ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
言語は常に変化している一方で、LLMは定型的なデータセットに基づいているため、モデルが新しい言葉の意味を知る機会は通常、自動的には発生しません。
そこでカリフォルニア大学などの研究者らは、LLMを継続的に再学習するコストをかけず、新しい言葉の概念をLLMに理解させる方法を考案しました。さらに評価ベンチマーク「SLANG」を導入しています。
現実世界の言葉の変化を捉え、それらを手がかりに新しい表現とその意味を正確に結びつけます。実験結果から、従来の手法よりも精度と関連性の面で優れていることが示されました。

参照論文情報
- タイトル:SLANG: New Concept Comprehension of Large Language Models
- 機関:CAS Key Laboratory of AI Security Institute of Computing Technology Chinese Academy of Sciences, University of California Los Angeles, University of Chinese Academy of Sciences
- 著者:Lingrui Mei, Shenghua Liu, Yiwei Wang, Baolong Bi, Xueqi Cheng
背景
近年、ウェブの発展の影響もあって言葉の変化が加速し、新たな形で言葉が変化するようになっています。こうした急速な変化は、大規模言語モデル(LLM)が新しい概念を理解する上で大きな課題となっています。通常、LLMは静的なデータで学習しているため、常に変化する言語に適応することは簡単ではありません。
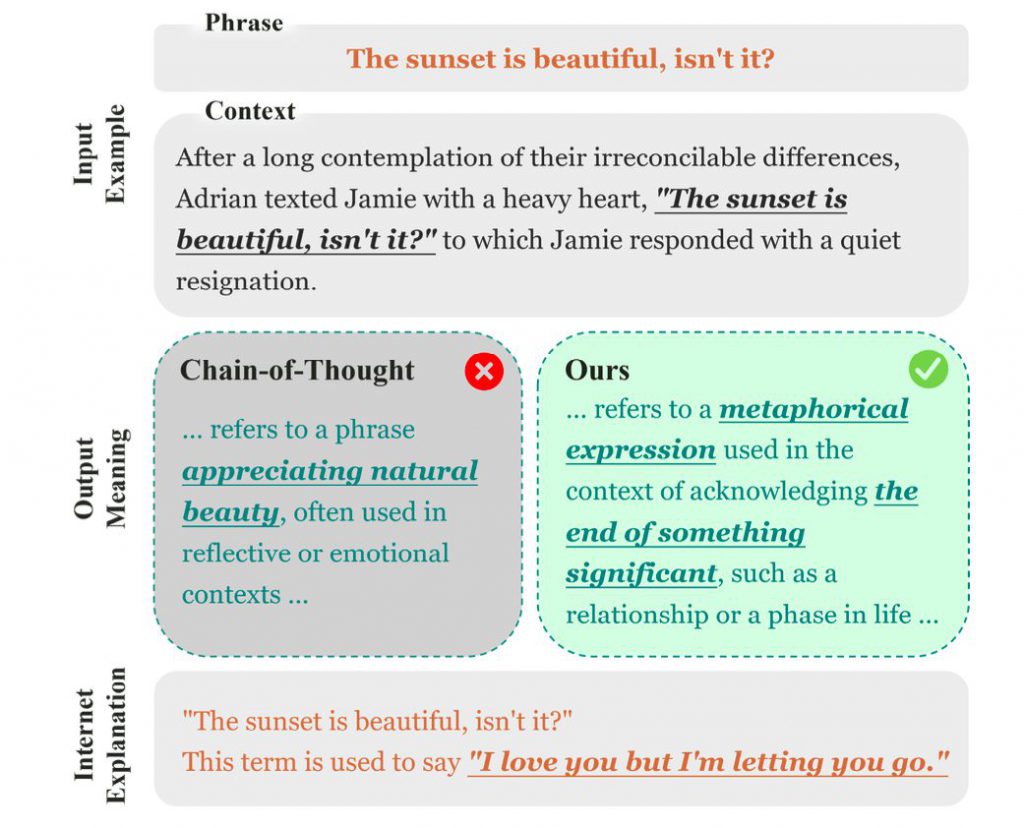
また、LLMは往々にして表面的なパターンに基づいて判断を下し、根拠のある推論ができていません。例えば、Chain-of-Thought (CoT) プロンプティングでは、「The sunset is beautiful, isn’t it? (夕日がきれいですね)」というフレーズを単純に解釈してしまい、複雑な会話の中で「物事の終わり」の象徴など、より深い隠喩的な意味を見逃してしまう可能性があります。
既存の知識更新技術としては、パラメータの微調整(ファインチューニング)が一般的です。しかし、計算コストの問題、タスク固有の性能低下といった課題があります。また、データセットの質への依存性も指摘されています。また、外部情報の取得を活用する方法(RAG)では、深い理解よりも事実の検索に重きが置かれています。
そのため、継続的なアップデートや外部データ無しに、LLMが言葉の変化や新しい概念を理解できるようになることが重要です。
そこで研究者らは、言語変化へのLLMの適応力を評価するベンチマーク「SLANG」と、新しい概念理解を促進する因果推論に基づくアプローチ「FOCUS」を提案しています。