
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事では、LLM研究全体の背景と現状、そして将来展望を網羅的に整理する調査論文をもとに、LLMの基礎を振り返ります。前回は、代表的なモデルについて深掘りしました。
前回の記事:大規模言語モデル(LLM)のこれまでとこれから① -代表的なモデル編-
今回は、モデルの構築について深掘りします。
参照論文情報
- タイトル:Large Language Models: A Survey
- 著者:Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, Jianfeng Gao
- 所属:論文には所属機関が示されていないため各機関から有志の研究グループが結成されたことが推測されます。
- URL:https://doi.org/10.48550/arXiv.2402.06196
前回のおさらい
前回は、LLMの登場に至るまでの経緯と代表的なモデルについて触れました。主に以下のような内容です。
- 初期のニューラル言語モデルが現代の高度なモデル(GPT、LLaMA、PaLMなど)に進化した
- トランスフォーマーモデルの採用が言語理解・生成能力の向上につながった
- 数十億のパラメータを持つモデルが出現し、精度が飛躍的に向上した
- LLMにおいては事前学習、微調整、および人間のフィードバックによる強化方法が注目されている
- 大規模なモデルになったことで、新たなタスクへの適応能力や指示に従う能力など、旧来には見られない能力が発現した
- オープンソースモデルが登場し、分野の進歩に貢献している
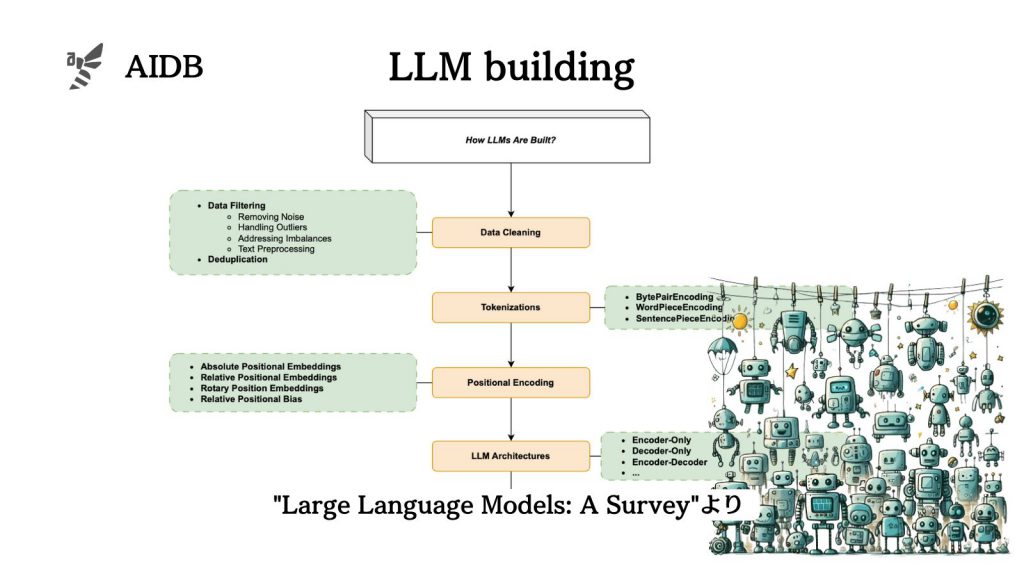
上記の続き(あるいは独立したコンテンツ)として、以下では「モデルの構築」に焦点を当てています。LLMに一般的に使用されている構造を再確認し、データ準備やトークン化、事前学習、命令文の調整、そしてアライメントまでのデータ処理やモデリング技術について説明します。フローで示すと、

