
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
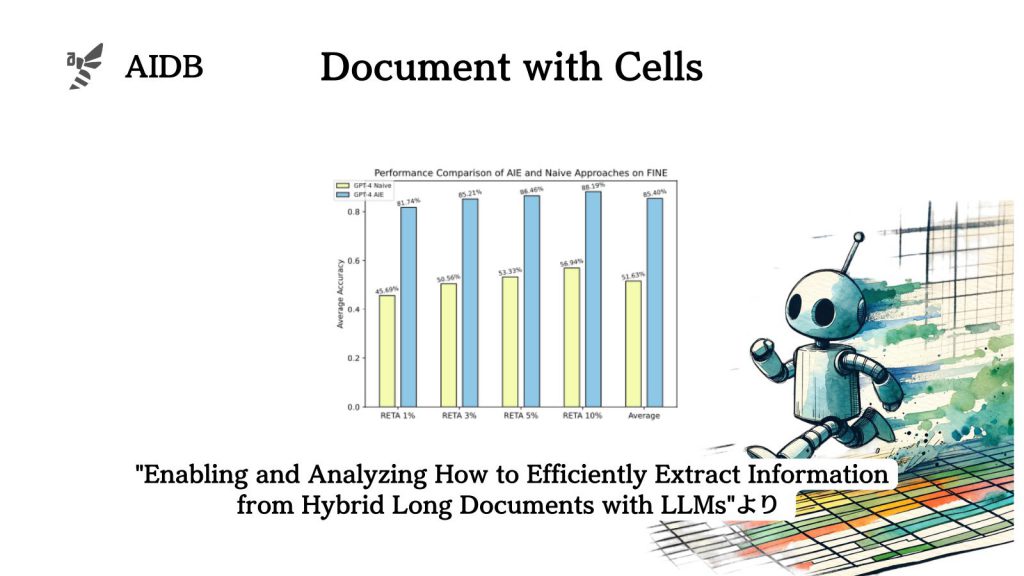
テキストと表の両方を含むハイブリッドな文書からLLMで情報を抽出する能力についてはまだ十分に研究されていません。そこで研究者らは、分割・再結合ベースの方法論を提案しています。実験により、抽出の精度が格段に上昇することを明らかにしました。
参照論文情報
- タイトル:Enabling and Analyzing How to Efficiently Extract Information from Hybrid Long Documents with LLMs
- 機関:Peking University, Microsoft, Institute of Software Chinese Academy of Sciences, University of Technology Sydney
- 著者:Chongjian Yue, Xinrun Xu, Xiaojun Ma, Lun Du, Hengyu Liu, Zhiming Ding, Yanbing Jiang, Shi Han, Dongmei Zhang
背景
LLMは、テキストデータの理解と処理、およびと表形式データの理解と処理において優れた性能を示しています。しかし、それらを組み合わせたハイブリッドドキュメントの処理については、まだ不十分です。
一方で、世の中の資料は表とテキストを同時に含む資料が非常に多くあります。
またハイブリッドドキュメントは多くの場合とても長い文書であり、LLMのトークン制限を大幅に超えています。
そこで今回研究者らは、LLMがハイブリッドかつ長文の文書を処理できるようにするために、分割・再結合ベースのフレームワーク『SiReF』を開発し、ハイブリッド長文文書からの情報抽出に関する実験を行いました。
- ドキュメントの有用な部分を選択・要約する効果的な方法
- LLMがテーブルを理解するための簡単なテーブルシリアル化方法
- 本ケースにおいて有用なプロンプトエンジニアリング
さらに実験のために金融レポートデータセットも構築しました。
以下では、手法の詳細に触れていきます。

