ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
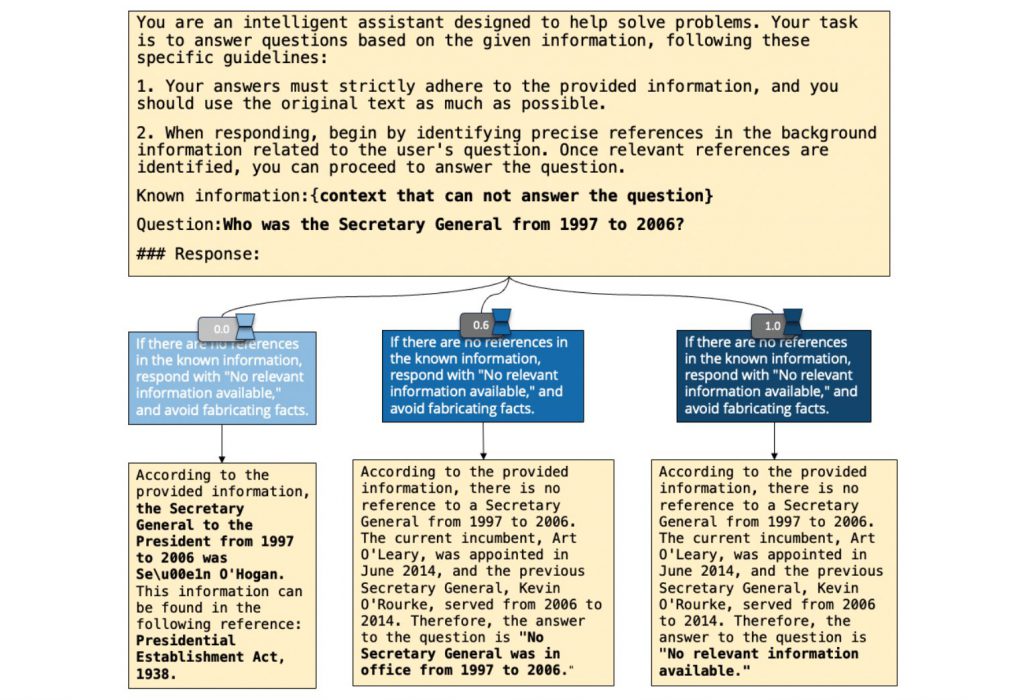
これまでのLLMの使用法は、モデルの動きを観察し、その反応に基づいてプロンプトを調整するという方法に重点が置かれてきました。しかし、プロンプトの効果を微細に制御するには不十分といえます。
この問題に対処するため、センスタイム社を含む研究者たちが開発したのが『ControlPE』(Continuously Controllable Prompt Engineering)です。ControlPEは、プロンプトによるLLMの動きを直接調整する手法です。モデルの挙動を細かく直接的に制御することを目指しています。
ControlPEはモデルを直接編集することなく実現します。そのため、開発者や研究者はLLMをカスタマイズする際に大きなリスクやリソースを必要としません。本記事では背景、ポイント、実装について、性能評価の結果について見ていきます。

参照論文情報
- タイトル:To be or not to be? an exploration of continuously controllable prompt engineering
- 著者:Yuhan Sun, Mukai Li, Yixin Cao, Kun Wang, Wenxiao Wang, Xingyu Zeng, Rui Zhao
- 所属:浙江大学、センスタイム、香港大学、シンガポール経営大学
- URL:https://doi.org/10.48550/arXiv.2311.09773
本記事の関連研究:「入力プロンプト」を最新情報で自動アップデート&最適化する手法『FRESHPROMPT』がLLMの出力精度を飛躍的に上げる
LLMのプロンプト制御とその課題
プロンプトの制御は、大規模言語モデル(LLM)において重要な役割を果たしています。LLMがどのように情報を処理し、応答を生成するかを導くための鍵となる要素です。LLMのプロンプト制御には数多くの手法が存在し、テキスト生成タスクを容易にし、タスク特有のトレーニングを不要にするなど幅広い効能の目的があります。
関連研究:ChatGPTの効果的なプロンプト手法における「基本のキ」を理論とテンプレート両方で紹介
しかし、適切なプロンプトを設計することは簡単な作業ではありません。微妙なプロンプトの変更が大きなパフォーマンスの変化をもたらすことがあり、無限に近い自然言語プロンプトの中から最適なものを見つけるのは困難です。
従来のプロンプト最適化技術は、プロンプトエンジニアリング手順を自動化することに焦点を当てていますが、離散的なプロンプトを連続的な空間でさらに制御または組み合わせる作業に焦点を当てた研究は少ないです。
関連研究:プロンプトを遺伝的アルゴリズムで自動最適化するプロンプトエンジニアリング手法『Promptbreeder(プロンプトブリーダー)』
