
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事は、研究者が自ら著書の論文を解説する特別企画です。AIDBの通常記事とは異なり、本企画の記事は会員以外のすべてのユーザーも全文閲覧できます。皆様ぜひお楽しみください。また、本企画への応募は以前からXで募集しており、これが4記事目の公開となります。本企画は継続開催中です。研究者の方はこちらからご応募ください。
今回は、NECの石橋 陽一氏ら研究グループによる”Can Large Language Models Invent Algorithms to Improve Themselves?“の解説です。

参照論文情報
- タイトル:Can Large Language Models Invent Algorithms to Improve Themselves?
- 著者:Yoichi Ishibashi, Taro Yano, Masafumi Oyamada
- 所属:NEC
以下、論文著者による寄稿です。
自己紹介
名前とプロフィールページ
石橋 陽一 (Yoichi Ishibashi)
X:@__tuxi__
個人サイト: https://yoichi1484.github.io/
所属
NEC Corporation
経歴
2018年3月 京都産業大学 卒業
2023年3月 奈良先端科学技術大学院大学(NAIST)博士(工学)
2023年4月 京都大学 下平・本多研究室 特定研究員
2024年4月 NEC 入社(データサイエンスラボラトリー・生成AI基盤グループ)
受賞等:言語処理学会 年次大会 優秀賞(2020)・若手奨励賞(2022)・スポンサー賞(2024)、情報処理学会 NL研 優秀研究賞(2019)など
本研究の動機
今回ご紹介するのは「次世代のLLMを作るのは、人間ではなくLLM自身かもしれない」という着想から生まれた、まさにその実現への道筋を示した研究です。
背景
我々研究者は大規模言語モデル(LLM)の性能を改善する様々な方法を発見してきました。例えばLLMをうまく学習する損失関数、プロンプトエンジニアリング、モデルマージ手法などです。
これまでは、結局のところ「どうやってLLMを賢くするか」というアイデアは、人間が考えたものばかりです。人間の想像力の範囲内でしか、LLMは進化できないのです。
しかし、LLMは一部のタスクで人間に匹敵したり、ときには上回る性能を示すようになってきています。つまり、これまで人間が行なっていた次世代のLLMの研究開発の一部をLLM自身に任せることが可能になってきているのです。
では、人間の想像や知識の制限を超えたLLMの改善方法をLLM自身で発明できるのではないでしょうか?
本研究で提案する「Self-Developing」は、LLMが自分で「より賢いLLMの作り方」を発見し、試し、更に優れた改善方法を生成できるように学習するフレームワークです。(これ以降、LLMの改善方法を「モデル改善アルゴリズム」と呼びます)
提案手法のSelf-Developingには3つの重要な特徴があります。
✔ 人間が設計したアルゴリズムを超える性能
