
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事は、研究者が自ら著書の論文を解説する特別企画です。AIDBの通常記事とは異なり、本企画の記事は会員以外のすべてのユーザーも全文閲覧できます。皆様ぜひお楽しみください。また、本企画への応募は以前からXで募集しており、これが3記事目の公開となります。本企画は継続開催中です。研究者の方はこちらからご応募ください。
今回は、東京大学のIrene Li氏ら研究グループによる”KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques”の解説です。当メディアでも紹介している多くの研究でも言及されているように、LLMの出力は時として事実と異なる情報を含む場合があり、これは医療などの専門分野で特に深刻な問題として捉えられています。そんな中、本研究者らは状況の改善を試みています。
プロジェクトリーダーのIrene Li氏は自然言語処理とLLMの専門家で、著書論文の被引用件数は(2024年9月現在)総数2,500件以上です。なお、今回紹介する論文の著者一覧には松尾豊教授のお名前も含まれているようです。
参照論文情報
- タイトル:KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
- 著者:Rui Yang, Haoran Liu, Edison Marrese-Taylor, Qingcheng Zeng, Yu He Ke, Wanxin Li, Lechao Cheng, Qingyu Chen, James Caverlee, Yutaka Matsuo, Irene Li
- 研究機関:デューク-NUS医科大学、東京大学松尾-岩澤研究室、テキサスA&M大学、ノースウェスタン大学、シンガポール総合病院、浙江大学、浙江研究院、イェール大学、そして米国国立衛生研究所(NIH)
- GitHub:https://github.com/ruiyang-medinfo/KG-Rank
以下、論文著者による寄稿です。
研究グループの自己紹介
東京大学のLiLabは、Irene Li博士が設立・主導する研究グループです。NLP(自然言語処理)やLLM(大規模言語モデル)に特化し、特に医療や科学分野のテキストなど専門的領域の研究に焦点を当てています。イェール大学(Yale University)でNLPの博士号を取得したLi博士は、現在東京大学でプロジェクト助教を務めています。そして著名な研究機関との協力を通じて、高度に国際的な研究環境を構築し、推進しています。

ホームページ: https://www.li-lab.me/home
Email: ireneli@ds.itc.u-tokyo.ac.jp
Google Scholar: https://scholar.google.com/citations?user=JuYPjCMAAAAJ
研究背景
LLMは質問に対して高度な応答能力を有していますが、時として誤った情報や不正確な情報を提供することがあります。この問題は、特に専門分野の質問において一層深刻となります。医療アドバイスに関しては、専門家は情報を実行に移す前に必ず確認すること、あるいは実際の医師に相談することを推奨しています。LLMが生成する医療関連の回答は、潜在的リスクを回避するため、慎重に取り扱う必要があります。
