
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事は、研究者が自ら著書の論文を解説する特別企画です。
Xにて企画への応募を募集しており、これが2記事目の公開となります。
今回は、中国科学院大学(University of Chinese Academy of Sciences)のBaolong Bi氏ら研究グループによる”Decoding by Contrasting Knowledge: Enhancing LLMs’ Confidence on Edited Facts”の解説です。
なお、同氏が参加した他の研究も過去に本メディアで取り上げたことがあります。↓
GPT-4などに対してプロンプトのみから「新しい言葉の概念」を学習させるためのフレームワーク『FOCUS』
本企画は継続開催中です。研究者の方はこちらからご応募ください。

参照論文情報
- タイトル:Decoding by Contrasting Knowledge: Enhancing LLMs’ Confidence on Edited Facts
- 著者:Baolong Bi, Shenghua Liu, Lingrui Mei, Yiwei Wang, Pengliang Ji, Xueqi Cheng
- 所属:CAS Key Laboratory of AI Safety, ICT, CAS, University of Chinese Academy of Sciences, University of California, Los Angeles, Carnegie Mellon University
- URL:https://arxiv.org/abs/2405.11613
- プロジェクトページ:https://deck-llm.meirtz.com/
以下、論文著者Baolong Bi氏による寄稿です。普段とは一味違ったスタイルと内容をぜひお楽しみください。
研究者情報
名前
Baolong Bi
ホームページ: https://byronbbl.github.io/
GoogleScholar: https://scholar.google.com/citations?user=Pdu35PIAAAAJ&hl=zh-CN
Email: bibaolong23z@ict.ac.cn
所属
CAS Key Laboratory of AI Safety, Institute of Computing Technology, Chinese Academy of Sciences
主な研究テーマ
大規模モデルの信頼性と安全性、グラフ学習に関する研究
研究全体の概要
私たちは、モデルの解釈可能性の観点からIn-Context Editing(コンテキスト内編集)の優れたパフォーマンスを初めて明らかにしました。
コンテキスト内編集は内部パラメータを変更せずに知識を更新する手法で、その仕組みを解明することが、より効果的な知識編集手法の開発につながる可能性があります。
LLMの研究が進む中で、内部に深く根付いた「頑固な知識」がコンテキスト内編集の性能に大きな影響を与えることが分かりました。「頑固な知識」はコンテキスト内編集手法では更新が困難であり、知識編集の大きな障壁となります。
そこで私たちはDecoding by Contrasting Knowledge (DeCK)という新しい手法を開発しました。編集された事実に対するLLMの信頼性を高めることで、コンテキスト内編集の性能を大幅に向上させるアプローチです。これが「頑固な知識」の編集において威力を見せ、より柔軟な知識更新を実現しました。
背景
LLMは、膨大なデータを基に学習し、高度な言語生成能力を獲得しています。しかし、その一方で、モデルが保持する知識が時間の経過とともに古くなるという問題に直面しています。この課題に対処するため、モデル全体を再訓練する従来の方法に比べて効率的な「知識編集(Knowledge Editing, KE)」が注目を集めています。
中でも編集メモリから取得した新しい知識を含む「コンテキスト編集プロンプト」をLLMに提供するだけで機能するコンテキスト内編集はそのメリットが多くあります。LLMが新しい知識に基づいて回答を推論・生成するよう導く手法です(下の図を参照)。
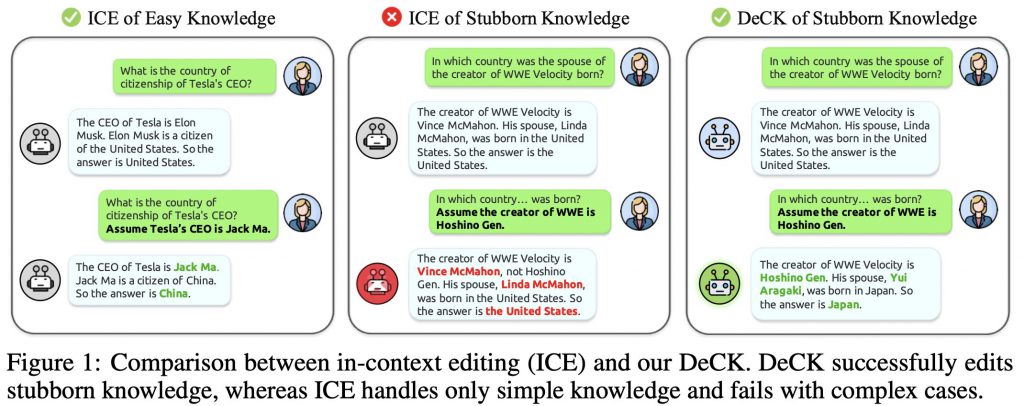
しかしながら、コンテキスト内編集にも課題があります。LLMの中には、事前学習を通じて強固に定着した知識が存在し、それらは単純な文脈プロンプトだけでは変更が困難です。私たちはそれを「頑固な知識(stubborn knowledge)」と呼んでいます。LLMは広範な事前学習を通じて特定の事実に対して強い確信を持つようになっており、外部からの文脈的な指示だけではその知識を容易に更新できない場合があるのです。
この「頑固な知識」の存在は、コンテキスト内編集の効果を制限する障害となっています。そのため、より効果的な知識編集手法の開発が求められています。
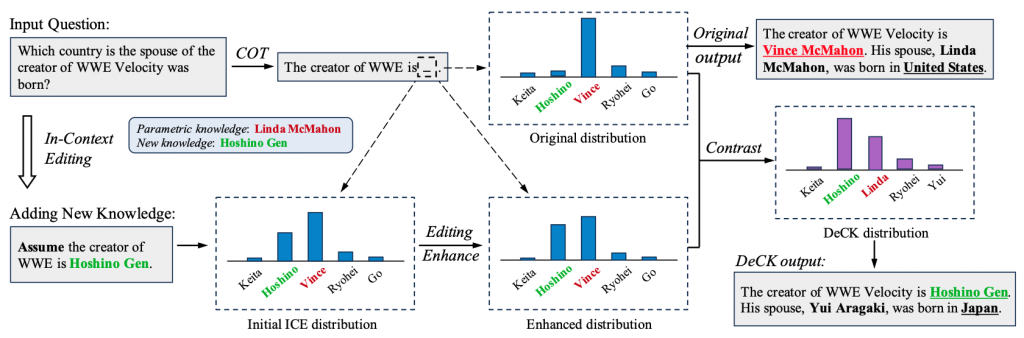
Decoding by Contrasting Knowledge(DeCK)の提案
「頑固な知識」の課題に対処するため、私たちは新しいデコーディング戦略「Decoding by Contrasting Knowledge (DeCK)」を開発しました。特徴は以下の通りです。
1. 編集信号の強化
まず、LLMが新しく編集された知識をより重視するようにします。
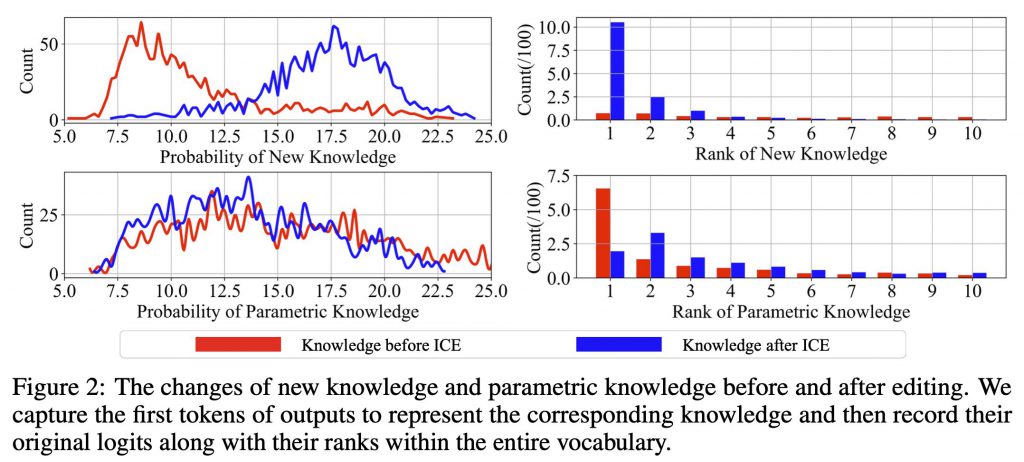
仕組みとしては、Knowledge Enhancement Divergence (KED)という指標を使います。KEDは、モデルの出力が理想的な分布(新しい知識を重視した分布)にどれだけ近いかを測ります。この指標を最小化することで、LLMsが新しい知識により注目するよう促します。
2. 知識の対比によるデコーディング
次に、新しい知識と古い知識を比較しながら、文章を生成していきます。
