
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
GPT-4などのモデルは、多くの領域で非常に高い汎用性を持っています。しかし、「多段階の推論」を必要とする場面での能力にはまだ改善の余地があります。
この課題に対処するために、Xufeng Zhaoらによって新たなフレームワーク『LogiCoT(Logical Chain-of-Thought)』が発表されました。このフレームワークは、既存のChain-of-Thought(CoT)フレームワークをさらに発展させ、LLMに「自らの論理的な整合性をチェック」させることで、推論能力を向上させることを目的としています。
本記事では具体的なプロンプト例も含めてこのフレームワークの詳細を紹介します。
参照論文情報
- タイトル:Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic
- 著者:Xufeng Zhao, Mengdi Li, Wenhao Lu, Cornelius Weber, Jae Hee Lee, Kun Chu, Stefan Wermter
- 所属:University of Hamburg
- URL:https://doi.org/10.48550/arXiv.2309.13339
関連研究
- LLMの出力から誤り(ハルシネーション)を減らす新手法『CoVe(Chain-of-Verification)』と実行プロンプト
- 推論能力をさらに強める戦略『AoT』で、LLMが「直感」に似た能力を示すようになった
- メタ認知をさせてLLMの能力を上げる手法「メタ認知プロンプティング」
従来の課題と背景
LLMの推論能力の限界
大規模言語モデル(LLM)は、短い質問や単純なタスクに対してはゼロショットで高い性能を発揮しますが、ステップバイステップの推論が必要な長い質問や複雑なタスクに対しては、通常はその性能に限界があります。複数の前提条件や仮定に基づいて論理的に推論する必要がある場合、LLMはしばしば不正確な結論に至ることがあります。
CoTフレームワークの限界と利点
Chain-of-Thought(CoT)フレームワークは、このような複雑な問題に対する一つの解決策として提案されました。CoTは、質問を小さな部分に分解し、それぞれに対する回答を生成することで、全体の質問に対するより正確な回答を導き出すことができます。CoTは例えば、以下のようなプロンプトで実行できます。
「深呼吸して、ステップバイステップで取り組んでください」
しかし、CoT自体にも問題点があり、特に複雑な推論タスクにおいてはその限界が明らかになっています。
※なお、「深呼吸して」という呼びかけが有効なのは最近の研究によって明らかになりました。以下の記事で詳細を説明しています。
