かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事では、LLMの知識を狙い撃ちして編集する手法(Knowledge Editing:知識編集)について整理します。
知識編集はモデル全体を再学習させることない効率的なアプローチと言われており、信頼性の向上や、パーソナライズされたエージェントの開発に役立つとのことです。なお、有名な手法としてはLoRAなどが含まれます。
背景、知識編集の概要、3つのフェーズ、評価方法、今回行われた実験と結果、そして応用例について紹介します。

本記事の関連研究:
- ハーバード研究者などがLLMを創造的にすべく考案した、大喜利データセットでユーモアラスにチューニングする手法『LCoT』
- LLMにナレッジグラフ(知識グラフ)を連携させることで、タスク遂行能力を大幅に向上させるフレームワーク『Graph Neural Prompting(GNP)』
- LLMにベートーヴェンなど特定の人物の行動や感情を模倣させる、イタコのような技術『Character-LLM(キャラクターLLM)』
- 「わたしの話」を体系的に覚えてもらいながらLLMと会話する技術MemoChat登場
背景
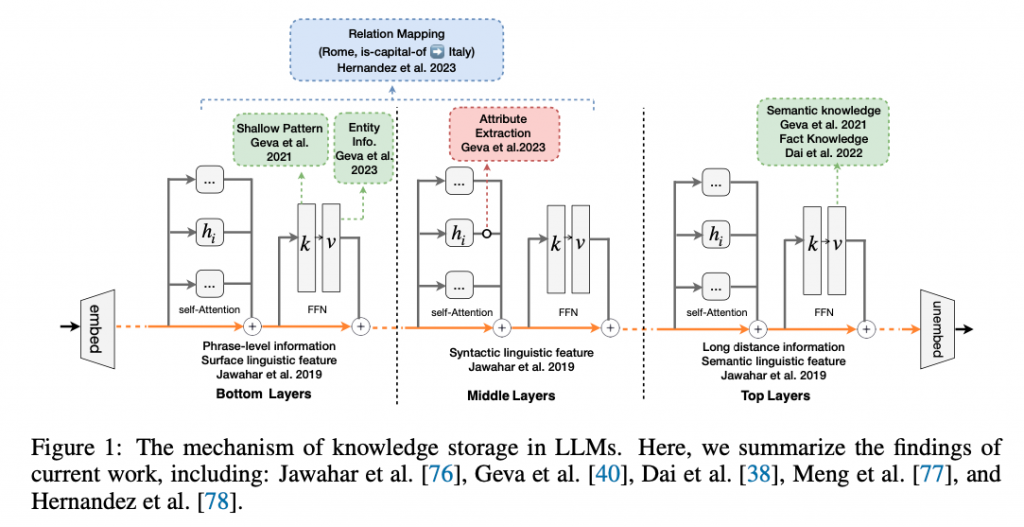
LLMは、さまざまな知識をパラメータ内に蓄えています。下の図は、LLMにおける知識の保存方法を図式化したものです。モデルが情報を処理し、さまざまなレベルで言語の特徴をエンコードする様子を示しています。
LLMには、時として誤りや古い情報を出力するといった問題があります。この問題に対処する最も一般的な方法は、RAG(外部データの参照)やファインチューニングです。
参考:LLMのRAG(外部知識検索による強化)をまとめた調査報告
しかし、RAGやファインチューニングにも課題があります。まず、外部のデータベースにいちいちアクセスするのも、場合によっては効率的とは言えません。また、ファインチューニングにはコストと時間がかかる上に、新しい知識を学ぶと古い知識を忘却するという問題も存在します。
そのためパラメータ効率の良いチューニング技術が必要とされています。
そこで「知識編集」という戦略に注目が集まっています。LLMの知識を直接編集し、より効率的に最適化する方法です。
以下で詳しく見ていきましょう。

