
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
GPT-4などの大規模言語モデル(LLM)はコード生成においても驚異的な成果を上げています。しかし、モデルが生成するコードは必ずしも完璧ではありません。そこで、DeepMindとUCバークレーの研究者らは新たなフレームワーク『SELF-DEBUGGING(セルフデバッギング)』を開発しました。
追加訓練なしでも、複数のベンチマークにおいて高いパフォーマンスを達成できる手法です。実行プロンプト(の例)は比較的シンプルで、多くのプログラミングタスクで容易に適用できます。
参照論文情報
・タイトル:Teaching Large Language Models to Self-Debug
・著者:Xinyun Chen, Maxwell Lin, Nathanael Schärli, Denny Zhou
・所属:Google DeepMind, UC Berkeley
・URL:https://doi.org/10.48550/arXiv.2304.05128
本記事の関連研究:LLMにまず前提から尋ることで出力精度を向上させる『ステップバック・プロンプティング』と実行プロンプト
背景と課題
1. LLMは初めから正確なコードを生成しない
LLMは、コード生成においても優れた性能を示しています。自然言語からのコード生成やコード変換など、多くのプログラミングタスクでその能力が評価されています。しかし、複雑なプログラミングタスクにおいて、一度の試行で正確なコードを生成することは容易ではありません。
2. 追加訓練のコスト
既存の研究では、特定のタスクに対する性能を向上させるために、モデルの追加訓練が多く行われています。しかし、追加訓練は時間とコストがかかり、効率的ではありません。
3. コードの理解と実行
LLMは自然言語の指示に従う能力は高いものの、コードの実行に関する理解は限定的だと言われています。例えば、問題の説明にユニットテスト(※)が提供されていても、生成されたプログラムが必ずしも正確であるわけではありません。
※ユニットテストとは、プログラムの一部(通常は関数やメソッドなどの「ユニット」)が期待通りに動作するかを確認するためのテスト手法です。コードの各部分が正確に動作するかを独立して検証することで、全体としてのプログラムの品質を高めます。
4. 外部フィードバックの依存
多くの場合、LLMは外部のフィードバック(例えばユニットテストや人間による指示)がないと、生成したコードの正確性を確認することが難しいとされています。
このような背景と課題を解決するために研究者らが考案したのが「SELF-DEBUGGING」フレームワークです。
本記事の関連研究:GPT-4などのLLMに「自らの論理的な整合性をチェック」させるフレームワーク『LogiCoT』と実行プロンプト
フレームワークの方法論
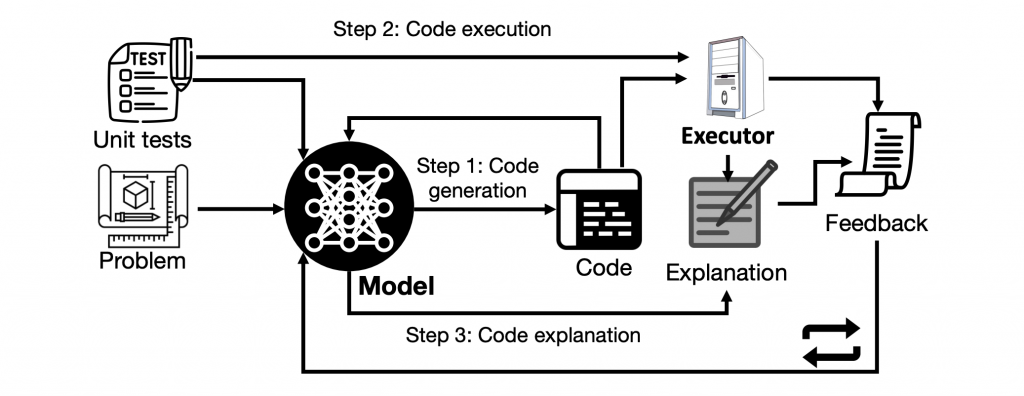
SELF-DEBUGGINGフレームワークの概要
研究者らは、LLMが自ら生成したプログラムをデバッグできるようにする新しいフレームワーク、SELF-DEBUGGINGを考案しました。特別な追加訓練なしで、既存のLLMに適用可能です。このフレームワークの一回のデバッグサイクルは、以下の3つのステップで構成されています。
3つの主要なステップ
1. 生成(Generation)
最初のステップでは、問題の説明を受けて、モデルは候補となるプログラムを予測します。このステップは、基本的にはコード生成のフェーズとなります。
2. 説明(Explanation)
次に、モデルは生成したプログラムに対して説明を行います。生成されたプログラムが何をしているのか、どのようなロジックに基づいているのかを説明するステップです。自然言語で行われる場合もありますが、サンプル入力に対する実行トレースを生成する場合もあります。
3. フィードバック(Feedback)
最後のステップでは、