LLMが巡回セールスマン問題などの最適化問題を解く〜自分自身で優れたプロンプトを作成&活用〜
新フレームワークの必要性
以上のような背景から、研究者らは新たなフレームワークの必要性を感じました。CoTの基本的なアプローチは有用であるものの、それだけでは不十分であり、さらなる改善が必要でした。そこで、CoTの利点を最大限に活かしつつ、その弱点を補強する新しいフレームワーク『LogiCoT』が考案されました。
実装方法
以下では、『LogiCoT』の実装に関する情報をまとめます。
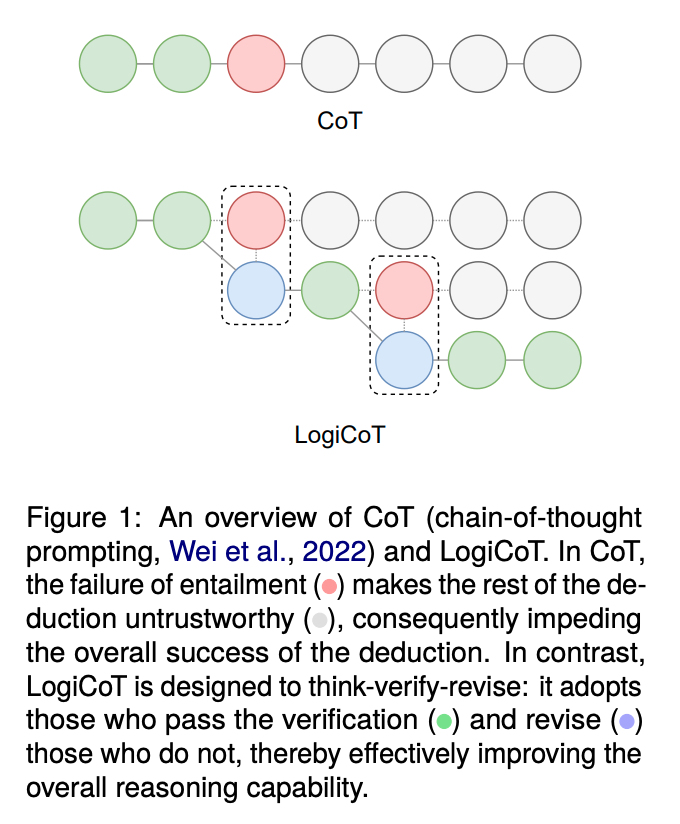
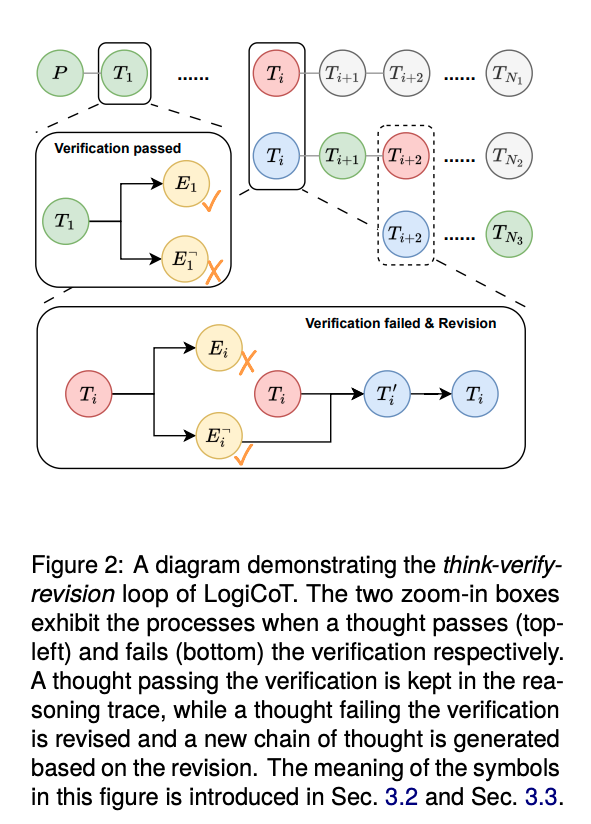
既存のLLMに対する外部制御
一つ目の方法として、既存の大規模言語モデル(LLM)に対して外部からプログラムで制御する手法があります。このアプローチでは、LLMが生成するテキストに対して、外部のプログラムがLogiCoTフレームワークに基づいて介入します。
LLMが生成した回答に対して論理的整合性をチェックし、必要に応じて修正や補完を行います。この方法はカスタマイズ性があり、かつ比較的安価に実現できる点でメリットがあります。一方で、手法を最も手軽に実装できる手段ではないかもしれません、
LLM自体の訓練
二つ目の方法は、LLM自体をLogiCoTフレームワークに基づいて訓練するというものです。この方法では、LLMが自らの内部でLogiCoTフレームワークを用いて推論を行うように訓練されます。
つまり、デフォルトの状態として、LLMはより高度な論理的推論能力を持つことが期待されます。この方法は、一度訓練してしまえばLLM自体がずっと(平たく言うと)賢い状態になることがメリットです。一方で、訓練には工数がかかり、さらにLogiCoT状態を解除したいときにうまくいかない可能性があります。
ユーザーによるプロンプト指示
論文では上記二つの方法が推奨されていますが、三つ目の方法として、ユーザーがプロンプトでLLMに対して明示的に指示を出すという手法も考えられます。
この方法では、ユーザーが具体的なプロンプトを用いてLLMにLogiCoTフレームワークに従った推論を行わせることができます。最も手軽な方法であるというメリットが明確に存在します。一方で、このフレームワークの潜在能力を最大限に発揮できる方法ではないかもしれません。あくまでもインスタントな方法であるという点に注意です。
プロンプト例
ユーザーによる指示の重要性
プロンプトでLogiCoTフレームワークを活用するためには、ユーザーが明確な指示を出すことが重要です。より高度な論理的推論を可能にするためには、フレームワークの主旨に合った指示を送る必要があります。
基本的なプロンプトの形式
以下は、ユーザーがLLMに対して出すことでLogiCoTを発動できる基本的なプロンプトの一例です。