モデルマージ(複数のAIモデルを組み合わせて1つにする)手法の自動発見にSelf-Developingを使ったところ、LLMが発見したマージアルゴリズムはGSM8kで76.1%を達成し、初期モデル(70.1%)や、Task Arithmetic(71.9%)、TIES Merging(71.8%)、Model Stock(39.5%)といった最先端の人間が設計したマージアルゴリズムを大きく上回りました。
✔ LLMとアルゴリズムの共進化
Iterative DPO(※)を通じて、LLMと改善方法の「両方」が継続的に進化します。
✔ 弱いLLMから強いLLM
人間の専門知識やGPT-4のような外部の強力なLLMからのフィードバックを一切必要としなません。
※ DPO: 「良い出力」と「悪い出力」のペアからなる選好データでLLMをファインチューニングする手法
※ Iterative DPO:DPOを繰り返し適用し、LLMを段階的に改善する手法
『Self-Developing』のアプローチ
本研究の主な目的は、LLMに自律的にモデル改善アルゴリズムを生成・適用させることです。具体的には、以下の課題に取り組みます。
”初期モデルM0とタスクが与えられた時、初期モデルM0より高性能なモデル(例:GPT-4)や人間の介入なしに、M0を超えるモデルを生成する”
この目標を達成するため、図1に示すような改善サイクルを繰り返すフレームワークを提案します。
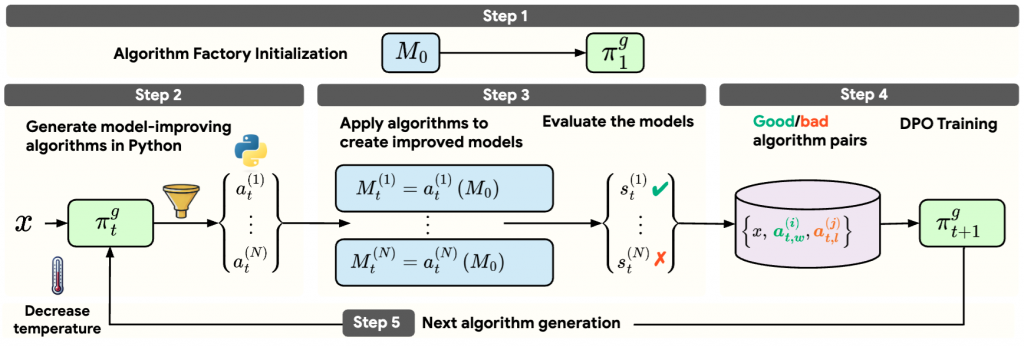
このSelf-Developingフレームワークでは、次の2つのモデルが存在します。
- M0: 改善対象のモデル(初期モデル)
- π: アルゴリズム生成モデル(M0のコピー)。初期モデルの性能を向上させるモデル改善アルゴリズムをプログラミングコードの形で生成する言語モデル。
これら2つのモデルを反復的に改善していくことで、初期モデルM0とモデル改善アルゴリズムの両方が進化できます。これは「アルゴリズムの生成」「アルゴリズムの評価」「アルゴリズム生成モデルの学習」という非常にシンプルな仕組みで実現できます。
では、それぞれのステップを1つずつ見ていきましょう。
STEP1 アルゴリズム生成モデルの初期化
最終的に改善したいモデルはM0ですが、アルゴリズム生成用に別途アルゴリズム生成モデル π を準備します。初期モデルM0をコピーしてアルゴリズム生成モデルπ1を初期化します。
STEP 2 アルゴリズムの生成
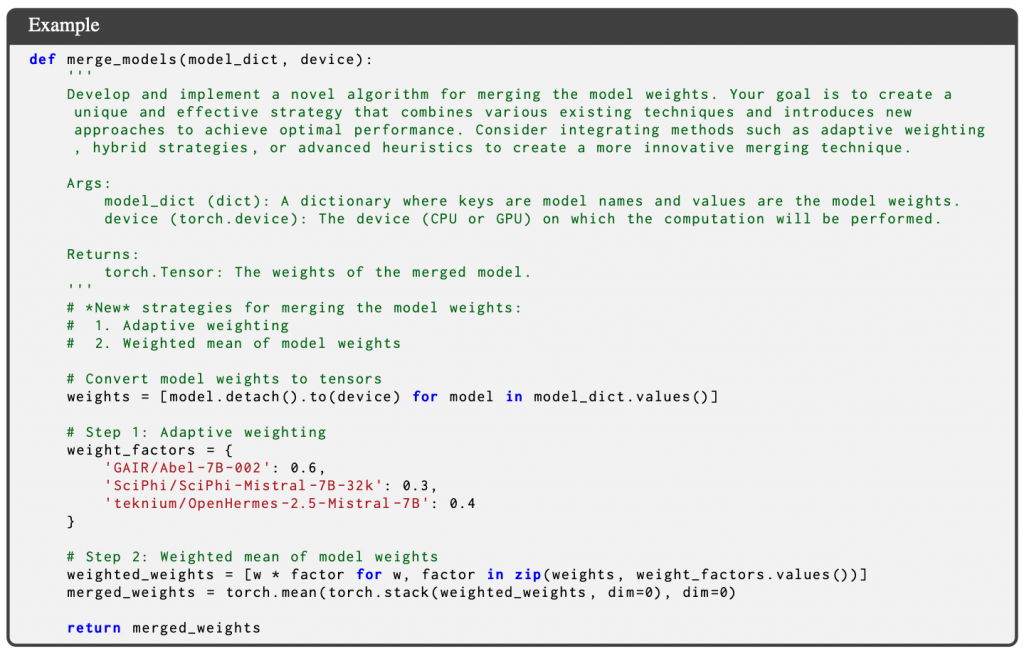
アルゴリズム生成モデルπ1がモデル改善アルゴリズムを複数生成します。後ほど述べますが、実験ではモデル改善アルゴリズムとしてモデルマージのPythonコードを生成します(図2)。モデルマージとは複数のモデルを混ぜて1つのモデルを作るモデル改善アルゴリズムの1種です。アルゴリズムの入力は、初期モデルM0に混ぜる3つのモデルの重み(タスクベクトル)です。出力は3つのモデルを混ぜたモデルの重みです。これをM0に足すとマージできます。
STEP 3 アルゴリズムの評価
