
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事では、LLM研究全体の背景と現状、そして将来展望を網羅的に整理する調査論文をもとに、LLMの基礎を振り返ります。ここまで、代表的なモデル、モデル構築、使用法・拡張法、データセットについて深掘りしてきました。
第1回:大規模言語モデル(LLM)のこれまでとこれから① -代表的なモデル編-
第2回:大規模言語モデル(LLM)のこれまでとこれから② -モデル構築編-
第3回:大規模言語モデル(LLM)のこれまでとこれから③ -使用法・拡張法、データセット編-
今回は、本シリーズの最終章として、ベンチマーク別の優秀なモデルと将来展望について紹介します。
参照論文情報
- タイトル:Large Language Models: A Survey
- 著者:Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, Jianfeng Gao
- 所属:論文には所属機関が示されていないため各機関から有志の研究グループが結成されたことが推測されます。
- URL:https://doi.org/10.48550/arXiv.2402.06196
前回のおさらい
前回は、以下の項目に沿ってLLMの使用法・拡張法、データセットに触れました。
- LLMの不足
- LLMのプロンプトエンジニアリング
- 思考の連鎖(CoT)、思考の木(ToT)、自動プロンプトエンジニアリング(APE)など
- 外部知識を通じてLLMを拡張する手法RAG
- 外部ツールの使用
- LLMエージェント
- 基本タスクのデータセット
- 指示に従うためのデータセット
- 外部知識/ツールを使用した拡張のためのデータセット
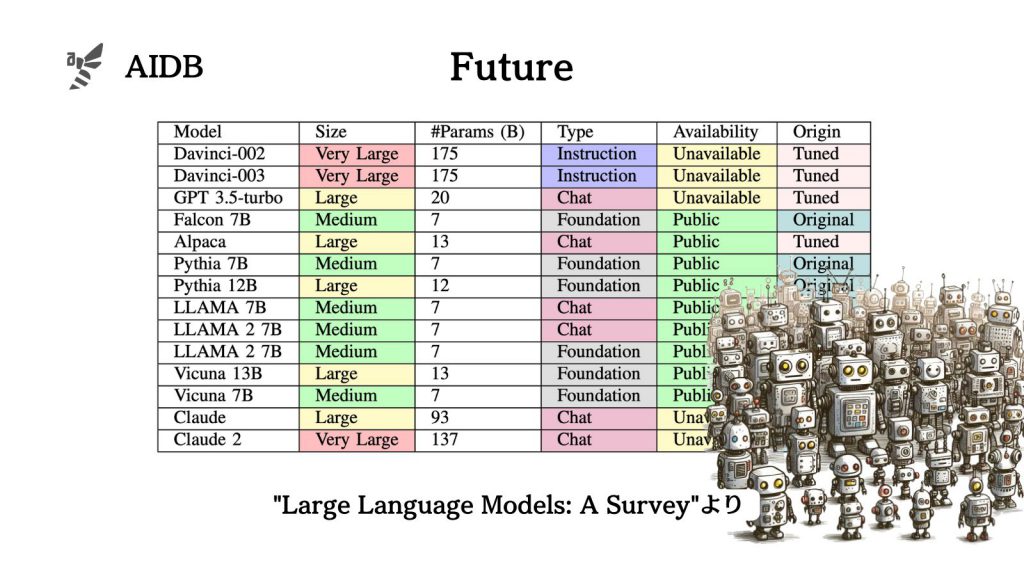
本記事では、さまざまなベンチマークごとの優秀なモデルと、将来展望にフォーカスします。
主要なLLMの各ベンチマークにおける性能
LLMを評価する代表的な評価指標と、データセットやベンチマークごとの各種LLMの性能を紹介します。

