
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
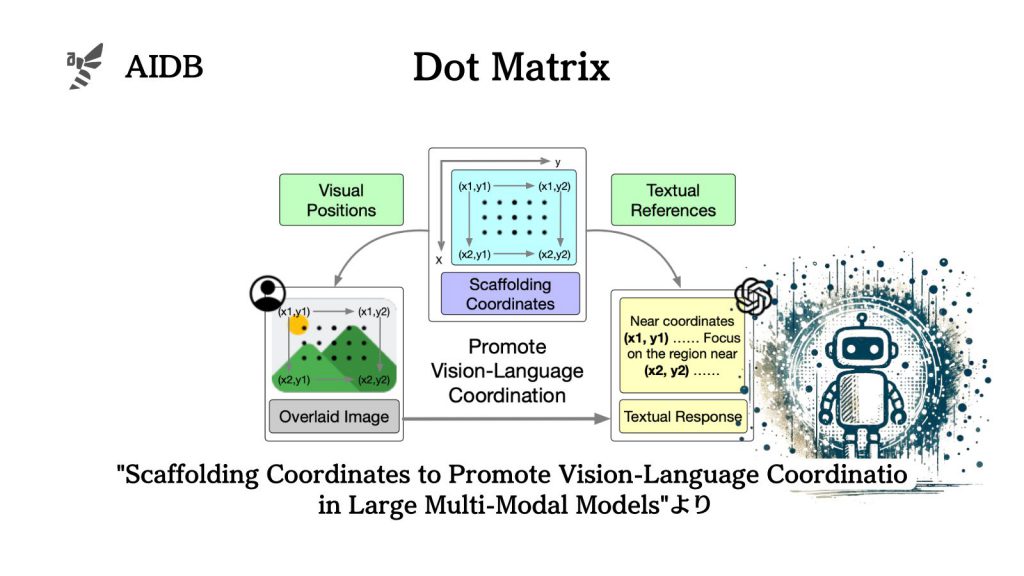
大規模マルチモーダルモデルは、複雑な推論が必要なタスクではまだまだパフォーマンスが限られています。そこで、画像上に点のマトリックスを重ね、各点に座標を割り当てることで精度を向上する手法『SCAFFOLD』が考案されました。
実験では空間推論、視覚的理解、幻覚の検出など、様々なベンチマークでSCAFFOLDの有効性が示されました。
参照論文情報
- タイトル:Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models
- 機関:Tsinghua University
- 著者:Xuanyu Lei, Zonghan Yang, Xinrui Chen, Peng Li, Yang Liu
背景
GPT-4Vなどの大規模マルチモーダルモデルは様々なタスクで優れた性能を示しています。言語モデルの高度な推論能力を活用し、現実のシナリオへの応用が期待されています。
しかし、現在は複雑な推論を行う際に性能が限られています。例えば、空間推論タスクでは、画像中の様々な情報源の関係を明らかにする必要があります。つまり、正確な視覚認識と言語理解のオーケストレーションが求められるのです。
マルチモーダルモデルのレベルを上げるためにこれまでに大きく2つのアプローチが取られてきました。
一つ目はInstruction Tuningで、高品質な画像テキストペアで追加学習する手法です。しかし、大量の計算リソースを消費するため、柔軟性に欠けます。
二つ目はPromptingで、Chain-of-Thoughtなどが代表例です。ただし、テキストpromptは探求されているものの、Visual promptingはあまり検討されていません。
今、シンプルで汎用的なVisual promptingの手法が求められています。そこで新たに考案されたのが『SCAFFOLD』です。
以下で詳細を紹介します。

