ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事では、視覚と言語を組み合わせたマルチモーダルLLMの推論能力を大きく向上させた新しい研究を紹介します。
これまでの視覚言語モデルは一般的に論理的な推論を苦手としており、また推論過程でエラーを起こしやすいという問題を抱えていました。そこで研究チームは、人間のように段階的に考えを組み立てていく新しいアプローチを開発し、その有効性を実証しました。

背景
視覚は世界を理解し認知能力を拡張するために言語と同様に重要な要素とされています。そのため、言語と視覚を統合しながら推論するマルチモーダルモデルの開発は重要な課題とされています。
通常、視覚言語モデル(VLM)は論理的推論を必要とするタスクは得意としていません。Chain-of-Thought(ステップバイステップの思考)を導入すると性能は向上するものの、多くのVLMは依然として推論過程でエラーや幻覚出力(事実とは異なる回答)を生成するという課題を抱えています。
研究チームの分析によると、上記の問題の主な原因は、既存のVLMの推論プロセスが十分に構造化されていないことにあるようです。
推論プロセスの構造化に成功している例といえばOpenAI o1です。しかしo1の技術的詳細はブラックボックスのままです。
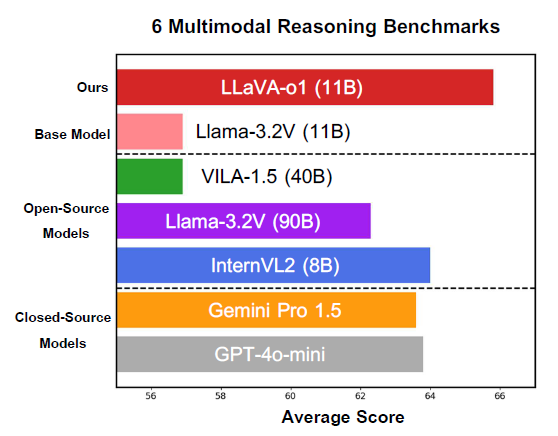
そこで今回研究者らは、VLMが自律的にステップバイステップの推論を行う能力を向上させるアプローチを新たに考えることにしました。そうして生まれたのがLLaVA-o1と呼ばれる方法論です。
LLaVA-o1は特定の単一モデルを呼称するものではなく、ベースモデルをトレーニングするフレームワークそのものです。なおLlama-3.2VをベースモデルとしたLLaVA-o1モデルは実際に開発されました。