アルゴリズムの有効性を評価します。まず生成されたアルゴリズムをM0に適用して新しいモデルを作成します。複数の新しいモデルが得られるので、これらを最適化したいタスクで評価すると、新しいモデルの性能がわかります。性能が高いモデルが作れれば「良いアルゴリズム」、性能が低いモデルなら「悪いアルゴリズム」です。次の学習ステップのために、このようなアルゴリズムの良し悪しの結果を集めておきます。
STEP 4 アルゴリズム生成モデルの改良
さきほど得られたアルゴリズムの評価結果を使ってアルゴリズム生成モデルを学習します。学習することでアルゴリズム生成モデルはより優れたアルゴリズムを生成することができるようになります。少し専門的になりますが、具体的には Direct Preference Optimization(DPO)を使用してアルゴリズム生成モデルを学習します。生成されたアルゴリズムを適用して作成されたモデルの評価結果に基づき、高性能なアルゴリズムと低性能なアルゴリズムから選好データを作成し、DPOでアルゴリズム生成モデルを学習します。
STEP 5 反復
ここまでのステップで「性能が向上した初期モデル」と「良いアルゴリズムを生成できるようになったアルゴリズム生成モデル」が得られました。次のサイクルではこの進化したアルゴリズム生成モデルを使用してアルゴリズムを生成します。すると高性能なアルゴリズムが生成され、さらにそれを使うと初期モデルが改善します。つまり、初期モデルとモデル改善アルゴリズムの両方が同時に改善されていくのです。このような共進化のサイクルを何度か繰り返し、最終的に非常に高性能なLLMとモデル改善アルゴリズムを何個も得ることができます。
実験
Self-Developingは様々なモデル改善アルゴリズムの発見に使えますが、実験ではモデルマージアルゴリズムの自動発見に使用しました。
アルゴリズムは3つのモデルの重み(タスクベクトル)を入力に受け取り、それらを合成して1つのモデル重み(タスクベクトル)を返す関数です。この重みを初期モデルに足すことで初期モデルを改善します。発見したアルゴリズムで、初期モデルの性能・人間が設計した最先端のマージ手法で作ったマージモデルの性能を超えることが目標です。
タスクは数学的推論で、ベンチマークデータセットにはGSM8kとMATHを使用しました。それぞれ以下の特徴を持つデータセットです。
- GSM8k: 開発セット100例、テストセット1220例
- MATH: 開発セット600例、テストセット4400例
5-shot(モデルに対して5つの例を示す)、完全一致で評価しました。
Self-Developingの設定は以下のとおりです。
- 反復回数 3回、各反復で3000アルゴリズム生成
- 各タスクに対して独立に最適化(開発セットを使用)
ベースラインには、人間が設計したモデルマージアルゴリズムであるTask Arithmetic、TIES Merging、Model Stock(提案法と同様に各タスクに対して独立に最適化)を使用しました。
以下、研究課題と実験結果です。
Q1:LLMは自己発見したモデル改善アルゴリズムを使って進化できるか?
まずはLLMが発見したアルゴリズムの性能について見ていきましょう。ここで私達が一番強調したい結果は「Self-Developing を使って、人間が設計した最先端のモデルマージアルゴリズムを超えるアルゴリズムをいくつも発見できた」という点です。
図3は、GSM8kとMATHタスクにおける人間設計のアルゴリズムとSelf-Developingによって発見されたアルゴリズムの性能比較を示しています。私たちのアプローチについては、アルゴリズム発見プロセスのすべての反復で得られた上位3つの性能を示しています。
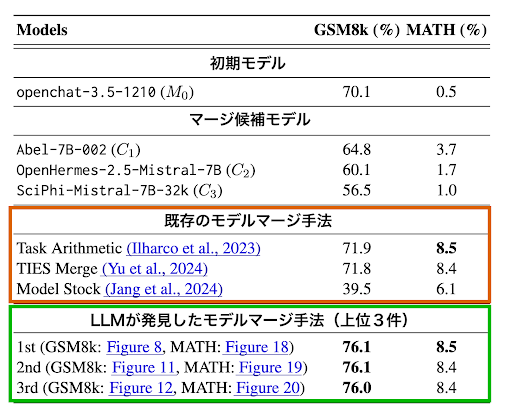
この結果は、LLMが自己発見したモデル改善アルゴリズムを使用して自身の性能を向上できることを示しています。LLMが発見したアルゴリズムを適用したモデルはGSM8kで76.1%を達成し、初期モデル(70.1%)から約+6%の大幅な性能向上を実現しています。また驚くべきことに、Task Arismetic(71.9%)、TIES Merging(71.8%)、Model Stock(39.5%)といった最先端の人間設計のモデルマージアルゴリズムを大きく上回っています。
ここで我々のSelf-Developingは、人間の介入だけでなく初期モデルより強力な外部モデル(例:GPT-4)もアルゴリズム生成に使用していない点に注意してください。これはつまりLLMが「自身より強い監督者」がない状況で自己進化できるということを意味しています。
※実験では、初期モデル(seed model)としてopenchat-3.5-1210が使用されています。Mistral-7B-v0.1をベースにファインチューニングされたモデルです。
Q2:アルゴリズム生成モデルの訓練はアルゴリズムの質を向上させるか?
私たちの研究の主要な貢献は、アルゴリズム生成モデルの訓練を初めて取り入れた事によって「強力なモデル改善アルゴリズムの大量発見に成功」した点です。以下ではこの仕組みがアルゴリズムの生成品質の大幅な向上につながることを実証します。
図4は、反復ごとにアルゴリズムの質が向上することを示しています。この図は、各反復で生成されたアルゴリズムを使用して作成されたモデルの開発スコアの分布を示しています。言い換えれば「(生成した)アルゴリズムの性能の分布」と言えます。
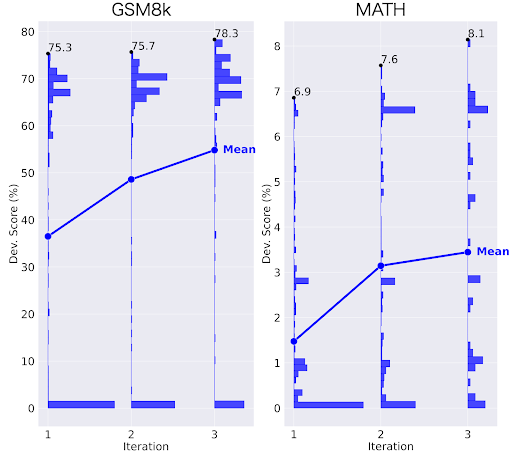
ではLLMで生成したアルゴリズムの性能が反復の進行とともにどう変化していくのかを見てみましょう。
まず、初期の反復に注目すると、低性能のアルゴリズムを多く生成していることがわかります。この段階ではまだアルゴリズム生成モデルは学習されていないので、良いアルゴリズムと悪いアルゴリズムの区別がついていない状態です。
