
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
Googleなどの研究者により、表形式(.csvなど)のデータを通してLLMが「連鎖的な推論」を行うためのフレームワークが考案されました。ユーザーがプロンプトによってLLMに表データを段階的に更新させ、表データの正しい理解に基づいた回答を引き出します。
複数のベンチマークで最高スコアを達成したと報告されています。
本記事では手法の概要や実験結果などを紹介します。
本記事の関連研究:LLMのRAG(外部知識検索による強化)をまとめた調査報告
参照論文情報
- タイトル:Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding
- 著者:Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Martin Eisenschlos, Vincent Perot, Zifeng Wang, Lesly Miculicich, Yasuhisa Fujii, Jingbo Shang, Chen-Yu Lee, Tomas Pfister
- 所属:University of California San Diego, Google Cloud AI Research, Google Research
- URL:https://doi.org/10.48550/arXiv.2401.04398
背景
多くの日常的な仕事で表データを使用する場面は多く、作業の効率化は常に求められています。表データに関わる作業の中で、事実検証などはこれまでの一般的な技術ではできないと考えられてきました。そんな中、言語モデルの性能が著しく進化したことで、表データの処理もさらに発展することが期待されるようになっています。
LLMに表データを深く理解させるアプローチは2通りあります。
一つは表データを理解できるように特化したトレーニングを行う方法です。たとえば、先行研究ではSQLクエリと応答のペアに関するデータでの事前学習などが試されています。
関連記事:LLMベースの新しい言語『SUQL』が示唆する「非構造化データのクエリ」を処理するパラダイム
もう一つは、プロンプトエンジニアリングを工夫し、基盤モデルの能力を引き出して表データをうまく扱わせる方法です。これまでに提案されてきた有力なプロンプトエンジニアリング手法としては、CoT(Chain of Thought)や最小最大プロンプト、Tree of Thoughtなどが挙げられます(※こちらの記事で詳しく取り上げています:ChatGPTの効果的なプロンプト手法における「基本のキ」を理論とテンプレート両方で紹介)。しかし、表データを介した複雑な推論を行うことは既存のプロンプトエンジニアリング手法では実現されていないといいます。
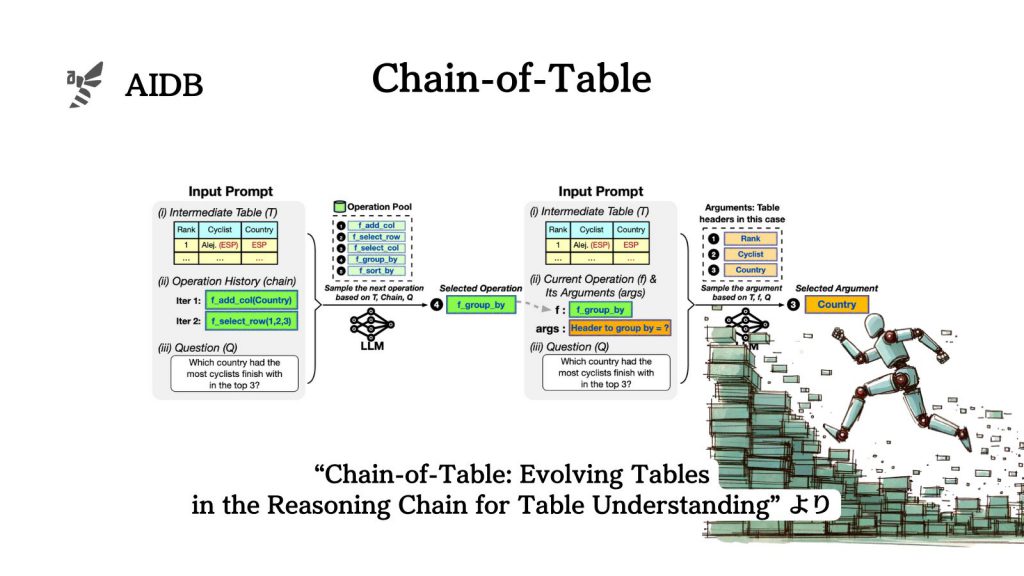
そこで研究者らは、表データの操作を通してLLMにステップバイステップの推論を行わせデータに対する深い理解を促すChain of Tableを考案しました。手法の詳細は後述しますが、コンセプトの核心はCoTと類似しています。Chain of Tableでは、表データの編集を繰り返す中で思考の連鎖が紡がれていくといいます。
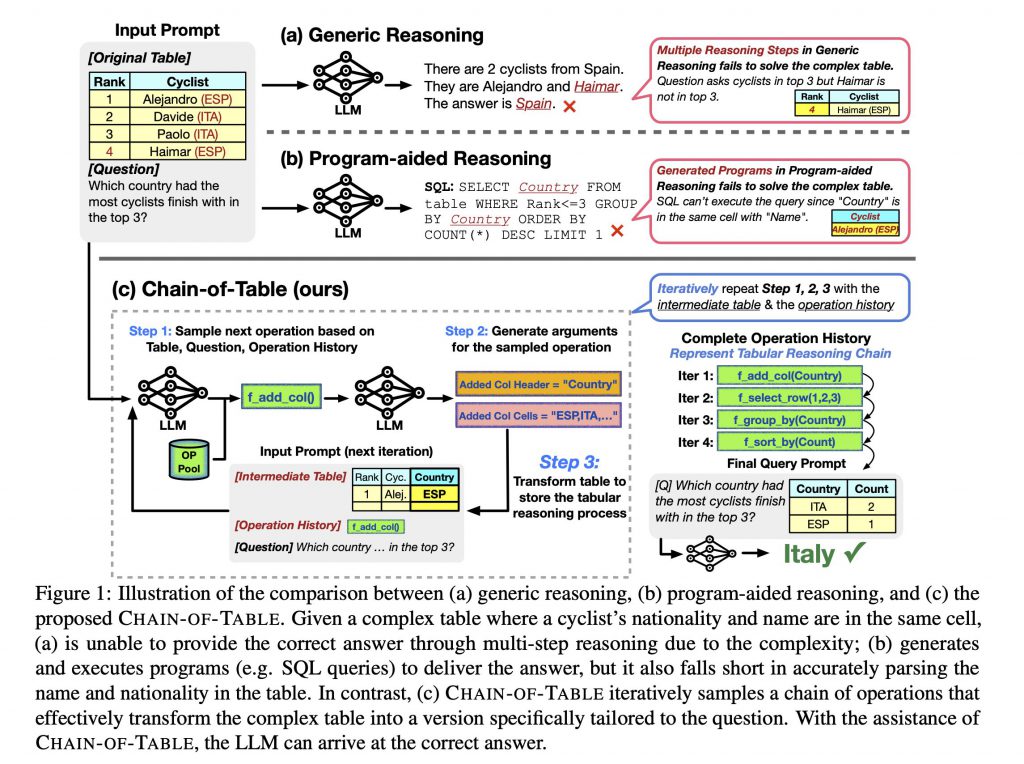
上の図は、本論文で提案される手法によってLLMが複雑な表を正しく解釈し、正確な答えを得るまでの流れを示しています。
本記事の関連研究:LLMの情報抽出(文章から必要な事柄を読み取る)タスクについての網羅的な調査結果
Chain of Tableの手法
全体の流れ
Chain of Tableにおいて、