そこで、当研究グループの最新論文「KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques」では、LLMが長文の医療質問に対してより事実に基づいた回答を提供する手法を提案しています。本研究は、デューク-NUS医科大学、東京大学松尾-岩澤研究室、テキサスA&M大学、ノースウェスタン大学、シンガポール総合病院、浙江大学、浙江研究院、イェール大学、そして米国国立衛生研究所(NIH)との共同研究成果です。また、2024年ACL BioNLPワークショップにて発表されました。
提案アプローチ『KG-Rank』
より事実に基づいた質問応答を実現するため、私たちは”KG-Rank”手法を提案します。この手法は、LLMが医療質問に回答する際に、知識グラフとランキング技術を適用して精度の向上を図るものです。
医療分野における知識グラフは、相互に関連する情報が繋がった蜘蛛の巣のような役割を果たします。通常、知識グラフはトリプレット(3つ組の要素)で表現されます。各トリプレットは、主語、述語(関係性)、目的語の3つの部分で構成されます。以下に例を示します。
主語:「アスピリン」
述語:「治療する」
目的語:「頭痛」
このトリプレットは、アスピリンが頭痛の治療に使用されることを示しています。この構造により、コンピュータは関連する医療概念を結びつけ、情報を体系的に理解することが可能となります。
知識グラフを適用する目的は、医療知識を体系的に組み込むことで、LLMの回答の正確性と事実性を向上させることにあります。本研究では、UMLS(Unified Medical Language System:統合医療言語システム)を知識グラフとして使用しました。UMLSは、多様な情報源からの医療用語や関係性をコンピュータと人間の双方が理解できるようにする大規模なデータベースです。
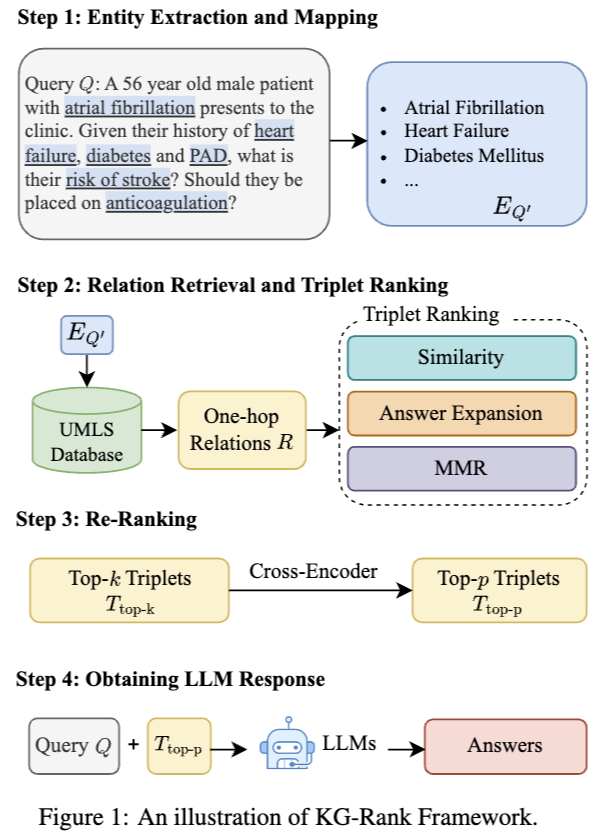
KG-Rank手法は上の図(図1)に示されている通り、典型的なRAG(Retrieval-Augmented Generation)フレームワークを採用しています。このメソッドは以下の4つのステップで構成されています。
ステップ1:医療に関する質問が入力されると、まずゼロショットエンティティ抽出が行われ、薬剤名や病名などの医療用語が質問文から抜き出されます。
ステップ2:抽出された各医療用語について、UMLSから関連する知識を取得します。この知識はトリプレット(3つ組の要素)の形式で提供されます。ここでの課題は、最も関連性が高く有用なトリプレットをいかに選択するかという点です。そこで、埋め込みベースの手法を用いてこれらのトリプレットをランク付けすることを提案します。具体的なやり方としては、UmlsBERTを用いてトリプレットをエンコードし、入力された質問と各トリプレットの間のコサイン類似度を計算します。この過程で、上位k個の候補を選択します。
ステップ3:ステップ2で得られたランク付けされたリストに対し、MedCPTを用いて再ランク付けを行います。このプロセスがパフォーマンスをさらに向上させ、最終的に上位p個のトリプレットを選定します。
ステップ4:最後に、元の入力質問と上位p個の選定されたトリプレットをLLMに提供し、最終的な回答を生成します。
