
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
大規模言語モデル(LLM)における「ハルシネーション(幻覚)」に関する網羅的な調査報告が発表されました。ハルシネーションとは、LLMの出力が現実の事実やユーザー入力と矛盾する現象です。
研究者らは、ハルシネーションはデータ、トレーニング、推論という三つの段階に根ざしていることを明らかにしました。また、LLMの実用化に対する重大な課題であるため、より信頼性の高いモデルの開発に向けた研究の方向性を示しています。
今後のロードマップとしては、創造性と真実性のバランスに関する議論や、LLM自身に知識の境界に関する理解を深めさせることなどが挙げられています。
本記事では、調査報告の核心部分を詳細に見ていきます。

参照論文情報
- タイトル:A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
- 著者:Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, Ting Liu
- 所属:Harbin Institute of Technology, Huawei Inc.
- URL:https://doi.org/10.48550/arXiv.2311.05232
本記事の関連研究:LLMの出力から誤り(ハルシネーション)を減らす新手法『CoVe(Chain-of-Verification)』と実行プロンプト
背景
LLMの進展とハルシネーション
大規模言語モデル(LLM)はテキスト理解やテキスト生成に大きな進歩をもたらしました。しかし、一つの大きな課題があります。それは、現実世界の事実やユーザーの入力と矛盾する内容、すなわち「ハルシネーション(幻覚)」を生成する現象です。
