
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
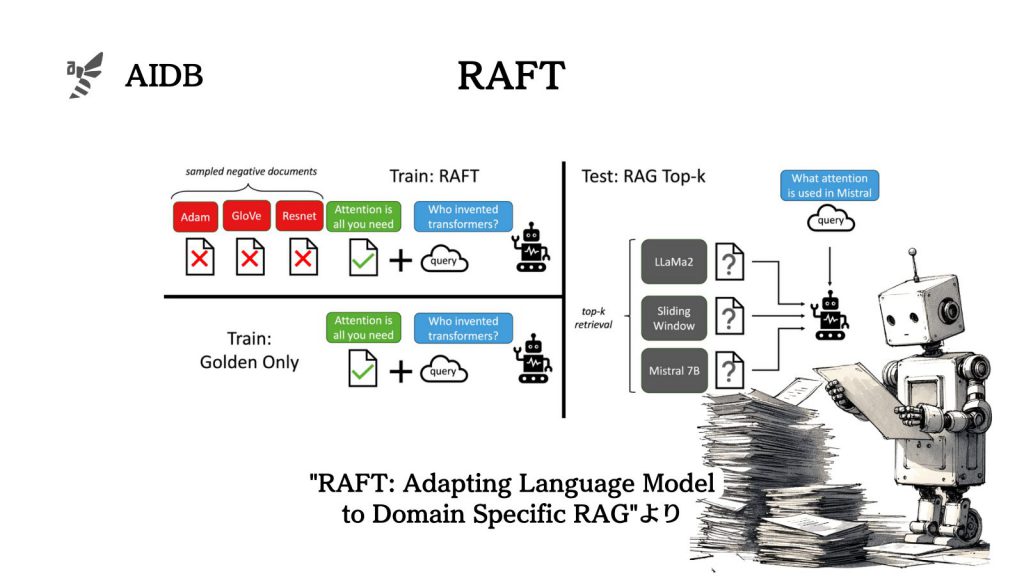
新しい知識をLLMに効果的に学習させる上でRAGやファインチューニングなどが提案されてきましたが、最適な汎用的方法はまだ明らかになっていません。そんな中今回新しく提案されたのが、Retrieval Augmented Fine Tuning (RAFT)という学習手法です。質問と関連する文書群が与えられた際に、質問に答えるのに役立たない文書を無視するようモデルを学習させるフレームワークです。
参照論文情報
- タイトル:RAFT: Adapting Language Model to Domain Specific RAG
- 機関:UC Berkeley
- 著者:Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
背景
LLMは、膨大な量の公開データで学習することにより、幅広い一般知識推論タスクで著しい進歩を遂げてきました。一方で、LLMが特定の分野のタスクに用いられる場合、一般的な知識推論よりも、与えられた文書に対して正確であることが強く求められています。例えば最新のニュースや企業の非公開文書などに適応させることは課題になっています。
LLMを特定分野に適応させる際、検索拡張生成(RAG)を用いたコンテキスト学習と、教師あり微調整(supervised fine-tuning)の2つの手法が主に考えられます。
RAGベースの手法は、LLMが質問に答える際に文書を参照するものです。この手法では、モデルが事前に学習しているわけではありません。外部のナレッジベースから関連情報を取得することで問題解決能力を向上する(比較的リーズナブルな)アプローチです。
教師あり微調整は、文書からより一般的なパターンを学習し、エンドタスクやユーザーの好みにモデルが適応します。この手法に関しては、学習に使用された文書を活用できないことがあるにもかかわらず、検索プロセスの不完全性を考慮できていません。要するにRAGと組み合わせることが前提となっていません。
筆者らは、この問題を、参考書を見ながら受ける試験(オープンブック試験)に例えて解決しようと考えています。既存のRAG手法は、勉強せずにオープンブック試験を受けるようなものです。一方、既存の微調整アプローチは、入力文書を直接「暗記」したり、文書を参照せずに練習問題に答えたりするようなものと言えます。どちらも、ベストなパフォーマンスが出るアプローチとは言えません。
そこで今回研究者らは、教師あり微調整(SFT)と検索拡張生成(RAG)を効果的に組み合わせた方法「検索拡張微調整(RAFT)」を開発しました。

RAFTは、LLMが分野の知識を組み込むための微調整と、分野内RAGのパフォーマンス向上の両方の課題に取り組んでいます。問題に対して役立つ知識とそうでない知識を判別できる状態で、参考書を開いてテストに臨めるようなコンセプトだと言います。