この課題に対処するため、研究者らはプロンプト側の微調整ではなくLLM側の動作を変更する手法を研究しました。
『ControlPE』のポイント
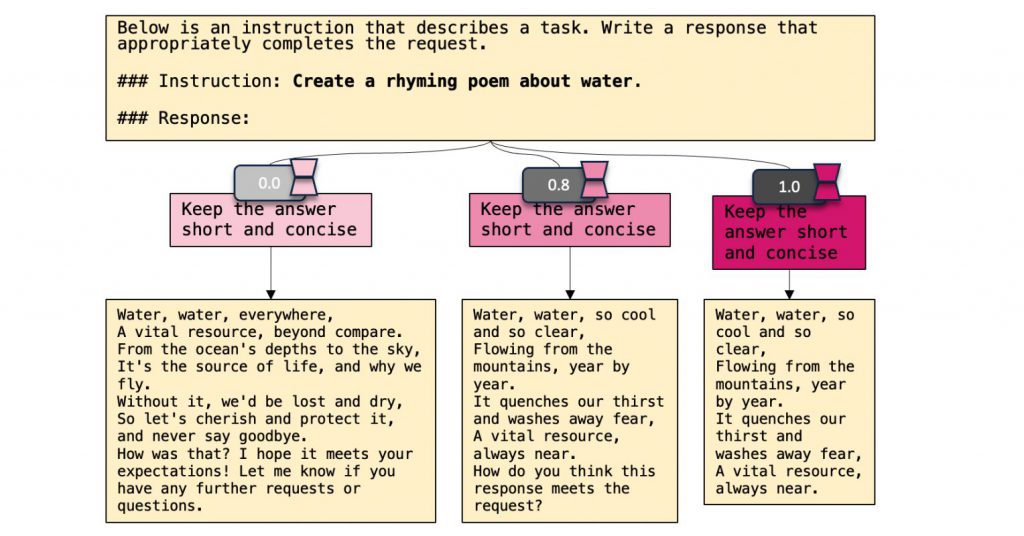
『ControlPE』(Continuously Controllable Prompt Engineering)は、LLMのプロンプト制御における新しい切り口の取り組みです。LoRA(Low-Rank Adaptation)の力を利用し、プロンプトの影響を重み付けのように微調整できるように設計されています。
ControlPEは、既存のプロンプトエンジニアリングを補完する形で、連続的なターゲットの制御を実現します。
短い応答、拒否応答、チェーン・オブ・ソート(CoT)プロンプトなど、様々なプロンプトの制御が可能になります。
要するに、LLMのカスタマイズがより柔軟かつ精密に行えるように、プロンプトがモデルに与える影響をよりダイナミックに変更するということです。
関連研究:ユーザープロンプトをLLMが言い換えて、LLM自身が理解しやすくする手法『RaR』
そもそもLoRAとは
LoRA(Low-Rank Adaptation)は、大規模なニューラルネットワークモデル、トランスフォーマーベースのモデルを中心とした微調整手法です。モデルの重みを直接更新するのではなく、より単純で小規模な行列を用いて、既存の重みに変更を加える手法です。
モデルの変換の仕組み
LoRAでは、トランスフォーマーの重み行列の出力を調整することにより、入力 ( x ) の次元から別の次元 ( h ) への変換を微調整します。
二つの小さな投影行列 ( A ) と ( B ) の積を ( x ) に加えることによって行われます。これらの行列は元の行列の次元 ( d ) と ( k ) よりもはるかに小さいランク ( r ) を持ちます。
トランスフォーマー内の適用
LoRAの変更は、トランスフォーマーの注意機構内のクエリと値の投影行列に主に影響します。
LoRAチューニングを開始するとき、行列 ( A ) はランダムなガウス値で埋められ、行列 ( B ) はゼロで始まります。元の事前訓練済みモデルの挙動が最初に保持されるというのが重要なポイントです。
料理に例えると
LoRAを料理に例えると、完成された豪華な料理(元の事前訓練済みモデル)に対して、追加のソースやスパイス(LoRAによる小さな行列)を用いて味付けを調整するような行為と言えるかもしれません。
料理全体の構造や品質を変えずに、特定の風味や特徴を微調整します。そのようにLoRAは、大規模言語モデルの挙動を細かく調整し、特定のタスクや要件に合わせて最適化するための効率的な手段として知られています。
ControlPEのフレームワーク
『ControlPE』の実装は、三段階の方法論が提案されています。以下に、ControlPEを実装するための主なステップを論文から紹介します。まず下図は、ControlPEのプロセスを三段階で図解するものです。

