
ChatGPTなどのLLMは、自然言語を理解し、人間のように対話する能力を持っており、多くの場面でその能力を発揮しています。しかし、これらのモデルが最大限のパフォーマンスを発揮するためには、適切なプロンプト(指示テキスト)を使用することが不可欠です。
本記事では、ChatGPTをはじめとするLLMの効果的なプロンプト手法に焦点を当てた論文をもとに、「基本のキ」を紹介します。モデルに、より正確かつ効果的な回答を引き出すための原則と、現時点での主要なプロンプトエンジニアリングの知見を整理しました。
参照論文情報
・タイトル:Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
・著者:Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, Shengxin Zhu
・所属:BNU-HKBU United International College, Beijing Normal University
・URL:https://doi.org/10.48550/arXiv.2310.14735
本記事の関連研究:LLMに非線形的な思考を与えてCoTを上回る性能を引き出す手法『IEP』と実行プロンプト CoTと組合せでさらに強力になる場合も
従来の課題や背景
“プロンプト”に対する関心の高まり
大規模言語モデル(LLM)の登場は、人工知能技術における一大転換点となりました。膨大なデータセットから学習し、人間との対話を可能とし、多くの応用分野においてその価値を証明しています。
しかし、LLMがポテンシャルを発揮するためには、適切なプロンプトを使用することが重要です。プロンプト技術(エンジニアリング)は、モデルに対する質問や指示の形式を指し、モデルのパフォーマンスを最適化するためのカギとなります。
現在、LLMを最大限に活用するためのプロンプト技術に関する方法論は、まだ完全には体系的に理解されていません。モデルの応答品質を向上させるための具体的な手順や原則が、ユーザー間、研究者間で十分には共有されていないことに起因しています。そのため、効果的なプロンプトの設計は、しばしば試行錯誤に依存する傾向にあります。
研究の再調査
この問題に対処するため、ある研究者たちは既存の文献を基に、プロンプト技術に関する原則と手法を再調査しました。この再調査は、原則からベーシックな手法、高度な手法に至るまで、LLMのパフォーマンスを最適化するためのアプローチを包括的に検討することを目的としています。
本記事の関連研究:GPT-4などLLMのコード生成能力にデバッグ機能を追加する『SELF-DEBUGGING(セルフデバッギング)』と実行プロンプト
原則
1. 詳細な説明の提供
LLMに対して、詳細な説明を提供することは、その能力を最大限に引き出す上で不可欠です。この観点は、モデルが与えられたタスクを理解し、適切なコンテキスト内で情報を処理するための基盤を築くために重要なポイントです。モデルがより精度高く、目的に沿った回答を生成するのを助けます。
