
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事では、LLM研究全体の背景と現状、そして将来展望を網羅的に整理する調査論文をもとに、LLMの基礎を振り返ります。
本調査論文は、GPT、LLaMA、PaLMなどの重要なLLMについて、その特性や限界をまとめています。また、LLMの構築と拡張に役立つ技術、訓練や評価のためのデータセット、そして評価指標についても整理しています。さらに主要なベンチマークでこれらのモデルのパフォーマンスを比較し、将来の研究の方向性について考察しています。
今回は、まずはLLMの登場に至るまでの流れと、代表的なモデルを網羅的におさらいします。なお次回は「LLMの構築方法」について触れていきます。
参照論文情報
- タイトル:Large Language Models: A Survey
- 著者:Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, Jianfeng Gao
- 所属:論文には所属機関が示されていないため各機関から有志の研究グループが結成されたことが推測されます。
- URL:https://doi.org/10.48550/arXiv.2402.06196
はじめに
言語モデルは今でこそ一般に広く知られていますが、実は1950年代に端を発する長年の研究テーマです。統計的言語モデル (SLM) から始まり、ニューラル言語モデル (NLM) や事前学習済み言語モデル (PLM) を経て、現在トランスフォーマーベースの大規模言語モデル (LLM) が大きく注目を集めています。
