
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
入力テキストの長さの違いがLLM(大規模言語モデル)の性能に与える影響について調査が行われました。
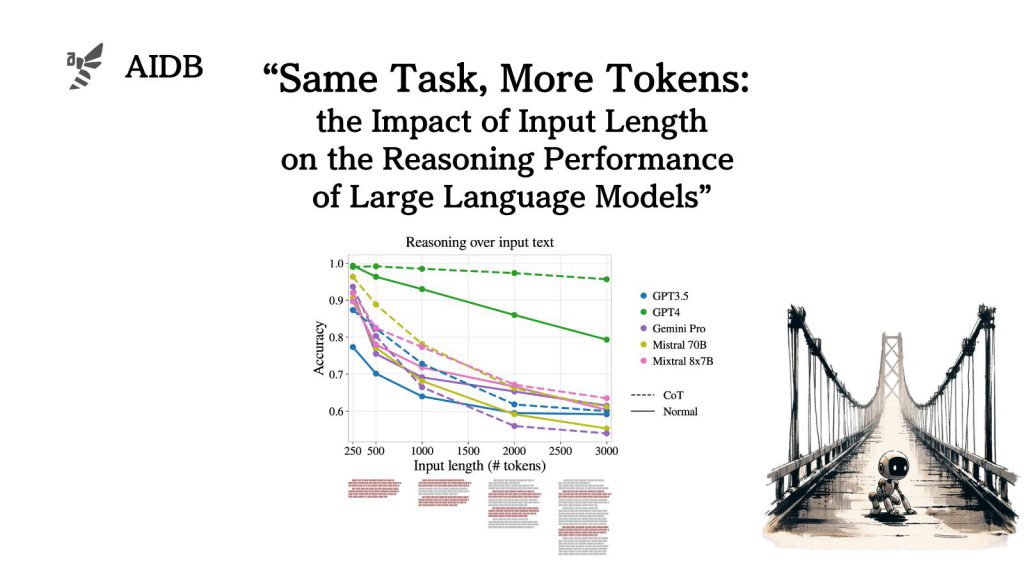
同一の質問に対して、長さ・種類・配置の異なる複数のプロンプトパターンを用意し、入力の長さの影響を検証した結果、LLMは技術上の最大入力長よりもかなり短い段階で推論性能が著しく低下する可能性が示唆されました。
この傾向はデータセットの種類に依らず、程度の差こそあれさまざまなモデルで一貫して見られました。
参照論文情報
- タイトル:Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
- 著者:Mosh Levy, Alon Jacoby, Yoav Goldberg
- 所属:Bar-Ilan University, Allen Institute for AI
背景
LLMは、複数の推論ステップを必要とするような複雑な質問に正しく答える能力も備わってきました。 また、技術的に対応できる入力テキストの長さも拡大してきています。そのため、長い入力に対しても一貫した性能を発揮するのかを検証する必要性が高まってきています。
ひとつの仮説(あるいは理想)として、長い入力テキストでも、短い質問形式でのタスクと同様の精度で推論処理ができる、ということが考えられていました。
推論を含む長い入力を扱うタスクでモデルをベンチマークする研究では、LLMが長い入力での推論に苦戦する傾向が示されています。ただし、これまでの研究では入力の長さだけでなくタスクそのものも変化させているため、性能低下の原因が長い入力にあるのか、タスクの難易度によるものなのか切り分けができていませんでした。
そこで今回、研究者らは、その他の条件を可能な限り一定に保ちながら、入力の長さを変動させた場合のモデル性能への影響を調査することにしました。基本的なタスクは固定しながら、入力の長さのみを操作して、性能の変化傾向を検証します。
結論から先に言うと、入力テキストが長くなるほど推論性能は下がってしまう傾向が示唆される結果となりました。
なお実験では、長い入力に対するLLMの「次の単語を予測する性能」と、推論タスク性能の関係も調査されています。さらには、Chain-of-Thought(CoT)プロンプティングの影響も検証されています。また、分析結果からモデルの応答におけるいくつかの不具合モード(要するに失敗のパターン)も特定されています。
以下では、検証されたタスク、実験結果、そして失敗パターンの中身についてなど、論文内容を詳しく紹介しています。

