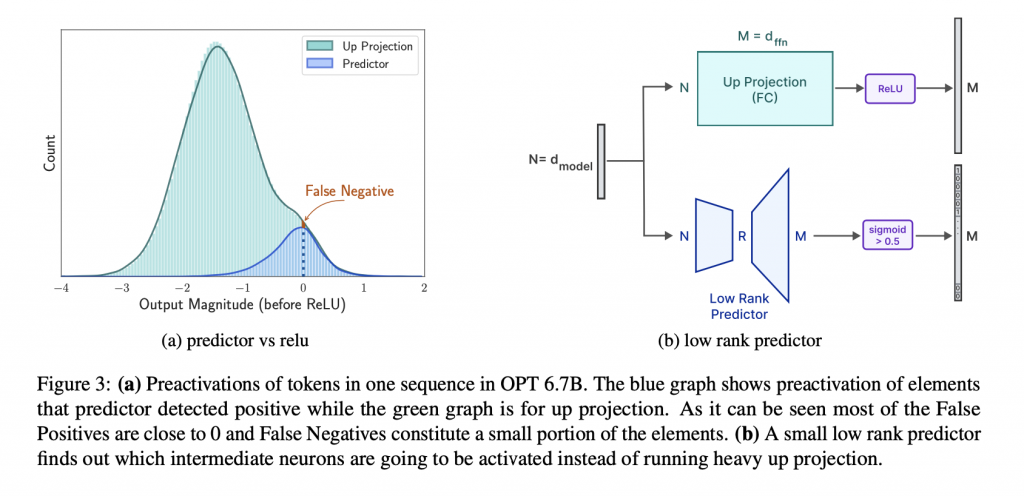
下のグラフでは、大規模言語モデルの一部として活動する中間ニューロンがどのように活性化するかを予測する低ランク予測器の効果を示しています。
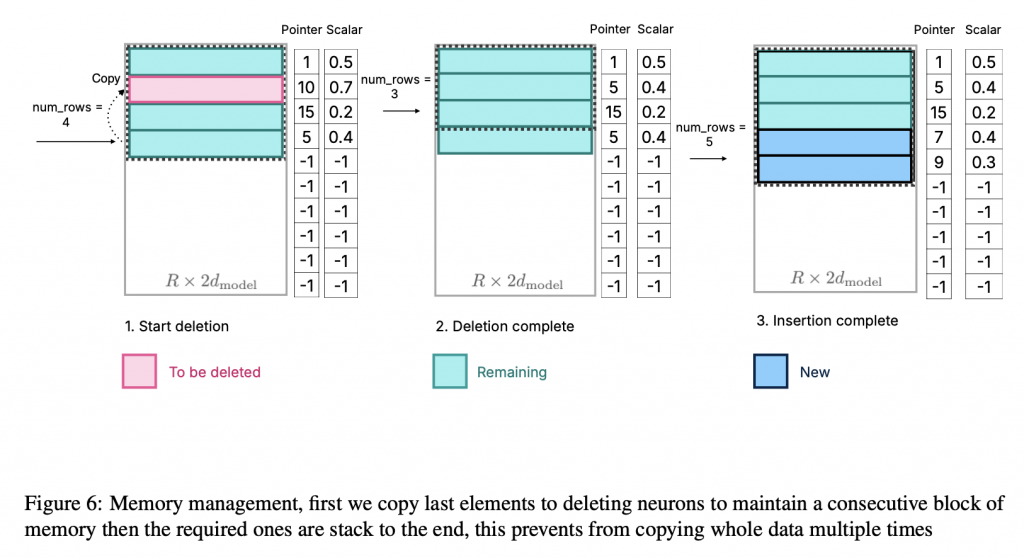
下の図はメモリ管理の工程を示しており、不要データの削除と新規データの追加を通じてメモリ効率を高めるプロセスを説明しています。使用済みのメモリ領域からデータを取り除き、新しい情報を効率的に追加することでメモリの連続性を維持し、無駄なデータコピーを防ぐことで全体の処理速度を改善します。
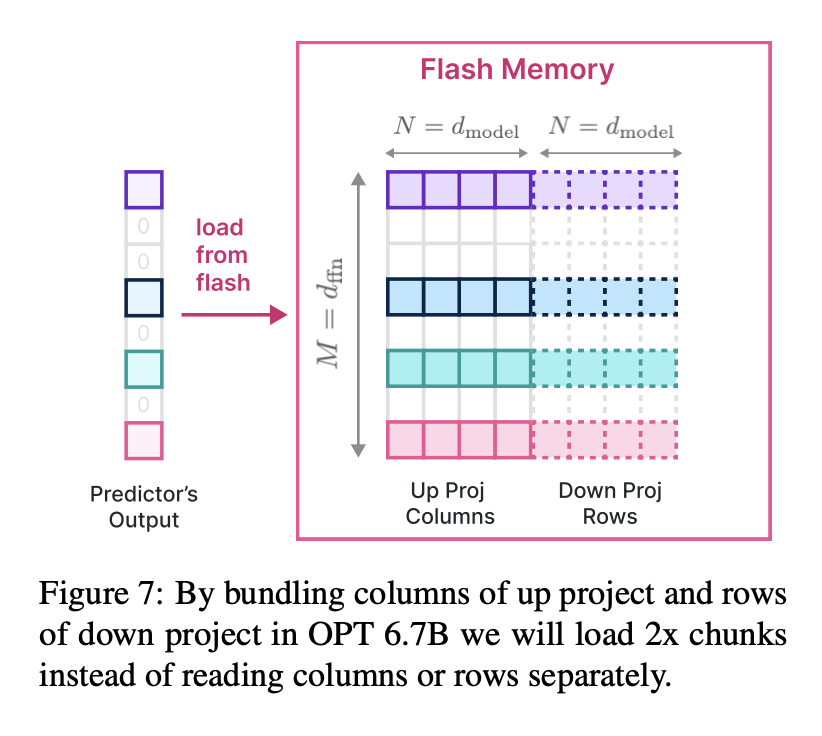
さらに下の図には、フラッシュメモリのデータを効率よく読み込むために、データの列と行をまとめて処理する方法が示されています。フラッシュメモリからの読み込み効率を2倍にすることが可能になります。
本記事の関連研究:従来の小さなニューラルネットワークでも「メタ学習」でChatGPTを凌駕するほど高度な生成AIができるとの報告、Nature誌
実験内容
実験は、

