
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
楽天、産総研、東京大学の研究者チームは、大規模言語モデル(LLM)の「色に対する理解度」を探る新しい研究を展開しました。
AIが急速に進化する中、言葉と実世界の関連付けである「グラウンディング」に注目が集まっています。研究者たちは、言語モデルが色と言葉の対応をどの程度捉えているかを分析しました。
結果は示唆に富んでいました。本研究は、AIが現実世界を「言葉でどう捉えるか」という問いに対して、新たな視点を提供しています。
参照論文情報
- タイトル:Perceptual Structure in the Absence of Grounding for LLMs: The Impact of Abstractedness and Subjectivity in Color Language
- 著者:Pablo Loyola, Edison Marrese-Taylor, Andres Hoyos-Idobro
- 所属:楽天、産総研、東京大学
- URL:https://doi.org/10.48550/arXiv.2311.13105
関連研究:画像分析機能を持つオープンソースLLM『LLaVA-1.5』登場。手持ちの画像を分析可能。GPT-4Vとの違い
研究背景
LLMと言語構造
大規模言語モデル(LLM)の興味深い側面の一つは、明示的な言語や知識なしに訓練されるにも関わらず、言語構造や関連知識が自然に現れる点です。
関連研究:LLMは世界モデルを持ち「物事がどのように位置づけられ、時間がどのように進行するか」を理解する可能性
一方で、LLMにおける現在の訓練目標とテキストデータは、広範囲のタスクをカバーするために十分かどうかという議論も進行中です。
「色の言語」
色の言語は、言語モデルのグラウンディングを研究するための媒体として使用されてきました。色の名前は、生理学的および社会文化的観点から考えられるものであり、コミュニケーションにおける意図が表れたものだからです。
なおグラウンディングとは、AIが言葉と実世界の具体的な対象や概念を関連付けるプロセスです。
これまでの研究では、色の空間的位置付けと自然言語との構造的一致を定量化されたものもあります。しかし、扱われてきた色の記述は主に単語レベルであり、より複雑で主観的な色の記述の扱いについては明らかにされていませんでした。
本研究の動機
研究者らは、色の空間的位置付けと言語の整合性が、より複雑で主観的なレベルでどの程度保たれるかを調査しました。LLMが色の言語を理解するための手法とアプローチを探求する必要性が浮き彫りになっています。
関連研究:OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化
研究デザイン
研究の具体的なデザインと実施方法について見ていきます。
データセットの選定
研究者たちは、色とそれに対する説明がペアになっている大規模データセット「ColorNames」を使用しました。このデータセットは、インターネットユーザーが共同で生成したもので、色彩に関する自由形式の記述を含んでいます。こうしたデータを使用することで、言語モデルが色の言語をどの程度理解しているかを、より実際の言語に近い形で分析することができました。

実験対象の言語モデル
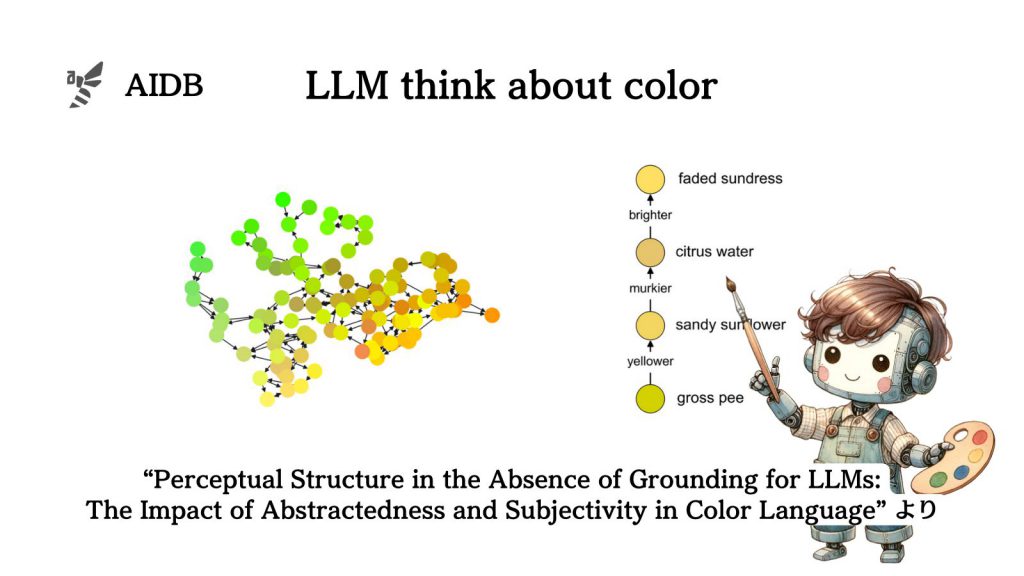
実験には、BERT、Roberta、T5といった複数の大規模言語モデルが使用されました。色に関する記述やそれらを比較するための形容詞(例えば「より暗い」「より鮮やかな」など)の関係を分析する性能が確かめられます。言語モデルが色に対する説明文(例:「深い青」と「明るい赤」)の比較をどの程度正確に理解しているかに焦点が当てられています。

調査手法
色の記述と比較形容詞(より深い、より明るいなど)の関係を分析するために、二つの実験が行われました。
第一の実験では、言語モデルの特徴空間と色空間の整合性が測定され、第二の実験では言語モデルが色の比較関係をどのように構造化しているかが検討されました。
調査結果
実験によって得られた調査結果についてです。
色と言葉の対応関係
調査の結果、

