
Googleは、非構造化文書(例えばレシートなど)から高精度にテキストを抽出するOCR(Optical Character Recognition)技術『LMDX(Language Model-based Document Information Extraction and Localization)』を発表しました。この技術は、特にGoogleの大規模な言語モデル「Bard」と、Google DriveやGmailなどのサービスとの連携をさらに強化する可能性もあります。
参照論文情報
- タイトル:LMDX: Language Model-based Document Information Extraction and Localization
- 著者:Vincent Perot, Kai Kang, Florian Luisier, Guolong Su, Xiaoyu Sun, Ramya Sree Boppana, Zilong Wang, Jiaqi Mu, Hao Zhang, Nan Hua
- 所属:Google、カリフォルニア大学
- URL:https://doi.org/10.48550/arXiv.2309.10952
関連研究
- OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化
- 数式や文章がぐにゃぐにゃに曲がった論文PDFでもくっきり認識する画期的なOCR『Nougat』
従来の課題と背景
文脈の考慮が不十分
従来のOCR技術は、非構造化や半構造化の文書からテキストを抽出する際に、文脈の考慮が不十分でした。テキスト認識と解析が別々のステージで行われていたため、文脈とレイアウトの統合が困難でした。
レイアウトの柔軟性に欠ける
さらに、従来の方法では多様なレイアウトに対応する能力が限られていました。特に、請求書や税務書類などの半構造化形式の文書においては、テンプレートが多様であり、その柔軟性に対応するのが難しかったです。
データ効率の低さ
また、多くの文書パーサーは非常に少量のデータで構築されていました。これは、注釈リソースが限られている一方で、文書の種類が無限であるため、データ効率が非常に低いという問題がありました。
BardとGoogleサービス群の連携
GoogleのBardは、最新のアップデートでさらに多くの機能を追加しました。BardはGoogleの各種アプリとサービスと連携することが可能になり、GmailやGoogle Driveなどから情報を取得することができます。
BardがGoogle driveやGmailなどのサービス群と強力に連携するためには、画像ベースの非構造化・半構造化ドキュメントを理解する能力が求められています。なぜなら、個人のGoogle driveやGmailには非構造化・半構造化ドキュメントが大量に保存されている場合があるからです。
GoogleのBardは非構造化・半構造化データからの情報抽出においては、上述の課題によりその能力は制限されていました。
『LMDX』のスキーム
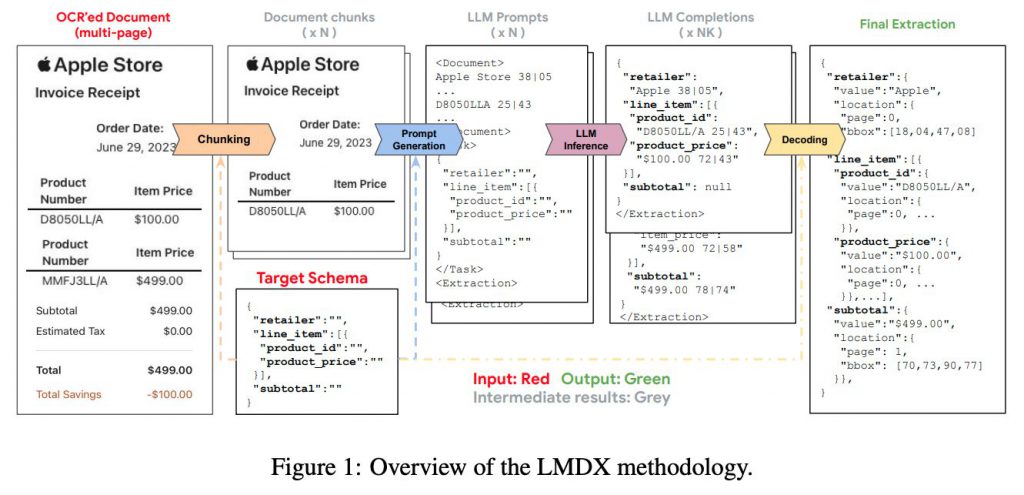
Googleの研究者らが開発した『LMDX』は、非構造化文書からの情報抽出を高度に行うOCRフレームワークです。このフレームワークは、以下の5つの主要なステップから構成されています。
- OCRステップ
- Chunkingステップ
- Prompt Generationステップ
- LLM Inferenceステップ
- Decodingステップ
OCRステップ
このステップでは、画像やPDFから文字情報を光学的に読み取ります。このプロセスは、文書内のテキストをデジタル形式に変換する基礎となるステップです。
Chunkingステップ
OCRで検出された文字情報は、このステップで単語や文章に「チャンキング」(区切り)されます。これにより、次のステップでLLMによる解析が容易になります。
Prompt Generationステップ
チャンキングされたテキストをもとに、LLMに問い合わせるための「プロンプト」が生成されます。
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP