
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
ペンシルベニア大学やNAVERの研究者らは、人間の教材にインスパイアされたカリキュラム学習によるチューニング手法によってLLMを賢くする手法を検証しています。
問題や難易度や認知負荷レベルを徐々に高めるような学習の仕方を用いると、従来のチューニング手法よりもLLMの性能が上がるとのことです。
本記事では背景、手法のポイント、実験と結果、そして展望と注意点について紹介します。
参照論文情報
- タイトル:Instruction Tuning with Human Curriculum
- 著者:Bruce W. Lee, Hyunsoo Cho, Kang Min Yoo
- 所属:ペンシルベニア大学, ソウル国立大学, NAVER Cloud
- URL:https://doi.org/10.48550/arXiv.2310.09518
なお上記論文公開のあとに、関連研究が別のグループから発表されました(下記)。下記はファインチューニングフェーズではなくコンテキスト内学習の工夫(プロンプトエンジニアリング) において人間のカリキュラム学習を模倣することの有効性を明らかにしています。
Jacob Russin et al., “Human Curriculum Effects Emerge with In-Context Learning in Neural Networks”, 2024/2/13, https://arxiv.org/abs/2402.08674
研究に至る背景
GPT-4のような優れたモデルは、用途の広さでも大きな注目を集めています。人間の指示に基づいて正確に動く能力も高く、開発時のチューニング手法(人間のフィードバックによる強化学習)が功を奏しているとも言われています。
しかし世の中のニーズとしては、モデルがさまざまなタスクをもっと上手くこなせるようになることが望まれています。そこで研究が進む中、指示の質や形式が全体の性能に影響することがわかってきました。また、段階的な説明を加えることでモデルの理解力が向上することもわかっています。しかし、データの管理やトレーニング方法については、まだ改善の余地があると考えられています。
一部では、人間の学び方に似せた方法でモデルを訓練することで、もっと効果的な学習ができるかもしれないという考えが提案されています。特定のタスクにおいては効果があることは検証が進んでおり、今後はもっと広い範囲での実験も期待されています。
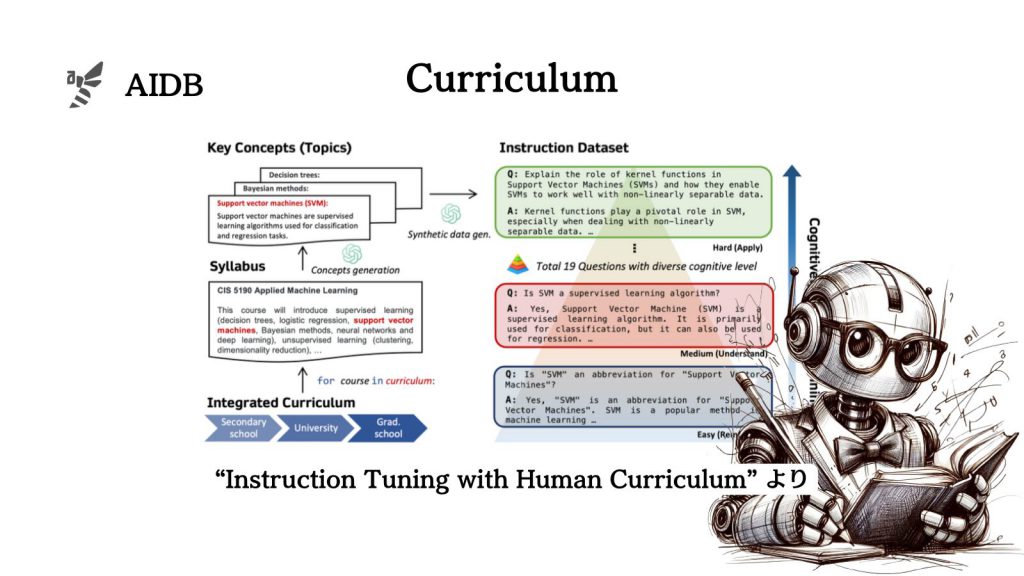
そして今回研究者たちは、人間のカリキュラム学習に似せた方法でLLMを訓練するための「CORGI」というデータセットを作成しました。学校や大学で教えられる内容を基にして作られており、学習の段階に応じた構造になっています。
手法のポイント
研究者らは、人間の教育プロセスからヒントを得たデータセットの作り方と、効果的なトレーニング方法を開発しました。
カリキュラム学習用データセットの構築
まず、