上記のステップにより、医療分野の知識を効果的に活用し、より正確で信頼性の高い回答の生成を目指しています。
実験結果
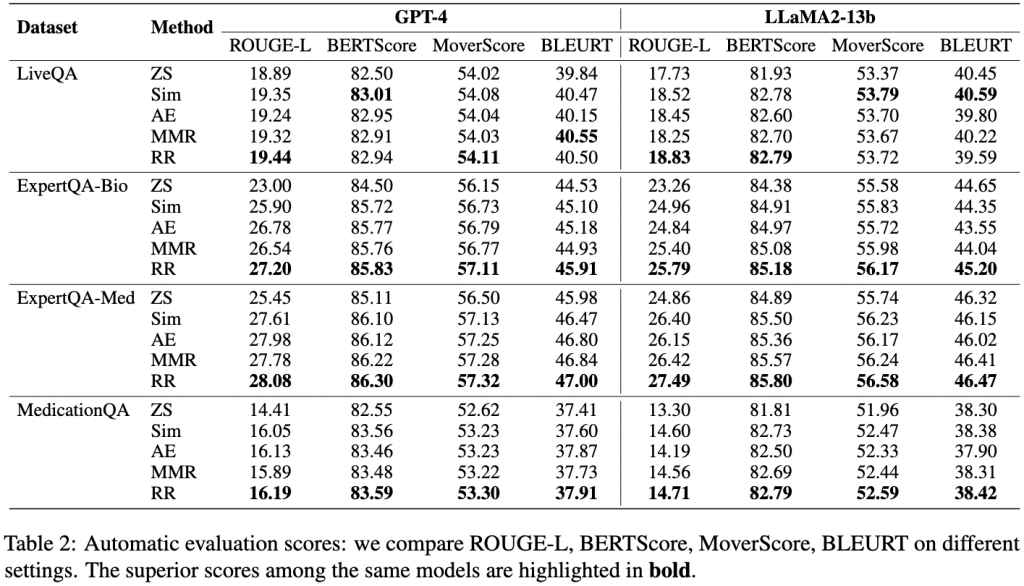
上の表(表2)では、複数の医療QAベンチマークにおける実験結果を示しています。評価には、ROUGE(Recall-Oriented Understudy for Gisting Evaluation)などのテキスト生成メトリクスを使用しました。ベースとなるLLMとして、GPT-4およびLLaMa2の結果を報告しています。注目すべきは、RR(Re-Ranking:再ランキング)設定が、ほとんどの状況下で最良の結果を達成したという点です。
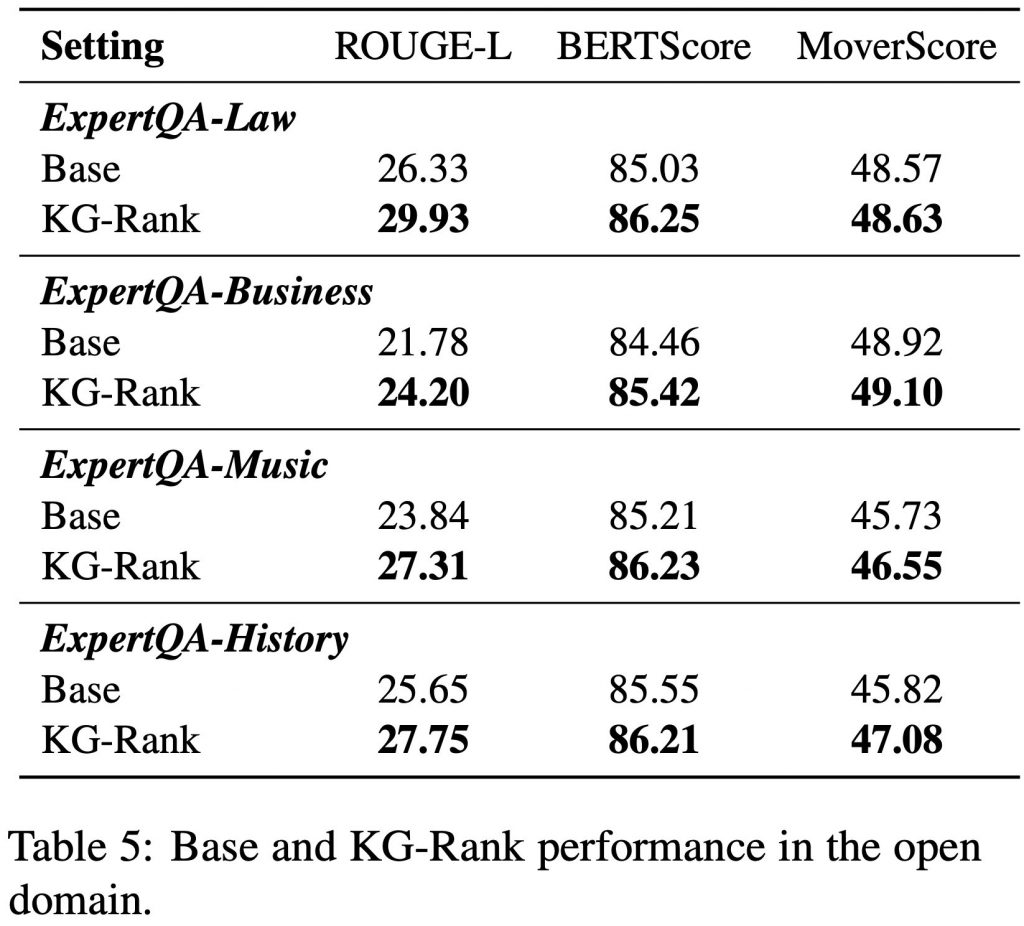
また、本手法の汎用性を検証するため、オープンドメインにおいてもテストを実施しました。ベースモデル(GPT-4)と比較すると、KG-Rankを適用することで、回答の質が顕著に向上することが確認されました(上の図)。

上の図(図3)には、医療に関する質問のケーススタディを提示しています。KG-Rankを使用しない場合、LLaMaはタンパク質摂取量に関して誤った数値を出力しています(赤色で強調表示)。一方、私たちが提案する手法では、正確な数値が提示されています(青色で強調表示)。この改善の過程をより詳細に理解していただけるよう、デモ動画も用意しました。
https://github.com/ruiyang-medinfo/KG-Rank?tab=readme-ov-file#system-demo
結論
KG-Rank(Knowledge Graph Ranking)手法は、医療知識グラフを適用することにより、医療分野における長文回答の質を大幅に向上させ、より専門的な知識を効果的に反映できることを実証しました。さらに、この手法が医療以外の分野にも応用可能であるという潜在的な可能性も見出しています。
展望
今後の研究方針として、私たちの研究チームは、日本語やその他の計算言語学的リソースが限られた言語における医療テキスト生成に注力していきます。具体的には、既存のLLMの性能を向上させつつ、翻訳や文章の簡略化など、各言語に特有のLLM研究においてこれまであまり注目されてこなかった課題に取り組むことを目標としています。これらの取り組みを通じて、多言語での医療情報アクセスの向上に貢献したいと考えています。
編集後記
今回は、イエール大学から東京大学へ異動され、さまざまな研究機関と連携するIrene Li氏と研究グループによる論文を自ら解説していただきました。
冒頭でも述べられている通り、LLMをさまざまな分野で使用することへの期待感は高く、一方で医療のように専門的かつ重要な世界で活用するには情報の正確さを高める必要があります。今回紹介していただいた研究では改善の可能性が見出されており、こうした事例を見るとこれからも技術の発展や活用に希望を持てるのだと感じます。
同グループはほかにもさまざまな研究成果を発表しているのでぜひチェックしてみてください。展望で触れられているように日本語に関するプロジェクトがあるのも非常に興味深いですね。
なお、AIDBではこうした形を一つの事例として、研究者と良い関係を構築していきたいと考えています。これが読者の皆様にとっても有益なものであると信じています。今後も三方良しの施策を練っていきます。ご期待ください。

