ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
大規模言語モデル(LLM)はしばしば、真の推論能力を発揮しきれていない出力を行っています。この現象はカーネギーメロン大学とGoogleの研究者らによって指摘され、さらに解決するための新しいアプローチが提案されています。

本研究は、一時停止トークンという新しい手法を導入することでLLMに追加で計算を行わせ、推論を深めさせることに成功しています。本記事ではその詳細をご紹介します。
また、プロンプトを工夫することで、一時停止トークンのような効果を模倣する可能性も考察しました。一般のユーザーも高度なプログラミングスキルや専門的な知識なしに、LLMの性能を向上させることができるかもしれません。
さらに記事の最後では、人間の挙動との類似性にも触れました。
参照論文情報
- タイトル:Think before you speak: Training Language Models With Pause Tokens
- 著者:Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, Vaishnavh Nagarajan
- 所属:Carnegie Mellon University, Google Research
- URL:https://doi.org/10.48550/arXiv.2310.02226
関連記事(続きは記事末尾にあります)
■GPT-4などのLLMに「自らの論理的な整合性をチェック」させるフレームワーク『LogiCoT』と実行プロンプト
■LLMの出力から誤り(ハルシネーション)を減らす新手法『CoVe(Chain-of-Verification)』と実行プロンプト
従来の課題
推論と出力の悩ましい関係
従来(現状)の言語モデル、特にトランスフォーマーベースの因果言語モデルは、トークンを即座に一つずつ生成します。このプロセスは非常に効率的ですが、一つの重要な制約に直面しています。それは、次のトークン(K + 1番目のトークン)を生成するための操作数が、これまでに見たトークン数(K)によって制限されるという点です。
品質の問題
上記の制約により、言語モデルはしばしば「十分な推論を行なっていないまま推論ステップを進めている」問題に直面します。結果として、十分な品質の回答を出せない場面があります。簡単に言えば、これは「深い思考が済んでいないのに口から言葉が出てしまっている」状態に似ています。
この制約は、理由付け、質問応答、事実の回想など、多くの下流タスクに影響を与える恐れがあります。
既存の解決策とその限界
LLMの推論を多段階に分けて出力の品質を向上させるの方法として、Chain of Thought(CoT)プロンプティングがあります。モデルに中間の推論ステップを生成させる方法ですが、これはコスト(工数と計算負荷)がかかる上に、必ずしも明確な利点がないケースもあります。