2. 明確かつ正確な指示
明確かつ正確な指示をモデルに与えることで、期待される出力に近づけることができます。この点を徹底すると、モデルは与えられた問題に対して、より関連性の高い回答を生成することが可能になります。逆に指示が不明瞭だと、モデルは誤った方向に進む可能性があり、結果として品質の低い出力を生むことになります。
3. 繰り返して最適な回答を選択
LLMは、同じプロンプトに対しても異なる出力を生成することがあります。モデルが持つ複数の解釈や回答の可能性を反映しています。そのため、プロンプトを何度か繰り返し、モデルの応答を繰り返し確認すると、最適な出力を得られる場合もあります。
本記事の関連研究:LLMにまず前提から尋ることで出力精度を向上させる『ステップバック・プロンプティング』と実行プロンプト
ベーシックな手法
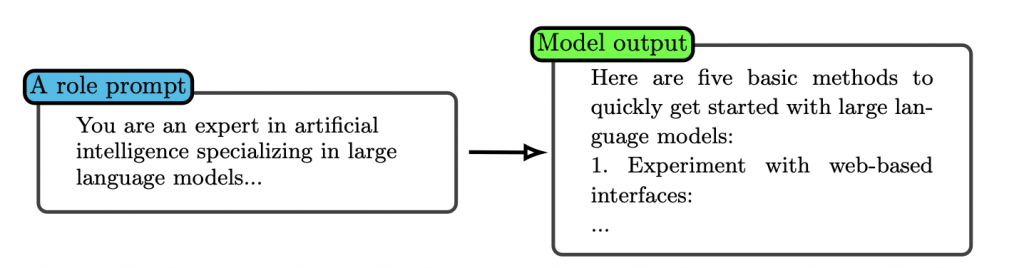
1. ロールプロンプト(Role-prompting)
ロールプロンプトは、モデルに特定の役割を与えることで、その役割に応じた回答の品質を向上させる手法です。例えば、モデルに教師、批評家、または学生の役割を与えることで、それぞれの視点からの回答を引き出すことができます。このアプローチは、モデルが特定のコンテキストや目的に沿ったより適切な回答を生成するのを助けます。
テンプレート:「〇〇として振る舞ってください」
参考:Aobo Kong et al., “Better Zero-Shot Reasoning with Role-Play Prompting”
関連記事:タスクに応じてロールプレイさせるとChatGPTなどLLMの推論能力は普遍的に向上する
2. トリプルクオートの活用
トリプルクオート(”’または”””)を使用することで、プロンプトを要素ごとに分離し、より複雑な指示を明確にすることができます。この方法は特に複雑なタスクを解決する際に、モデルが各部分を個別の情報として処理しやすくするために有効です。
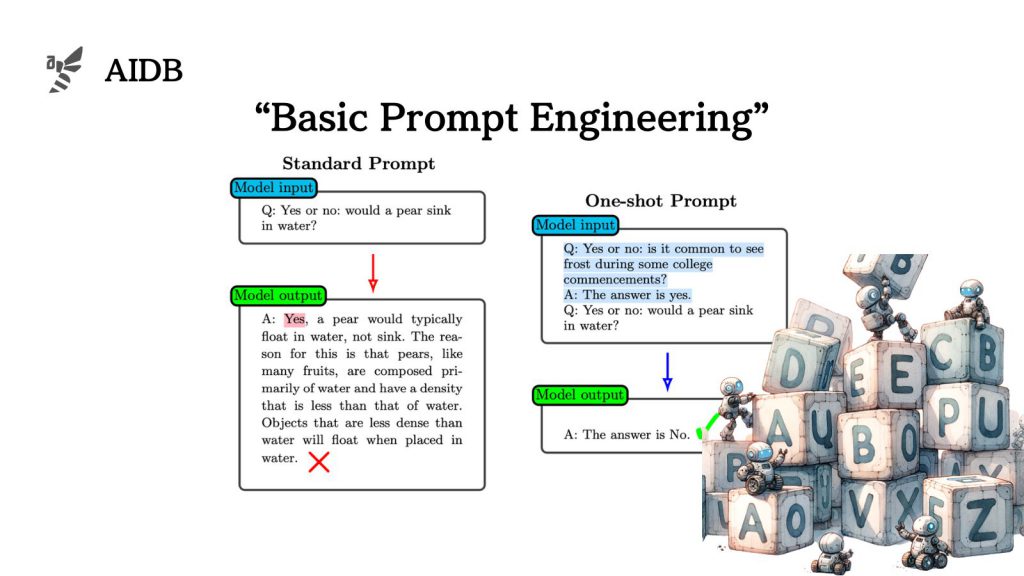
3. ワンショット/フューショットプロンプト
ワンショットやフューショットプロンプトは、指示の前に一つまたは複数の例を与えることで、モデルが学習済みのタスクを思い出し、新しいタスクに適用するのを助ける手法です。例の数はタスクやモデルの能力に応じて調整され、モデルが過去の学習を活用して新しい問題に取り組むのに役立ちます。

本記事の関連研究:GPT-4などのLLMに「自らの論理的な整合性をチェック」させるフレームワーク『LogiCoT』と実行プロンプト
高度な手法
以下では、複数の高度な手法を紹介します。下記をケースに応じて使い分けることでLLMの実用性がさらに向上します。