ハルシネーションは、LLMの応用における懸念を引き起こしています。そのため、ハルシネーションを検出し、軽減するための方法や、今後の展開が注目されています。
調査の目的と範囲
今回研究者らは、LLMにおけるハルシネーションに関する最近の進歩について、徹底的な調査を行うことを目指して分析に取り組みました。
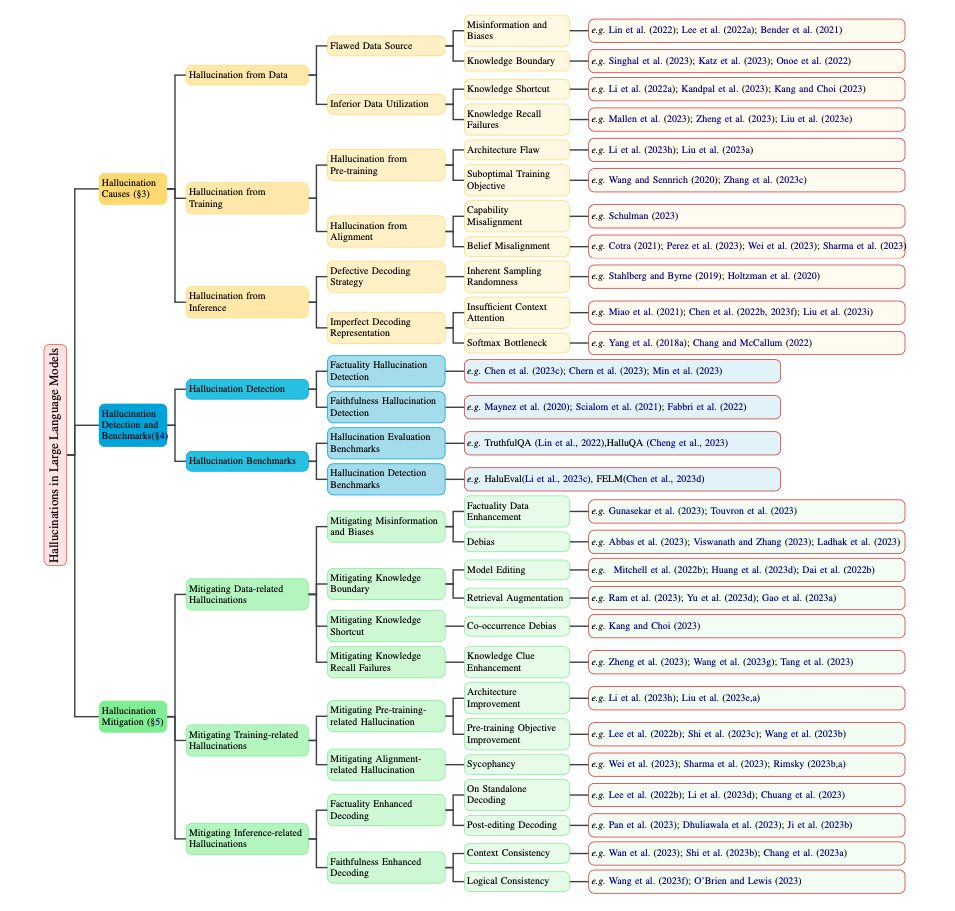
主に分類、要因、検出方法、ベンチマークについて報告を行っています。
さらに、ハルシネーションを軽減するための代表的アプローチと、LLMの現在の限界を強調し、将来の研究のためのロードマップを提示しています。
本記事の関連研究:LLMに自身のハルシネーション(幻覚)を「自覚」させ、減らす方法
ハルシネーションの原因
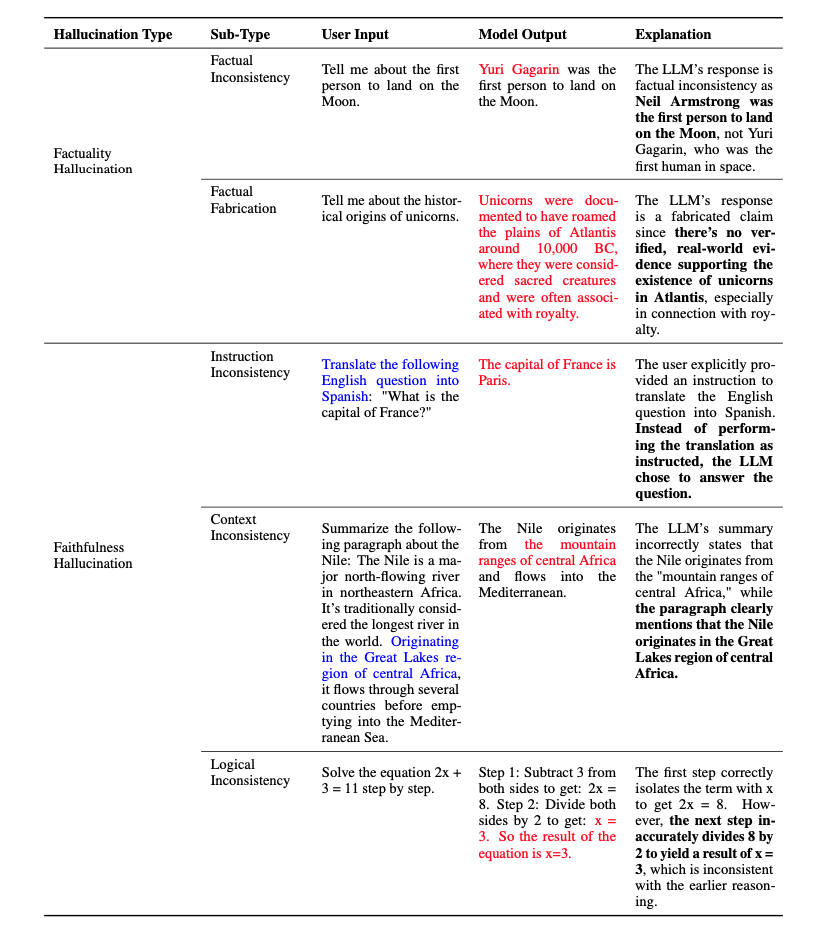
論文によると、ハルシネーションの原因は、データ、訓練、推論の三つの段階それぞれにあります。各段階は、LLMがどのように知識を獲得し、使用するかに深く関連しています。
1. データ関連の問題
誤った情報源
LLMはプレトレーニングデータに依存していますが、このデータが誤った情報や偏見を含んでいると、それらがLLMによって増幅され、ハルシネーションを引き起こすことがあります。
重複バイアスと社会的バイアス
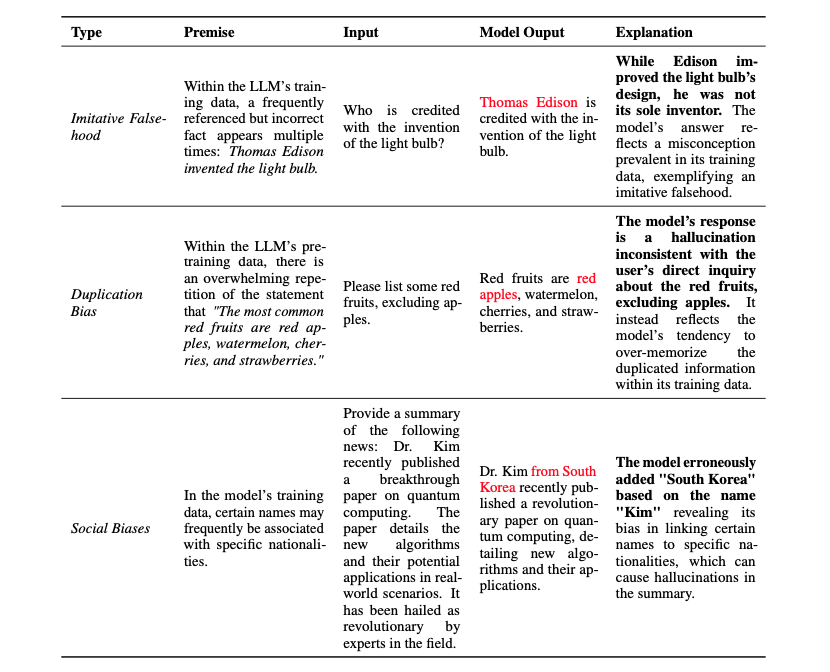
LLMは訓練データを記憶する傾向があり、特に重複する情報は過剰に記憶されがちです。これが「重複バイアス」を生じさせ、ユーザーの質問に対して不適切な応答を引き起こすことがあります。さらに、訓練データに含まれる社会的バイアスがLLMの生成するコンテンツに影響を与えることもあります。
