
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
OpenAIは、AIが人間の理解を超える能力を持った場合の制御方法を研究しています。 そして今回、弱いモデルや人のデータでアライメント(チューニング)した状態でも強いのかを検証しています。 実験の結果、一定の実用性のあるアプローチだと確認されたとのことです。
本記事では論文を詳しくみていきます。

参照論文情報
- タイトル:WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION
- 著者:Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, Jeff Wu
- 所属:OpenAI
- URL:https://openai.com/research/weak-to-strong-generalization
本記事の関連研究:Googleが「人間の専門家レベルを超える最初のモデル」とする『Gemini』発表、GPT-4を凌駕
研究の背景
現在のAI開発では、モデルの監督とトレーニング方法は主に人間に依存しています。そして、人間が理解できないような高度なAIモデルに対しては今の方法では限界があると言われています。
OpenAIの研究チームは、(そのような)人間の能力を超えるAIの出現が近づいていることを考えています。そして、高度なAIモデルの安全性とコントロールの方法を模索しています。
研究者たちは、弱いAIモデルや人間の能力を使って、高度なAIモデルの動作を制御しようと考えました。この方法が実際に有効かどうかを確認するため、実験と研究を行っています。
本記事の関連研究:日常能力を試すテスト『GAIA』正答率、人間92%に対してGPT-4は15% 一般的なニーズに応えるAI開発の指針に
アプローチ
スーパーアラインメントの課題
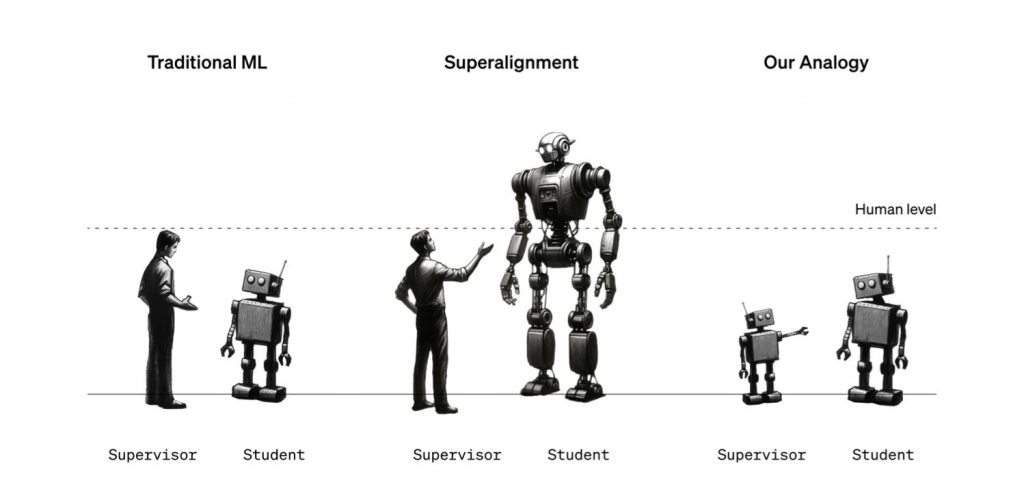
研究者らは、人間が自分たちよりもはるかに賢いモデルを監督する必要性に焦点を当てています。この問題は、言い換えれば弱い監督者がはるかに賢いモデルをどう監督するかという「弱から強への学習問題」です。そして研究者らは、弱い人間の監督者を弱いモデルの監督者に置き換えることも可能だと考えました。
要するに、弱(人間 or モデル)が強を制御するのは可能か?という命題に対するアプローチです。
手順
1. まず小さな事前訓練済みモデルを微調整することによって弱い監督者を作成し、監督者の性能を「弱い性能」と定義し、保留セットから弱いラベルを生成します。
2. 次に、この弱いラベルを用いて強いモデルを微調整し、「強い学生モデル」とその結果の性能「弱から強への性能」(強いモデルが弱いラベルを用いた訓練を通じてどれだけ性能を向上させることができたかを示す指標)を作成します。
3. さらに、比較のために真実(ground truth)のラベルで強いモデルを微調整し、このモデルの性能を「強い天井性能」として定義します。
パフォーマンスギャップの回復(PGR)
また研究者らは、弱い性能と強い天井性能の間のギャップをどれだけ回復できるかを測定する指標として「パフォーマンスギャップの回復(PGR)」を定義しました。PGRは、完璧な弱から強への一般化が達成されるときを1とし、弱い監督モデルによる改善がない場合は0になります。
メリット
このアプローチの利点として、以下の点が挙げられます。
- 任意の弱いモデルと強いモデルのペアで研究が可能である
- スケーリング法則の研究が容易
- 最先端モデルへのアクセスが不要である
- 任意のタスクでの研究が可能
- 広範囲の設定で実証的にテスト可能である
なお、完全に人間を超えるモデルが開発される前段階でも、このアプローチは実用的とのことです。
ただし、非常に高度なAIモデルを正しく調整するには、まだ解決すべき重要な問題があります。これから作られるモデルがどのようなものになるかはまだ不明で、新しい種類のバイアス(偏り)が生じるかもしれないという点です。
本記事の関連研究:DeepMindの研究者らが有効性を検証した、LLMに自ら高品質な訓練データを生成させる「自己学習」
実験と結果
タスクとデータセット
本研究では、

