
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
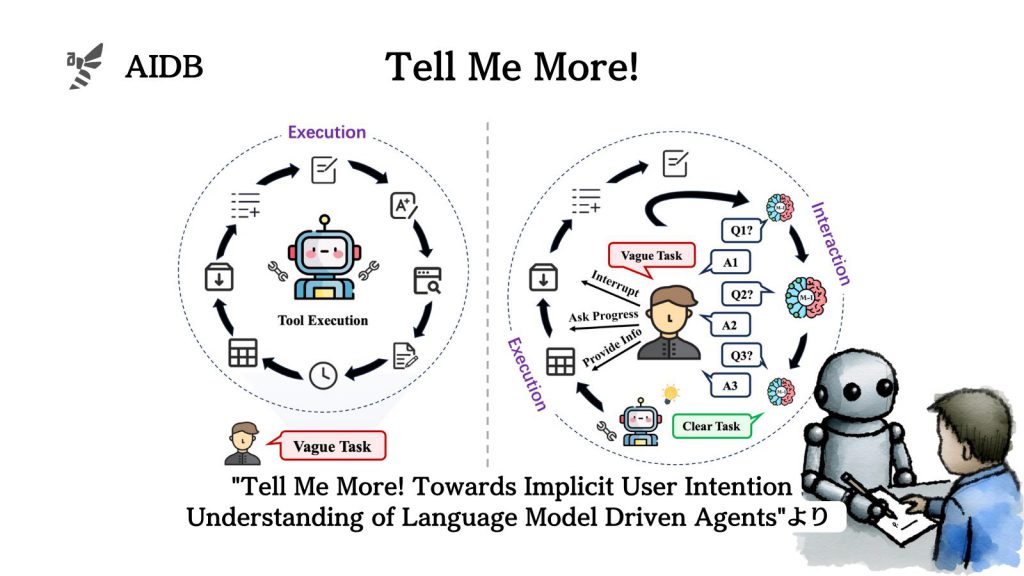
現行のLLMエージェントは、ユーザー指示の不明確な点を質問したり、ユーザーの意図を正確に把握することが苦手です。
そこで今回研究者らは、ユーザーの意図を探るためのベンチマークを開発しました。そしてタスクの曖昧さを見極め、ユーザーの意図を聞き取り、実行可能な目標に絞り込んでから下流のエージェントによるタスク実行を行うモデルMistral-Interactを開発しました。
参照論文情報
- タイトル:Tell Me More! Towards Implicit User Intention Understanding of Language Model Driven Agents
- 著者:Cheng Qian, Bingxiang He, Zhong Zhuang, Jia Deng, Yujia Qin, Xin Cong, Zhong Zhang, Jie Zhou, Yankai Lin, Zhiyuan Liu, Maosong Sun
- 所属:Tsinghua University, Renmin University of China, WeChat AI, Tencent Inc.
- URL:https://doi.org/10.48550/arXiv.2402.09205
- GitHub:https://github.com/HBX-hbx/Mistral-Interact
背景
大規模言語モデルはAIエージェントとしてユーザーを支援することにも使われ始めています。また、エージェント開発に特化した多くのオープンソースフレームワークが登場しています。
しかし、現在のLLMエージェントには次のような課題があります。
- ユーザーがエージェントに与える指示は曖昧で簡潔すぎる場合が多い
- 一見明確な指示でも意図が異なる可能性があるため、明示的な質問によって探る必要がある
要するに、エージェントは表面的な目標を達成したように見えても、実はユーザーの真の意図とかけ離れてしまう「見せかけの成功」に陥りがちです。そのため、エージェントはユーザーとのやり取りを通じて隠れた意図を理解することが重要になります。
既存のエージェント設計とベンチマークは、タスクが明確であることを前提としており、意図の汲み取りは評価対象に含まれていません。そこで研究者らは、タスクの曖昧さ判断や真の意図の理解を通じたエージェントの対話能力をテストするベンチマークを作成することにしました。
なお、これまでに行われてきた研究では、エージェント間のコミュニケーション・連携・評価のためのマルチエージェントフレームワークについて探求されてきました。しかし、エージェント設計におけるユーザーの役割についてはあまり重要視されてきていません。
下記では、新しいベンチマークの開発と、モデル「Mistral-Interact」の開発、そして性能評価結果について紹介します。まず、

