
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
Metaとニューヨーク大学は、LLMが自ら自分自身に報酬を与える「自己報酬言語モデル」を開発したと報告しています。
実験では、同社が開発したオープンソースモデルLlama 2 70Bに自己報酬フレームワークを適用し、クローズドの優秀なモデルであるClaude 2、Gemini Pro、GPT-4などをある側面から凌駕する結果が得られているとのことです。
本記事では研究背景、フレームワークの内容、実験と結果、そして最後に結論と重要な注意点を紹介します。
参照論文情報
- タイトル:Self-Rewarding Language Models
- 著者:Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, Jason Weston
- 所属:Meta, NYU
- URL:https://arxiv.org/abs/2401.10020
研究背景
現在の主要なLLMは、人間のフィードバックに基づいて訓練されています。Reinforcement Learning from Human Feedback (RLHF) と呼ばれる手法が主流です。
RLHFは、人間の好みに基づいて固定された報酬モデルを訓練し、強化学習(例えばPPO)を使ってモデルを訓練する手法です。なお、直接嗜好最適化(DPO)など、報酬モデルの訓練を避け、直接人間の好みを使うアプローチもあります。
このアプローチは安全かつ有効にモデルを学習できる一方で、人間の好みによって制限される可能性があり、報酬モデルの品質も問題となることがあります。つまり、モデルの能力が人間の理解や判断の範囲内に留まる恐れがあります。
また報酬モデル自体は訓練後には通常「凍結」され、その後は改善や更新が行われません。このことが、モデルの進化や、新しい情報に対して障壁になります。
これらの課題から、Metaとニューヨーク大学の研究者らは自動学習能力を持つLLMを開発する必要があると考えました。
以下ではフレームワークと実験結果、また注意点を詳しく紹介します。
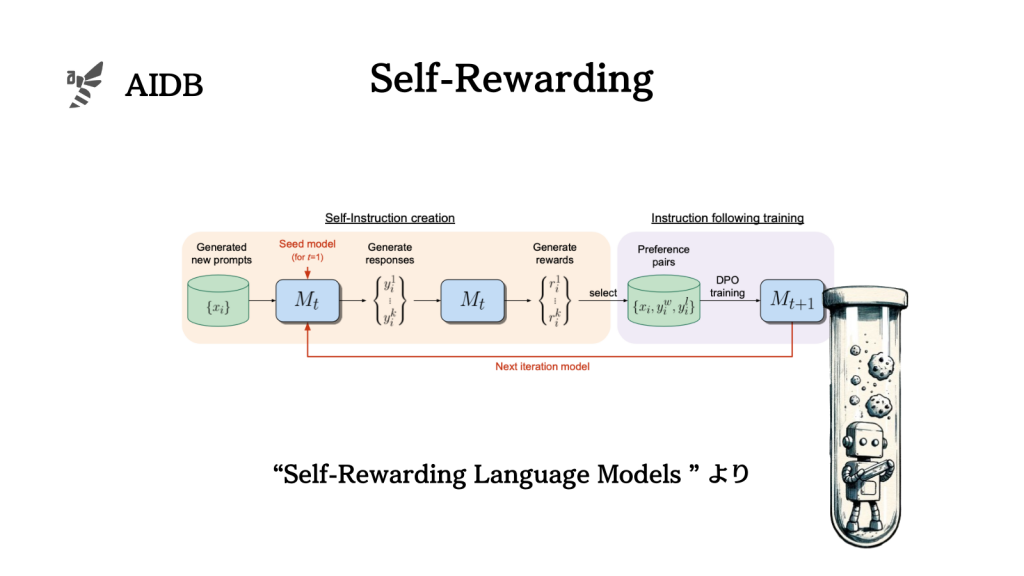
自己報酬言語モデルのフレームワーク
研究者たちは、