フレームワークの概要
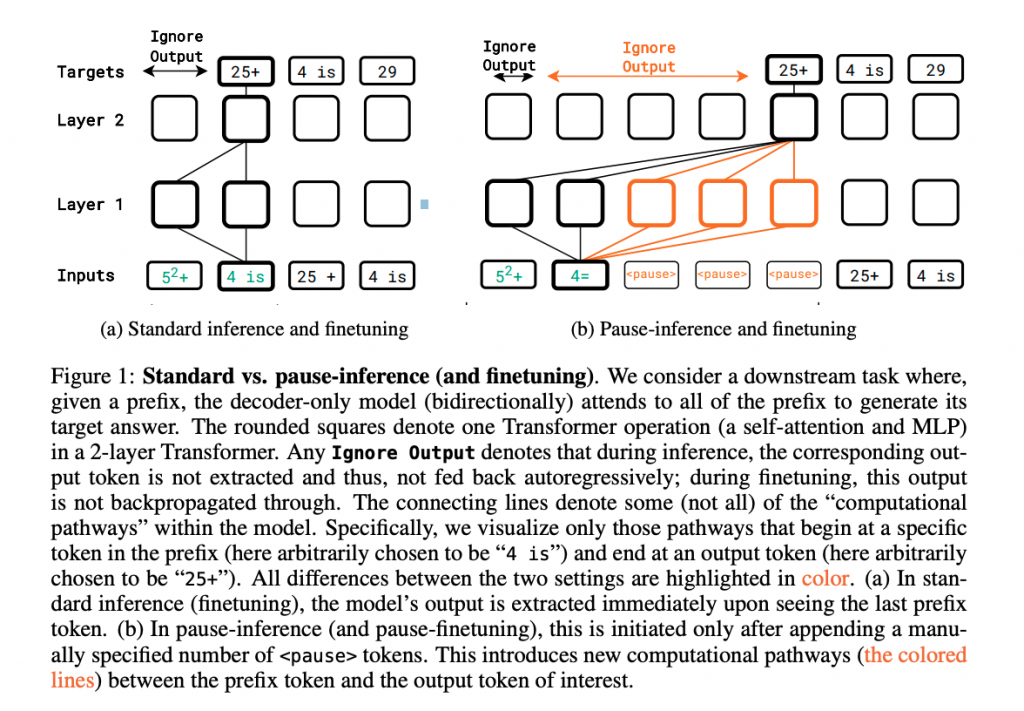
一時停止トークンの導入
今回、研究者らは、プレトレーニングとファインチューニングの両方のフェーズで「一時停止トークン」を導入することで、モデルの推論能力を十分に表現させることを考案しています。
一時停止トークンは、モデルがK個のトークンを処理した後、(K + 1)番目のトークンを生成する際に、K + MのTransformer操作を各層で行うためのものです(M > 0)。
要するに、生成する前に計算を進めて推論を深めさせるテクニックです。
トークン数と位置の調整
本フレームワークでは、タスクに応じて一時停止トークンの数と位置を変更することが推奨されています。
適切な数の一時停止トークンを適切な位置で用いることで、特定の下流タスク、例えば質問応答タスクにおいて、より精度の高い回答を生成する可能性があります。
上記は実験結果によって明らかになった知見です。
一時停止と他の手法との比較
この一時停止トークンの導入は、他のフィードバックループベースの手法とも関連がありますが、一時停止トークンはモデルの核となるメカニズムを保持します。すなわち、モデルは依然としてK個の前の入力トークンに基づいて(K + 1)番目のトークンを計算します。
少し複雑ですが、追加のTransformer操作(K + M)を行うことと、K個の入力トークンに基づいて(K + 1)番目のトークンを生成することは同時に成り立ちます。
考慮すべき点
一時停止トークンの導入は、プレトレーニングとファインチューニングの両方で行うことが、下流のデータセットにおいて明確な利点をもたらすとされています。ファインチューニングの段階だけで一時停止トークンを導入すると、その効果は限定的である可能性が高いです。
一時停止トークンについての詳細
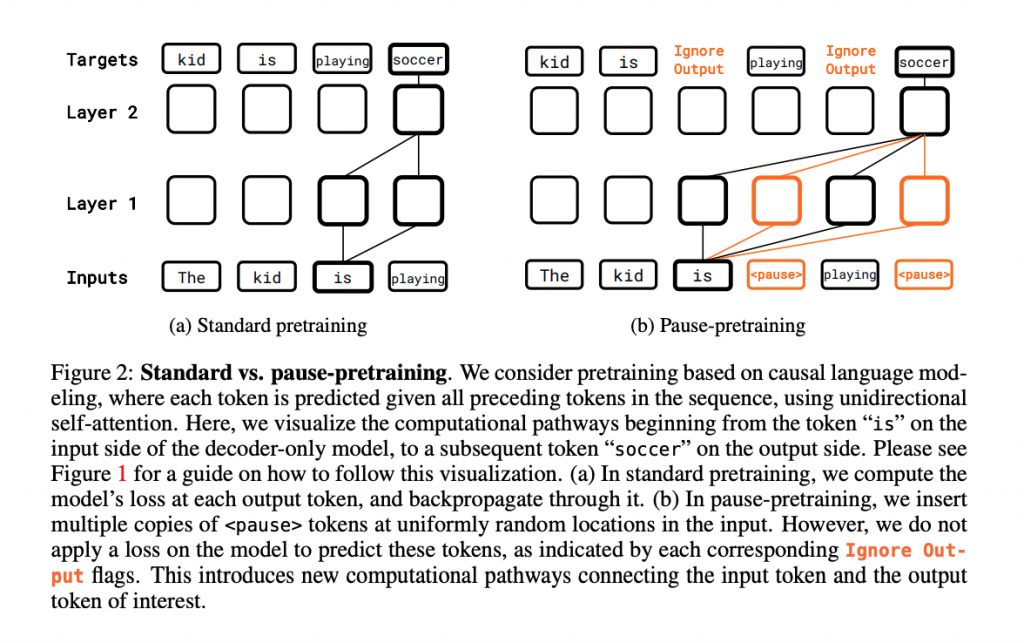
追加の計算を行わせる新種類の「手続き」トークン
一時停止トークンは、LLMがより深い推論を行うための時間を確保する新しい種類のトークンです。このトークンは、標準の語彙外に存在し、特定の目的で設計されています。
ここで、「時間を確保する」という説明だけでは、理解のために十分とは言えません。
一時停止トークンは、K+1番目のトークンを生成する際に、通常のK個のトークンからの計算に加えて、K+MのTransformer操作(計算)を各層で行うように指示するものです。そのため、単に生成時間を遅くするのではなく、モデルに対して「より多くの計算を行い、より深い推論を可能にする」ための指示です。、一時停止トークンは計算を追加で行わせる「手続き」と言えます。