LLM は、数十億から数千億のパラメーターを持ち、Web規模のテキストデータで事前学習されています。従来のモデルと比較して、以下の点で優れています。
- 少ないデータで効率よく学習する
- 特定のタスクのみではなく汎用的な能力を発揮する
- 下記の新しい能力を発現している
- 推論時に提示された少数のサンプルから新しいタスクを学習する能力
- 明示的な例を使用することなく、指示に従って新しいタイプのタスクを実行する能力
- 複雑なタスクを中間推論ステップに分解して解決する能力
LLM は以下のような様々なタスクに適応します。
- 質問応答、要約、翻訳、文章生成
- プログラミング言語のコードを生成
- 画像や音声などのマルチモーダルデータとテキストデータを統合して処理
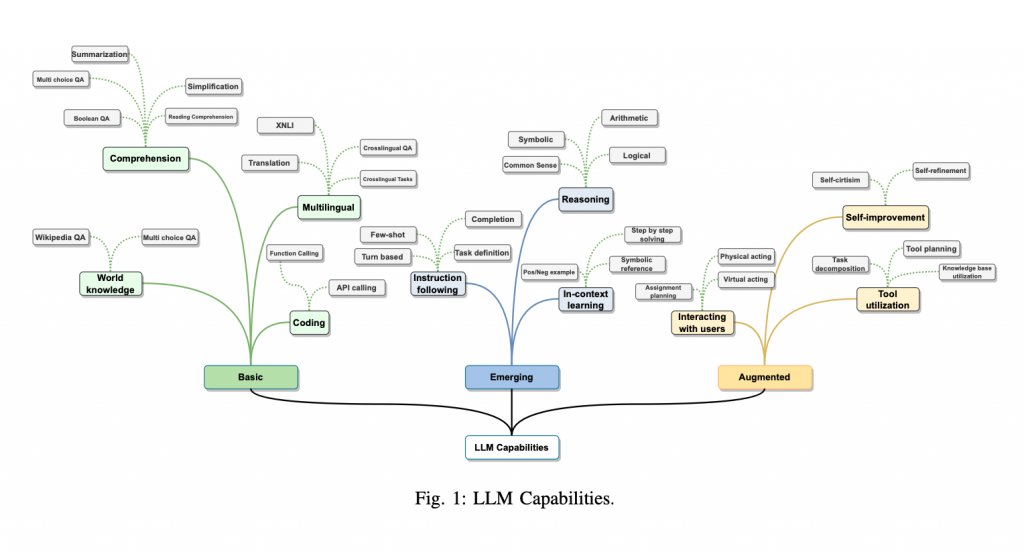
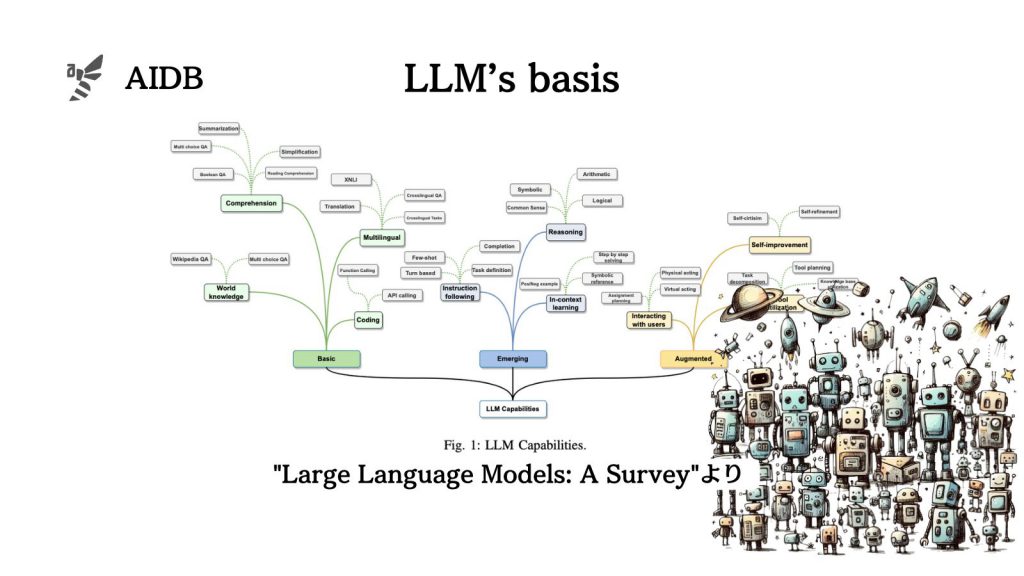
今回、研究者らはLLMのこれまでとこれからを以下のような観点で整理しました。
- 代表的なモデル
- 構築方法
- 使用方法と強化方法
- 主要なデータセット
- 代表的なLLMのタスク別パフォーマンス
- 今後の方向性
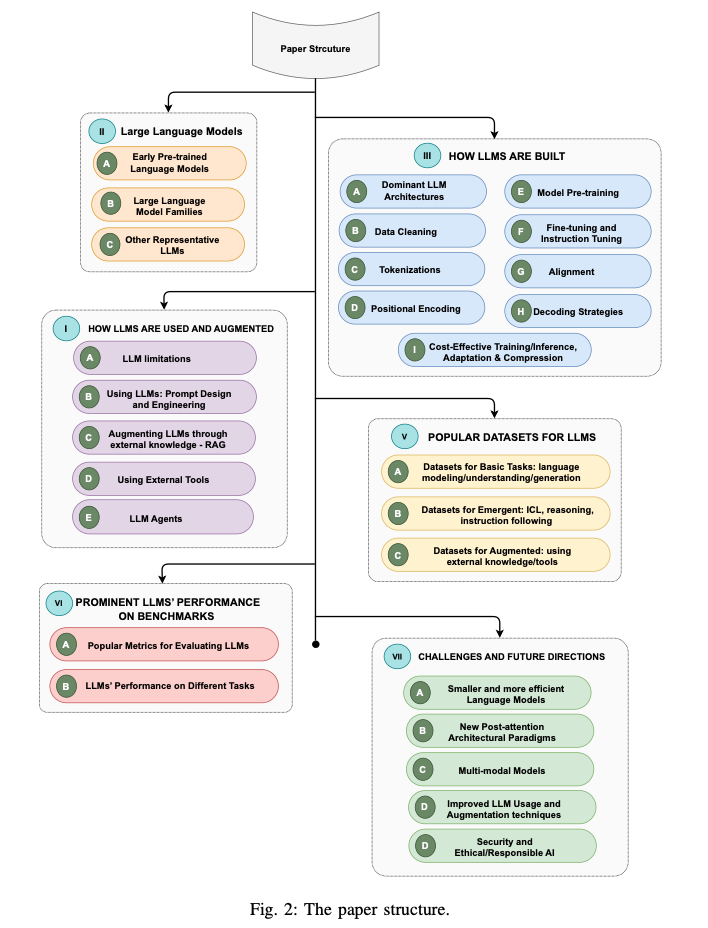
本記事では代表的なモデルに特化して調査結果を紹介します。
初期のニューラル言語モデル、各種事前学習モデル、そしてGPTファミリー、LLaMAファミリー、PaLMファミリー、その他の種類に分けてLLMを網羅的にまとめていきます。
まずは、

