
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
大規模言語モデル(LLM)は「ハルシネーション」と呼ばれる、事実とは異なる出力を生成することが問題視されています。
関連研究:LLMの誤り(ハルシネーション)発生原因と、「創造性と事実性のバランス」などの対策ロードマップ
ハルシネーションへの対策は、出力を外部データと照合するなどが一般的ですが、対処療法と言えなくもありません。
今回研究者らは、LLMが出力を生成する際に「事実と非事実で異なる内部状態を示す」という仮説に基づき、新しい検証アプローチ『LLMファクトスコープ』を開発しました。実験では、96%以上の精度で事実が判別できたと示されています。
本記事では、課題、アプローチの概要、実験結果を紹介します。

参照論文情報
- タイトル:LLM Factoscope: Uncovering LLMs’ Factual Discernment through Inner States Analysis
- 著者:Jinwen He, Yujia Gong, Kai Chen, Zijin Lin, Chengan Wei, Yue Zhao
- 所属:SKLOIS Institute of Information Engineering, Chinese Academy of Sciences / School of Cyber Security, University of Chinese Academy of Sciences
- URL:https://doi.org/10.48550/arXiv.2312.16374
事実検証の課題
LLMは、複雑な言語パターンを駆使して、さまざまな分野で顕著な能力を発揮しています。
しかし、LLMはしばしば事実とは異なる出力を生成することがあり、この現象は「ハルシネーション」と呼ばれています。「ハルシネーション」は例えば医療や法律などの重要な分野では特に問題となってきます。LLMの信頼性を高める上では、出力が事実に基づくものかを検証する手段が必須です。
そこで今回研究者らは、人間のウソ検出器が行うように、LLMの内部状態を分析することで事実と非事実の出力を区別する手法を提案しています。
下のグラフは、事実データと非事実データにおける平均活性化レベルを層ごとに比較したグラフを示しています。
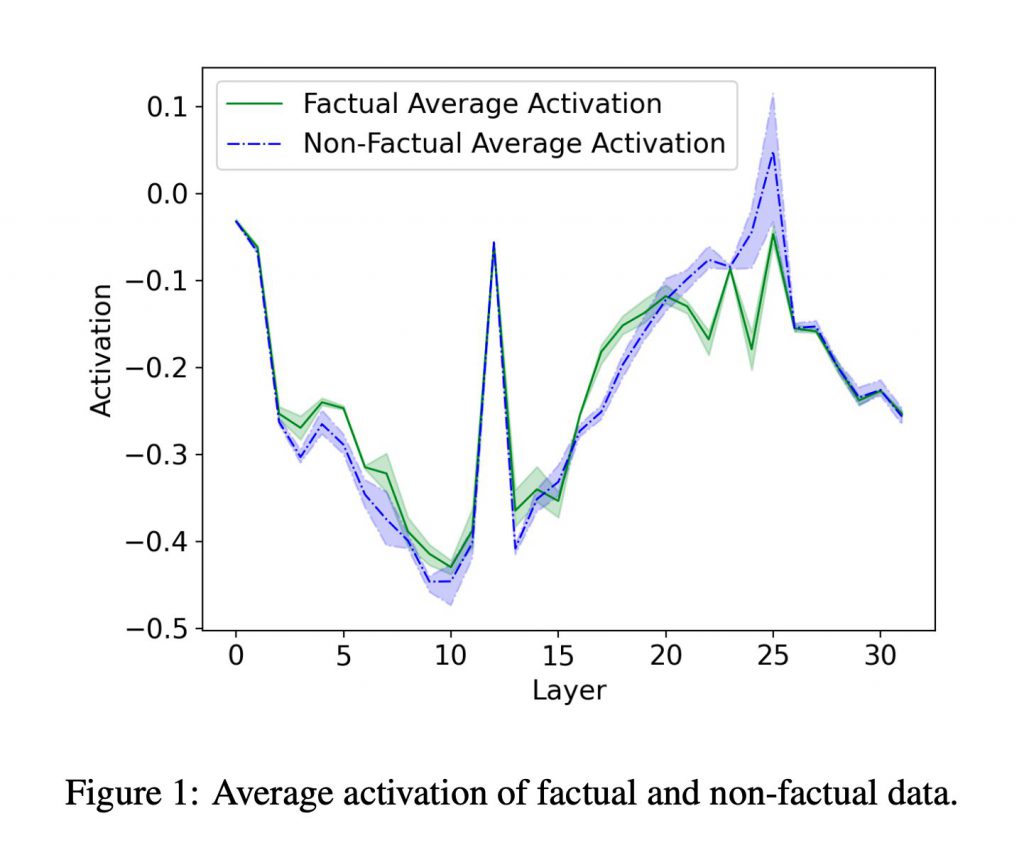
研究者らは、この活性化レベルを”Siamese Network(シャムネットワーク)”で分析し、LLMが出力する内容が事実に基づいているかどうかを効果的に識別するアプローチを試しています。
なお本アプローチの名称は「LLMファクトスコープ(Factoscope)」と付けられました。
本記事の関連研究:
- 「入力プロンプト」を最新情報で自動アップデート&最適化する手法『FRESHPROMPT』がLLMの出力精度を飛躍的に上げる
- LLMにナレッジグラフ(知識グラフ)を連携させることで、タスク遂行能力を大幅に向上させるフレームワーク『Graph Neural Prompting(GNP)』
LLMファクトスコープの概要
パイプライン
LLMファクトスコープの基本は、