しかし、反復が2、3と進むにつれて、徐々に良いアルゴリズムを多く生成するようになっていきます。図をみると反復3では、低性能なアルゴリズムの生成数は少なくなり、反対に高性能なアルゴリズムの生成数が増加しています。しかも驚くべきことに、それ以前の反復で発見したアルゴリズムを超える、新しい高性能アルゴリズムを発見できています。
つまり、アルゴリズム生成モデルを繰り返し訓練することによって、良いアルゴリズムと悪いアルゴリズムを区別できるようになっていった結果、反復後期では「非常に高性能なアルゴリズム」を「大量に発見できる」のです。
発見されたアルゴリズム
最後に、発見された高性能なアルゴリズムを紹介します。図5がGSM8kで最も高い性能を達成したマージモデルを作ったアルゴリズムです。
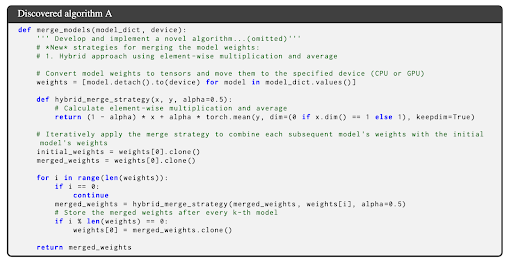
既存のマージアルゴリズム(Task Arithmetic)(図2)は単なる加重平均ですが、LLMで発見されたマージアルゴリズムは複雑なアルゴリズムになっています。
そのほか、ベクトルの要素の積を用いる方法(図6)、コサイン類似度を用いる方法(図7)、タスクベクトルのノルムに応じてソートする方法(図8)など、様々なのものが発見されました。詳しくは論文に記載しているのでご覧ください。

今後取り組むこと
今回私達が提案したSelf-Developingはこれまで研究者が行なっていたLLMの開発そのものを自動化する重要な一歩だと思っています。今後もLLMの自己改善の研究に挑戦していきます。
編集後記
ご寄稿いただきありがとうございました!僭越ながら編集部から後記を書かせていただきます。
今回の研究の出発点となっている下記の着眼点がとても示唆に富んでいるのではないかと考えさせられました。
結局のところ、「どうやってAIを賢くするか」というアイデアは、人間が考えたものばかりです。…(中略)…人間の想像や知識の制限を超えたLLMの改善方法をLLM自身で発明できるのではないでしょうか?
(背景セクションより)
LLMのユーザー間では「LLMの出力を使用した制作物は、結局のところ使い手の能力を超えないのではないか」といった声が上がることもあります。今回の研究はそういった固定観念を一部覆すような結果が出ているとも読めるのではないでしょうか。人間の考えを超えたアウトプットを実行することで実際に恩恵が得られているためです。
さらに、LLMによってLLM自身が進化するといったチャレンジングな課題で実験され、その有効性が示されているのはまさに発想通りの着地で非常に興味深く拝見しました。
今回の手法をさらにさまざまなベースモデルで試されたり、別の課題(様々なモデル改善アルゴリズムの発見に使えるとされています)にも応用されたりと多くの可能性があるかと思いますので、今後の研究や実験結果にもぜひ注目させてください。
最後に、AIDBではこうした形を一つの事例として、研究者と良い関係を構築していきたいと考えています。これが読者の皆様にとっても有益なものであると信じています。今後も三方良しの施策を練っていきます。ご期待ください。