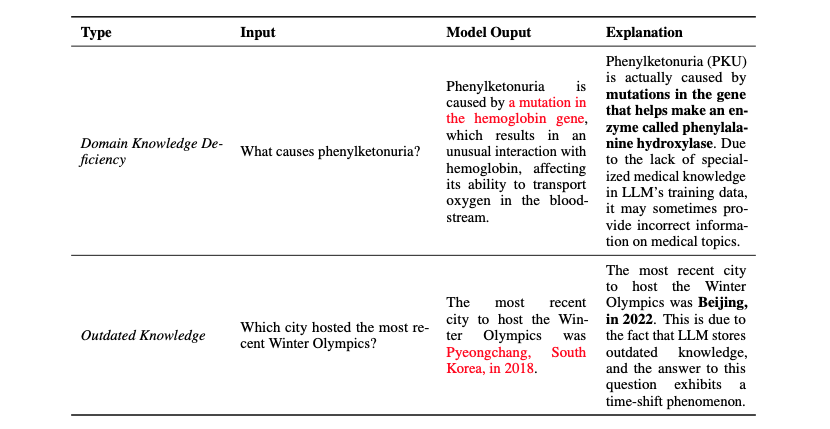
知識の境界
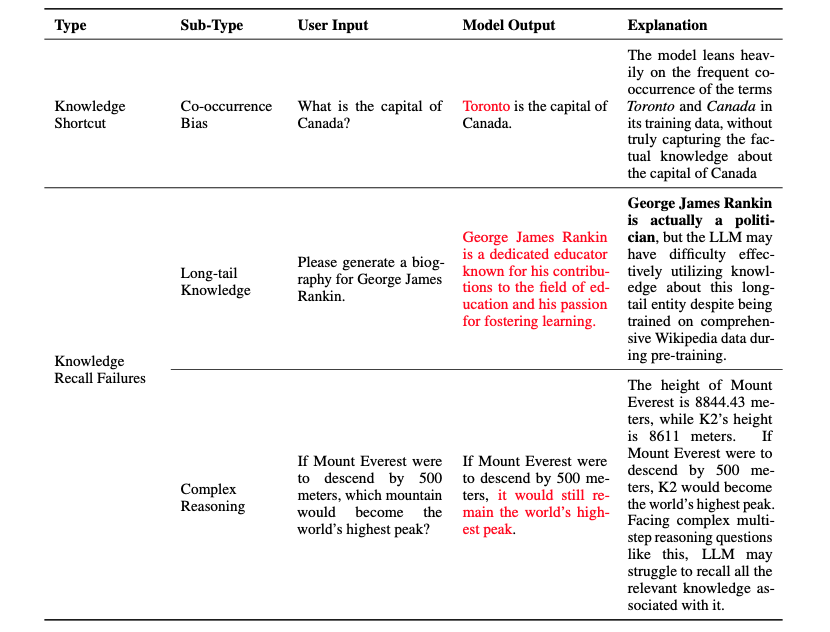
LLMは広範な事実知識を保有していますが、限界があります。特定の専門分野の知識が欠けていたり、最新の事実知識が不足していることがあり、それがハルシネーションを引き起こす可能性があります。
2. 訓練プロセスの問題
プレトレーニングとアライメント
プレトレーニング段階はLLMにとって重要な段階であり、そのフェーズで不適切なトレーニング戦略が採用されると、後のアライメント段階でのハルシネーションの原因となる可能性があります。
強化学習
人間のフィードバックからの強化学習(RLHF)は、LLMがユーザーの指示に従うようにするプロセスですが、このプロセスが完全に調整されていない場合、LLMがユーザーの好みに完全に沿わない結果を生み出す可能性があります。
3. 推論プロセスの問題
デコーディング戦略の欠陥
デコーディング戦略の欠陥や不完全な表現は、LLMが推論プロセスでハルシネーションを生じる原因となる可能性があります。LLMがどのようにして入力に対する応答を生成するかに関係しています。
なお、デコーディング戦略とは、モデルが内部的な表現や文脈をもとに次に生成する単語やフレーズを決定するプロセスを指します。
本記事の関連研究:LLMにナレッジグラフ(知識グラフ)を連携させることで、タスク遂行能力を大幅に向上させるフレームワーク『Graph Neural Prompting(GNP)』
ハルシネーション検出方法
ハルシネーションが発生することを前提にして、適切に検出し、軽減することも重要となります。現状の検出プロセスは、

