
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
大規模言語モデル(LLM)は常に最新の知識を知っているわけではなく、時には古い情報や不正確な情報を元に回答することがあります。この問題に対処するため、Google、マサチューセッツ大学、OpenAIの研究者たちが手法開発を行いました。
研究者らが開発したのは、検索エンジンからの情報を効果的に組み込むことで、入力プロンプトを最新の情報で強化する新しいアプローチ「FRESHPROMPT」(フレッシュプロンプト)です。ChatGPT(GPT-4、GPT-3.5など)などのLLMの回答品質を大幅に向上させることが検証できたと言われています。
理屈はシンプルですが、最新情報を自動的に探索し、整理し、入力プロンプトを最適化する非常に便利な技術です。
この記事では、FRESHPROMPTとその背後にある技術、さらには新しいQAベンチマーク「FRESHQA」について紹介します。性能検証結果や、この技術の応用における注意点についても触れていきます。

参照論文情報
- タイトル:FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
- 著者:Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, Thang Luong
- 所属:Google, University of Massachusetts Amherst, OpenAI
- URL:https://doi.org/10.48550/arXiv.2310.03214
- GitHub:https://github.com/freshllms/freshqa
本記事の関連研究:LLMに自身のハルシネーション(幻覚)を「自覚」させ、減らす方法
背景
LLMの「ハルシネーション」問題
大規模言語モデル(LLM)は、現代のAI技術において重要な位置を占めています。しかしLLMは、一度学習されると通常はしばらく更新されません。そのため、我々の絶えず変化する世界に対応するための動的な適応能力を欠いています。
この問題点は、LLMが生成するテキストの事実性(信頼性)に影響を及ぼします。例えば、最新の世界情報を知るための質問に答える際、流動的に変化していく知識や事実に基づく回答には苦戦します。
LLMは、そのハイパフォーマンスな能力にもかかわらず、しばしば事実と異なる情報(ハルシネーション(幻覚))を生成することがあります。モデルが、エンコードされた古い知識に(部分的に)依存しているために生じる現象です。精度が重要な場面では、誤った情報はモデルの信頼性を損なう恐れあります。
検索エンジンとの連携
最近では、LLMをウェブ検索結果で拡張する試みが行われていますが、LLMの事実性を最大限に向上させる方法については、まだ明確ではありません。
また人間のフィードバックを用いた追加トレーニングや知識強化タスクを通じて、問題を軽減することも可能ですが、リアルタイムの知識更新にはまだ課題があります。
このような背景から、LLMのプロンプトにリアルタイムの知識を注入する「文脈内学習(インコンテキストラーニング)」が注目されています。
本記事の関連研究:LLMにナレッジグラフ(知識グラフ)を連携させることで、タスク遂行能力を大幅に向上させるフレームワーク『Graph Neural Prompting(GNP)』
『FRESHPROMPT』の主なポイント
上記のような課題に対処するための新しいアプローチ「FRESHPROMPT」について詳しく見ていきます。
『FRESHPROMPT』は、大規模言語モデル(LLM)の応答品質を向上させるために開発された新しいアプローチです。ユーザーの指示や質問プロンプトに関連する最新情報を検索エンジンから取得し、その情報を整理してプロンプトに反映させることで、LLMの回答の事実性を高めることを目的としています。
取得した情報をソース、日付、タイトル、テキストスニペット、ハイライトされた単語を含む統一フォーマットに整理し、質問ごとの例と関連する証拠とその推論を示す数ショットデモンストレーションをプロンプトの冒頭に提供するものです。(下図がイメージ)
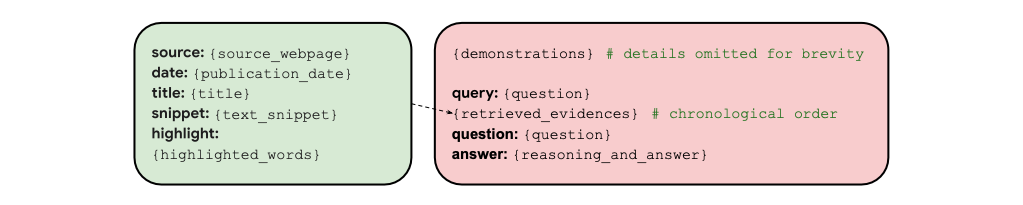
情報取得プロセス
1. ユーザーの指示/質問プロンプトに関連する情報の検索
FRESHPROMPTは、ユーザーから提供される質問や指示に関連する情報を検索エンジンで自動探索します。
2. 検索結果からの情報抽出
検索エンジンから得られた結果から、関連する情報を自動で抽出します。このステップでは、回答に必要なデータや事実を特定し、選定する作業が行われます。
3. 情報リストの作成
抽出された情報を基に、回答に役立つ情報のリストを自動で作成します。LLMが質問に答える際の参考資料となります。
3. プロンプトへの情報反映
最後に、作成した情報リストをプロンプトに自動で組み込みます。その結果、LLMは最新の情報を基に回答を生成することができるようになります。
目的とされる効果
FRESHPROMPTの主な目的は、LLMが生成する回答の事実性を高めることにあります。現在のLLMは、古い知識に基づいて回答することがあり、特に正確で最新の情報が重要な場面では、その信頼性が問題視されています。FRESHPROMPTは、このような課題に対処し、LLMの回答品質を全体的に向上させることを目指しています。
本記事の関連研究:LLMにまず前提から尋ることで出力精度を向上させる『ステップバック・プロンプティング』と実行プロンプト
FRESHQA
FRESHPROMPTを活用して構築された新しいQAベンチマーク「FRESHQA」について掘り下げていきます。


FRESHQAの目的と特徴
FRESHQAは、LLM(大規模言語モデル)が生成するテキストの事実性を詳細に評価するために開発された(革新的な)動的QAベンチマークです。ベンチマークには、現在の世界に対する知識をテストするための多様な質問と回答のタイプが含まれています。スピーディーに変化していく知識が必要な質問や、性能を確かめるためにあえて作成された「事実上間違った前提を持つ質問」に焦点が当てられています。
評価方法
FRESHQAは、クローズドおよびオープンソースのLLMを多様な方法で評価します。二つの評価モードが含まれ、「回答の正確性」と「ハルシネーション」(事実でない情報の生成)を測定します。この評価方法を通じて、モデルの限界が明らかにされ、改善の余地が示されます。例えば、モデルサイズに関わらず、全てのモデルはスピーディーに変化していくタイプの知識や偽前提の質問に対応するのに苦労しています。
人間による評価
FRESHQAのクオリティーは、多数の人間によって実施された50,000件以上の評価で行われました。非常に広範なデータセットと多数の評価ポイントが考慮されていることを意味します。FRESHQAはLLMを効果的に評価し、その性能の限界と改善の余地を明らかにすることが保証されています。
継続的な進化
FRESHQAは、業界の研究を促進するために公開されており、定期的にアップデートされる予定です。LLMのパフォーマンス向上に向けたさらなる研究や開発がこのベンチマークを活用して行われることが期待されています。
本記事の関連研究:LLMの出力から誤り(ハルシネーション)を減らす新手法『CoVe(Chain-of-Verification)』と実行プロンプト
検索結果から抽出される情報
検索結果から抽出される情報と、それがFRESHPROMPTにどのように統合されるかについて見ていきます。

