
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事では、新たな評価手法として注目される「LLM-as-a-judge」を紹介します。一言でいうとLLM自身を評価者として活用する分野です。
従来の評価指標は、自由度の高いシナリオへの対応が困難でしたが、LLMを評価者とすることでより詳細で柔軟な評価が可能となると期待されています。
本稿では、この新しいアプローチの可能性と課題について、最新の研究動向をもとに紹介していきます。

背景
人工知能および自然言語処理の分野では、評価・判定が常に重要な課題とされています。品質、関連性、有用性などを評価するさまざまな手法の開発がこれまでに取り組まれてきました。
既存の評価手法としては、BLEUやROUGEといった指標が広く使用されてきました。出力テキストと参照テキスト間の単語の重なりを計算することで品質を測定する手法です。計算効率は良いものの、動的で自由度の高いシナリオへの適用が困難という欠点もあります。また、参照テキストに基づく評価手法であるため、複数の正解が存在する場合への対応にも限界があります。
一方で、深層学習モデルの発展に伴い、意味の埋め込みベースの評価手法も登場してきました。こちらは単語レベルでの評価と比較するとより柔軟です。しかし、有用性や安全性といった微妙な属性の評価には依然として課題が残されています。
このような状況の中、LLMが急速な発展を遂げ、指示への従順性、クエリの理解能力、応答生成能力が大幅に向上しました。これで評価手法に新たな可能性が開かれ、LLMを活用して候補群に対するスコアリング、ランキング、選択を行う「LLM-as-a-judge」というパラダイムが訪れようとしています。従来の評価手法の限界を克服し、より詳細で粒度の細かい判定を可能にすることが期待されています。
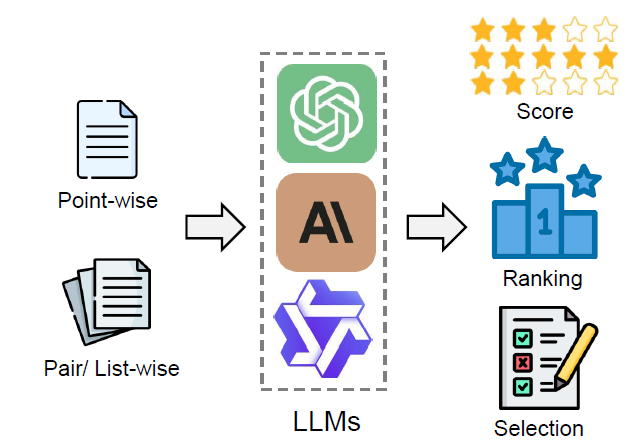
しかし、LLM-as-a-judgeにもまだ課題があります。判定におけるバイアスや脆弱性の問題などを包括的に理解し、解決策を見出すことが必要です。そこで今回研究者らは、現在のLLM-as-a-judgeの技術を体系的にレビューし、将来の研究課題を整理することに取り組みました。

