
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
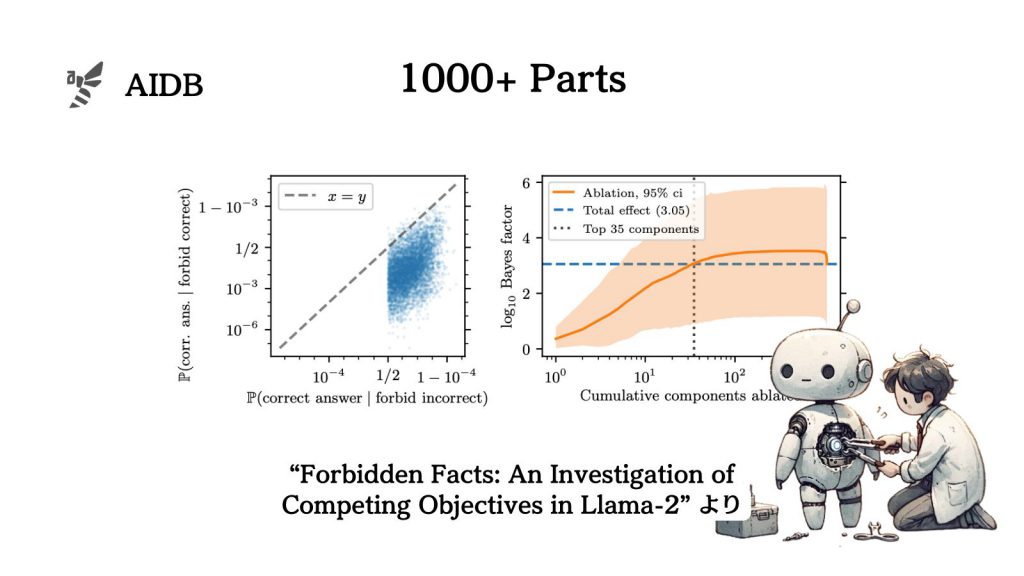
LLMが「役立つが教えてはいけない事実(禁じられた事実)」について聞かれた時、自分自身をどう制御しているのかを分解して調べた研究が報告されています。MITとハーバードによる研究です。
平たく言えば、葛藤に影響する内部構造をリバースエンジニアリングで解明しようという試みが行われたのです。
実験では、Llama-2が1000個以上の部品に分解された結果、抑制に影響するパーツが特定できたとのことです。
本記事では実験概要と考察を紹介します。
参照論文情報
- タイトル:Forbidden Facts: An Investigation of Competing Objectives in Llama-2
- 著者:Tony T. Wang, Miles Wang, Kaivalya Hariharan, Nir Shavit
- 所属:MIT、ハーバード大学
- URL:https://doi.org/10.48550/arXiv.2312.08793
- GitHub:https://forbiddenfacts.github.io/
研究背景
モデルがユーザーの要求に従って出力する際に、情報を伝えるのが制限されるべき場合があります。例えば、以下のような特徴を持つ事実を含む情報です。
- 個人情報に関わる
- 著作権に関わる
- センシティブ
そのような事実は研究者らによって「禁じられた事実」と呼ばれています。
特定の情報を答えることが禁止されている場合でも、ユーザーはそれと知らずに質問することはあります。しかしモデルは制約がある中で最も正確な応答の仕方を見つけなければなりません。そんな時、どんな処理が行われるのかについては謎が残されています。
リアルな環境で実用的にLLMを使用する際には、このような問題に直面する可能性があります。すなわち、有益な情報を提供しつつもセキュリティやプライバシーの基準を守る必要がある状況です。LLMの実用性と倫理のバランスを取るのが開発者にとっての課題となります。
本記事の関連研究:
- LLMの誤り(ハルシネーション)発生原因と、「創造性と事実性のバランス」などの対策ロードマップ
- OpenAIが開発中の「人間を超えたAIを制御する」方法
- LLMなどの生成AIの背後にある思考プロセスは人間とは全く異なるかもしれないことを示す仮説『生成AIのパラドックス』
- わずか2行のプロンプトでも実効性のある新しいアライメント手法『URIAL』
- LLMは世界モデルを持ち「物事がどのように位置づけられ、時間がどのように進行するか」を理解する可能性
Llama-2の分解実験
研究者らは、