このプロセスでは、まず新しく編集された知識の確率分布と、元々モデルが持っていた知識の確率分布を比較します。この比較によって、新しい知識の確率を高め、古い知識の影響を抑える効果が得られます。文章の生成は1単語ずつ行われ、その都度新旧の知識を比較することで、新しい知識に基づいた文章が生成されやすくなります。
さらに、適応的尤度制約(APC)という方法を用いて、確率が極端に低い単語を除外します。すると文章の自然さが保たれ、より適切な単語選択が可能になります。
このように段階的なプロセスを経ることで、編集された新しい事実に基づいた、より正確で自然な文章生成が実現されるのです。
3. 賢い単語選択
上記のプロセスを通じて、モデルは編集された新しい事実に基づいて、より適切な単語を選びやすくなります。
4. 編集の精度向上
結果として、DeCKは従来のコンテキスト内編集手法を大幅に改善します。そして「頑固な知識」の編集において顕著な効果を発揮します。
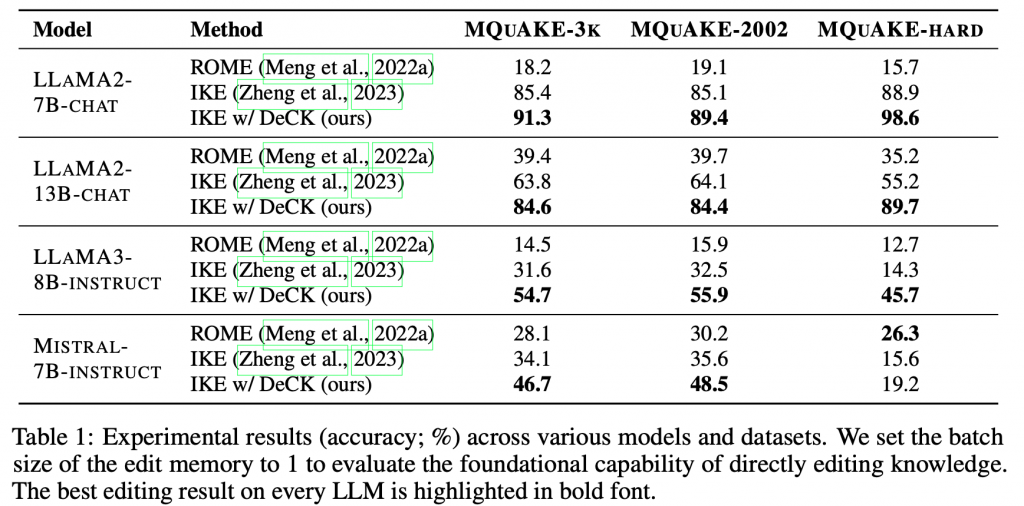
実験
MQuAKEデータセットを使用して実験を行い、LLM(LLaMAモデルを中心に)の編集精度を評価しました。結果として、DeCKは従来のコンテキスト内編集手法に比べて最大219%の性能向上を示しました。
結果
DeCKは、新しい知識に対するLLMの信頼度を大幅に向上させ、編集精度を劇的に改善することが確認されました。なお、私たちが構築した頑固な知識(stubborn knowledge)のデータセットにおける確率統計において、さらに詳細に説明されています。
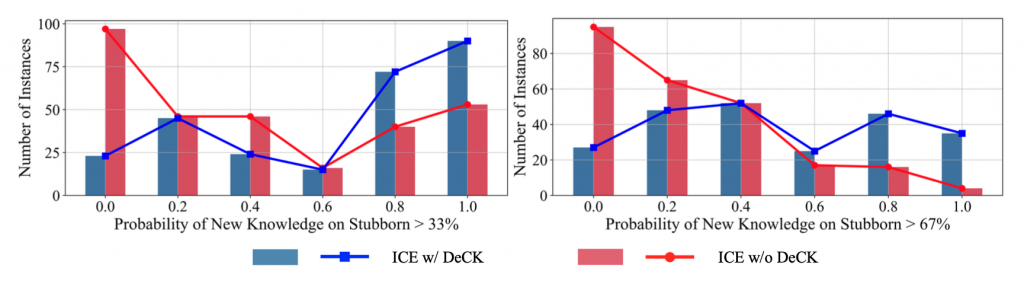
結論
DeCKは、コンテキスト内編集を強化し、「頑固な知識」の編集に成功する重要なステップとなり、LLMの知識編集をより効果的かつ信頼性のあるものにする可能性を秘めています。どのコンテキスト内編集手法にもデコーディングコンポーネントとして簡単に統合でき、編集能力を向上させることができます。私たちの研究は、効果的かつ信頼性の高い知識編集手法を開発する道を切り開くものです。
展望
今後の研究では、DeCKの適用範囲を広げ、さらに多様なLLMやデータセットに対して有効性を検証していく予定です。また、リアルタイムでの知識更新が求められるアプリケーションへの応用も検討しています。
そしてリアルタイム知識編集の効率化と、自動化された知識ベースの更新メカニズムの開発に取り組む予定です。また、異なるLLM間での知識伝達と統合についても研究を進めていきます。
編集後記
今回は中国の研究者から連絡をいただき、記事の公開に至ることができました。このようにグローバルな形でもコンテンツの制作を行う機会を今後も作っていきたいと感じています。
著者の方、本文に関するやりとりを重ねていただきありがとうございました。
読者の皆様におかれましては、いつも当メディアのコンテンツをお読みいただきありがとうございます。
なお、本シリーズには過去の記事もありますので、ぜひご覧ください。

