
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事は、研究者が自ら著書の論文を解説する特別企画です。本企画の記事は会員以外のすべてのユーザーも全文閲覧できます。皆様ぜひお楽しみください。また、本企画への応募は以前からXで募集しており、これが5記事目の公開となります。本企画は継続開催中です。研究者の方はこちらからご応募ください。
今回は、東京大学松尾研究室のIrene Li氏などによる研究グループの新しい論文”MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation”の解説です。
LLMの進化に伴い、さまざまな分野での活用が広がっています。しかし多言語・多文化の状況において、どの程度有効に機能するのかを評価することは依然として難しい課題です。
この課題に取り組むため、東京大学、Duke-NUS医科大学、早稲田大学、ノースウェスタン大学、カーネギーメロン大学、南洋理工大学、イェール大学、ジュネーブ大学の研究者らは、新しい多言語ベンチマーク「MMLU-ProX」を提案しました。

参照論文情報
- タイトル:MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
- 著者:Weihao Xuan, Rui Yang, Heli Qi, Qingcheng Zeng, Yunze Xiao, Yun Xing, Junjue Wang, Huitao Li, Xin Li, Kunyu Yu, Nan Liu, Qingyu Chen, Douglas Teodoro, Edison Marrese-Taylor, Shijian Lu, Yusuke Iwasawa, Yutaka Matsuo, Irene Li
- 研究機関:東京大学、Duke-NUS医科大学、早稲田大学、ノースウェスタン大学、カーネギーメロン大学、南洋理工大学、イェール大学、ジュネーブ大学
- GitHub:https://mmluprox.github.io/
以下、論文著者による寄稿です。
研究背景
多くの主なベンチマークは、主に英語圏を中心として設計されているため、多言語・多文化の状況におけるLLMの性能評価には限界があります。その結果、言語や文化による性能の偏りが生じ、特にリソースが少ない言語ではモデルの性能が低下する傾向が見られています。
こうした背景から、より包括的かつ公平な評価基準が求められています。この課題に応えるために開発されたのが「MMLU-ProX」です。MMLU-ProXは、類型論的に多様な13言語に対応した新しいベンチマークであり、各言語につき約11,829の質問が含まれています。
LLMが持つ高度な推論能力を多言語環境で正確に評価することを目的としています。
方法論
MMLU-ProXの構築では、効率性と精度のバランスを取るため、半自動の翻訳プロセスを採用しています。まず最新のLLMを用いて質問の初期翻訳を行い、その後、言語専門家が翻訳内容を厳密に評価・修正します。このプロセスにより、概念の正確性、専門用語の一貫性、文化的な適合性を確保しています。
実験
研究チームは、最新のLLM 25種類を対象として、5ショットのチェーン・オブ・ソート(CoT)とゼロショットという2つのプロンプト戦略を用いて性能を検証しました。この評価を通じて、言語や文化の違いがモデルの性能にどのような影響を与えるかを分析しています。
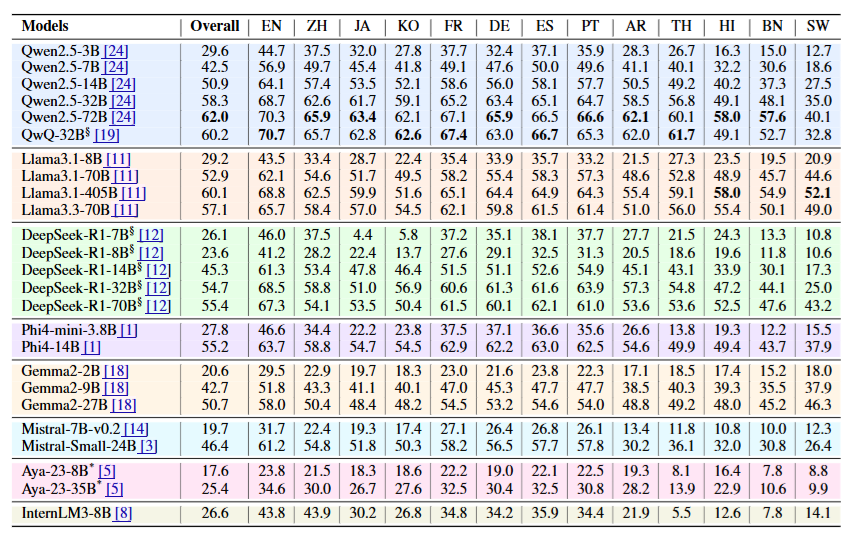
結果
実験の結果、リソースが豊富な言語からリソースの少ない言語へ移るにつれて、モデルの性能が一貫して低下することが明らかになりました。例えば、英語では70%以上の正確性を示したモデルでも、スワヒリ語などの低リソース言語では約40%まで性能が大幅に低下しました。このことから、最新の技術的な進歩にもかかわらず、多言語対応には依然として大きな課題が残されていることがわかります。
結論
MMLU-ProXは、LLMの多言語対応能力を包括的に評価できる強力なベンチマークです。このベンチマークを利用することで、モデル開発者は言語間における性能差を正確に把握し、多言語環境での実用化に向けた重要な洞察を得ることができます。将来的には、文化や言語の多様性に対応したAIシステムの開発が促進され、技術の恩恵を世界中の人々に公平に届けることにつながると期待されます。
開発コスト
MMLU-ProXの構築において特に注目すべき点は、品質確保にかけられた投資です。翻訳プロセスや言語専門家による評価などに関連するコストは、約60,000米ドルに達しました。この投資によってベンチマークの信頼性と公平性が大きく向上し、LLMの多言語対応能力をより正確に評価できるようになりました。このような取り組みは、AI技術の真のグローバル化を目指す上で、重要な一歩となるでしょう。
注意点と展望
MMLU-ProXは現在も進化を続けるプロジェクトであり、研究チームは今後さらに多くの言語やモデルを評価対象に追加する予定です。今後は、GPT-4o、Claude Sonnet 3.7、o3-miniなど最新モデルの評価を通じて、最先端LLMの多言語対応能力の進展を継続的に追跡していきます。
こうした継続的な拡張と最新モデルの評価により、LLMの多言語対応能力についての理解がさらに深まり、言語間の性能格差を縮小するための実効性のある方策が見出されると期待されています。また、新世代のモデルが低リソース言語においてどの程度性能を向上できるかという点は、AIの公平性・包括性の観点からも注目されています。最終的には、世界中のあらゆる言語の利用者にとって、公平で効果的なAIシステムの実現へとつながるでしょう。
プロジェクトページ:https://mmluprox.github.io/

