
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
Googleとスタンフォード大学の研究者らは、下流タスク(機械翻訳などの具体的なタスク)における大規模言語モデルのスケーリング則を調査しました。その結果、新しい知見がいくつか得られています。
スケーリング則とはモデルの学習データ量やサイズの増加によって性能がどう変化するのかを説明するものです。
本研究においてはファインチューニングに対する洞察やデータセットの選択と評価などに関する考え方なども紹介されており、事前学習におけるスケーリング則以外にも示唆に富む情報が含まれています。
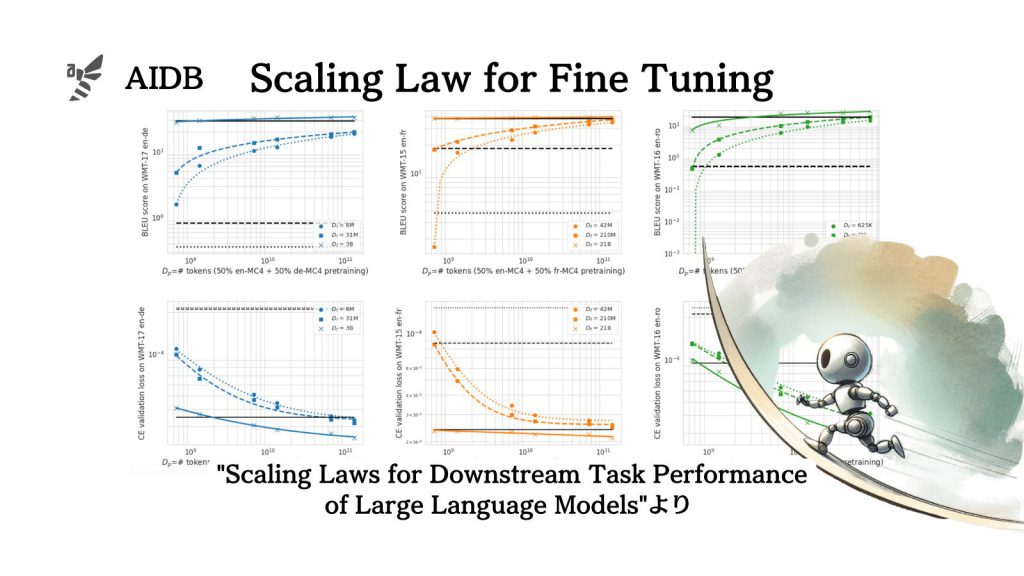
参照論文情報
- タイトル:Scaling Laws for Downstream Task Performance of Large Language Models
- 著者:Berivan Isik, Natalia Ponomareva, Hussein Hazimeh, Dimitris Paparas, Sergei Vassilvitskii, Sanmi Koyejo
- 所属:Stanford University, Google Research
- URL:https://doi.org/10.48550/arXiv.2402.04177
背景
LLMのモデル開発における設計指針(例:トレーニングデータの規模、アーキテクチャ)の材料として「スケーリング則」は重要視されているものの一つです。
スケーリング則とは、モデルのサイズやデータ量が増加するにつれて、そのパフォーマンスや効率がどのように変化するかを表す法則です。LLMにおけるスケーリング則では、モデルのパラメータ数、訓練データの量、計算資源が増加するにつれて一般的にモデルの性能は改善し、改善の度合いは次第に減少するなどのことが分かっています。
これまでの研究では、主に事前学習データと上流タスクのクロスエントロピー(予測と実際の分布との差異を測る尺度)などに対するスケーリング則に焦点が当てられてきました。しかし実用的にLLMを使う場合は、LLMは具体的な下流タスクに強くなるよう転移学習(下流タスク向けにファインチューニング)されることも多いです。
ここで、LLMにおける上流タスクとは言語理解などの基本性能を指し、下流タスクとは例えば機械翻訳などの細分化された具体的なタスクを意味します。
なお、事前学習データを増やせば上流下流ともにタスク性能が必ず上がるわけではなく、画像認識の分野では時には性能が下がる場面もあると報告されています。
なおファインチューニングのデータ量におけるスケーリング則も研究されてはいますが、十分には調べられていません。
そこでGoogleなどの研究者らは、下流タスク(機械翻訳)における事前学習データの規模とファインチューニング後のタスク性能の関係性を調査し、スケーリング則の知見を新しく得ることに成功しました。
下流タスクにおけるスケーリング則
研究者らは調査の結果、ファインチューニング後の下流タスクにおけるスケーリング則を、以下のようにまとめました。先に結論から整理します。

