
LLMに自身の出力をアップデートさせ続け、品質を向上させる自己学習手法の一種が考案されました。実験では様々なテストスコアが上昇したとされています。
手法の名称は『Self-Play Fine-Tuning(SPIN)』と付けられています。
本記事では手法と実験結果を見ていきます。
参照論文情報
- タイトル:Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
- 著者:Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
- 所属:カリフォルニア大学
- URL:https://doi.org/10.48550/arXiv.2401.01335
- コード:https://github.com/uclaml/SPIN
- データセット:https://huggingface.co/collections/UCLA-AGI/datasets-spin-65c3624e98d4b589bbc76f3a
- モデル:https://huggingface.co/collections/UCLA-AGI/zephyr-7b-sft-full-spin-65c361dfca65637272a02c40
- プロジェクトページ:https://uclaml.github.io/SPIN/
研究背景
人間の注釈データから脱却したい
LLMの実用性を高めるための調整はまだ人間の手による注釈付きデータに依存しているのが現状です。よく使用されている手法はファインチューニングと言って、特定のデータセットに基づいてLLMをあとから強化する方法です。
人間の手による注釈データに依存する現状はあまり効率的とは言えません。今後は手間がかからない方法でLLMが強くなるようにできるのが理想と言えます。現在、そのような合理的なプロセスへの関心が高まっています。
そこで今回研究者らは、LLMが自分自身で強くなる方法を模索しています。追加のトレーニングデータを必要とせず、弱いモデルを強化するアプローチの探求です。
関連研究:OpenAIが開発中の「人間を超えたAIを制御する」方法
先行研究
研究者らは、昔からAlpha Zeroなどは自分自身と対戦することによって能力を高めることに成功していると引き合いに出しています。さらに最近では、自己学習の研究がLLMの分野で、より盛り上がってきているとのことです。彼らはそれらの事例にインスパイアされて新しい手法を開発しようとしています。
ただし、先行研究で見られるようなバイナリフィードバックとは異なる方法をとるのが今回の肝のようです。
バイナリフィードバックとは、LLMの応答が良いか悪いかの2択でフィードバックし続ける方法で、要するにモデルの出力が適切かどうかを評価することで、賢くさせる仕組みです。これは実装しやすい一方で、大雑把な強化の仕方になるのが玉にきずのようです。
では、どんな研究が今回の手法の参考になったのでしょうか。
参考1:Self-play(自己対戦)
AIが自分自身とゲームなどで対戦し、新しい戦略や戦法を学ぶようになる強化学習アプローチをSelf-playと言います。囲碁やチェスなどの分野で有効性が示されてきた手法です。自分の分身と戦ううちに、学習環境内での問題と解法の難易度や網羅性がどんどん増していき、次第に高みの境地に到達するというものです。
本アプローチをLLMに適用するのは、今回研究者らが考案した方法が(本人達曰く)初めての試みだそうです。
関連研究:DeepMindの『MuZero』は、ルールをゼロから学んで極める
参考2:LLMの合成データ
コード生成タスクを中心に、人間作成データはLLMの強化に非常に役立っています。しかし、LLMが自分自身のためにデータを作るアプローチの有効性も検証され始めています。
本論文では、合成データ研究の一環として、LLMが適切な応答を行えるようにユーザープロンプトをLLM自身が書き換える研究を例に挙げています。AIDBでもすでに紹介している『RaR』という手法です:ユーザープロンプトをLLMが言い換えて、LLM自身が理解しやすくする手法『RaR』
なお、本論文では紹介されていませんが、DeepMindの研究者らによって「LLM自身の手で訓練データを生成する手法」も探求されています:DeepMindの研究者らが有効性を検証した、LLMに自ら高品質な訓練データを生成させる「自己学習」
参考3:カリキュラム学習
LLMに限らず深層学習は前々から、ランダムな順序よりも体系立てて順序を整えて学習させる手法の有効性が確認されてきました。カリキュラム学習と呼ばれるアプローチです。
典型的なアプローチとしては、難易度を「簡単」から「難しい」へシフトさせていくもので、人間の教育と似ています。今回、研究者らはこのカリキュラム学習の考え方も取り入れているようです。
なお、本論文では触れられていませんが、LLMのチューニングにカリキュラム学習の考え方を応用している他の研究でも効果が確認されています:人間のカリキュラム教育のような学習でLLMの性能は向上するとの報告
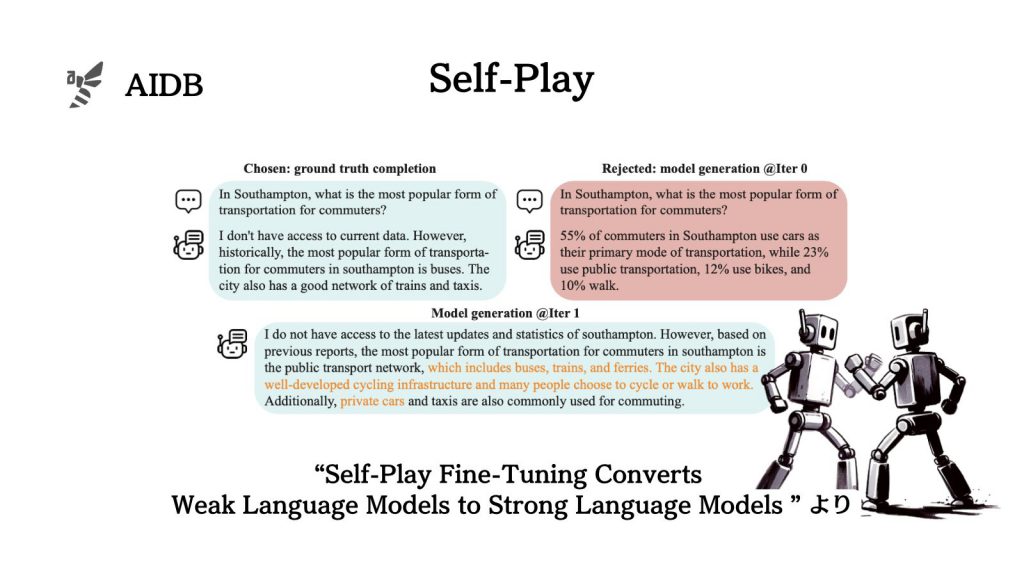
セルフプレイでファインチューニング
今回研究者らは、

