
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
話し手の声を別の人の声にリアルタイムで変換する技術は、その「処理の重さ」が長らくの大きな課題でしたが、今回一般消費者向けのCPUでも動作するとされる軽量なモデルが開発されました。このモデルはLLVC(Low-latency Low-resource Voice Conversion)と名付けられ、16kHzのビットレートで20ms未満の遅延を実現し、消費者向けCPU上で実時間の約2.8倍の速度で動作すると説明されています。
なお、研究者たちのサイトにはデモが公開されています。特定の人物の声が、別の特徴を持つ声に変わる様子を実際に把握することができます。本研究は、「Koe AI」という企業による新しい発表であり、でもの他にもオープンソースのサンプル、コード、事前学習済みのモデルの重みが提供されています。
参照論文情報
・タイトル:Low-latency Real-time Voice Conversion on CPU
・著者:Konstantine Sadov, Matthew Hutter, Asara Near
・所属:koe AI
・URL:https://doi.org/10.48550/arXiv.2311.00873
・GitHub:https://github.com/KoeAI/LLVC
・LLVC サンプル: https://koeai.github.io/llvc-demo/
・Windows 実行可能ファイル: https://koe.ai/recast/download/
背景とこれまでの課題
課題の概要
音声変換技術は、スピーカーの声を別の声に変換することを目的としており、その応用は広範です。しかし、これまでの研究では、リアルタイムでの音声変換を消費者向けハードウェアで実現することには多くの課題がありました。
高品質な音声合成ネットワークはリアルタイム処理には適しておらず、高速な操作だけでなく、低遅延での処理、そしてオーディオコンテキストへのアクセスが困難という問題がありました。
さらに、広範囲の消費者に利用されるリアルタイム音声変換ネットワークは、低リソースの計算環境(つまりCPUなど)で動作する必要があります。
既存のアプローチ
文献によると、早期の音声変換アプローチは、ガウス混合モデルが採用されていました。しかし最近では人工ニューラルネットワークが使用され、現代のアーキテクチャには変分オートエンコーダ(VAE)や生成敵対ネットワーク(GAN)が含まれることが一般的になってきました。
最新のアプローチは、話者が同一の発話を行う必要がない非並列データセットで動作するように設計されているとのことです。VAEのボトルネックや適応型インスタンス正規化、k最近傍法、または自動音声認識(ASR)や音声後部グラム(PPG)などの、事前訓練されたモデルを含むことで達成されています。
また、リアルタイム音声変換に対応可能なアーキテクチャはいくつか存在しますが、それらは例えば低遅延のストリーミングオーディオで動作するようには訓練されていないという課題が指摘されています。
LPCNetやEnCodecなどのニューラルオーディオコーデックは、低リソースのストリーミング設定で動作するように設計されていますが、これらのオーディオコーデックエンコーダーは、再構築されたオーディオの忠実度を保証するために、音声コンテンツとともに入力話者の特性を保存することを目的としています。したがって、それらは音声変換のタスクには適していません。
本記事の関連研究:大規模言語モデルが音声をダイレクトに理解する能力を与える Metaとケンブリッジ大
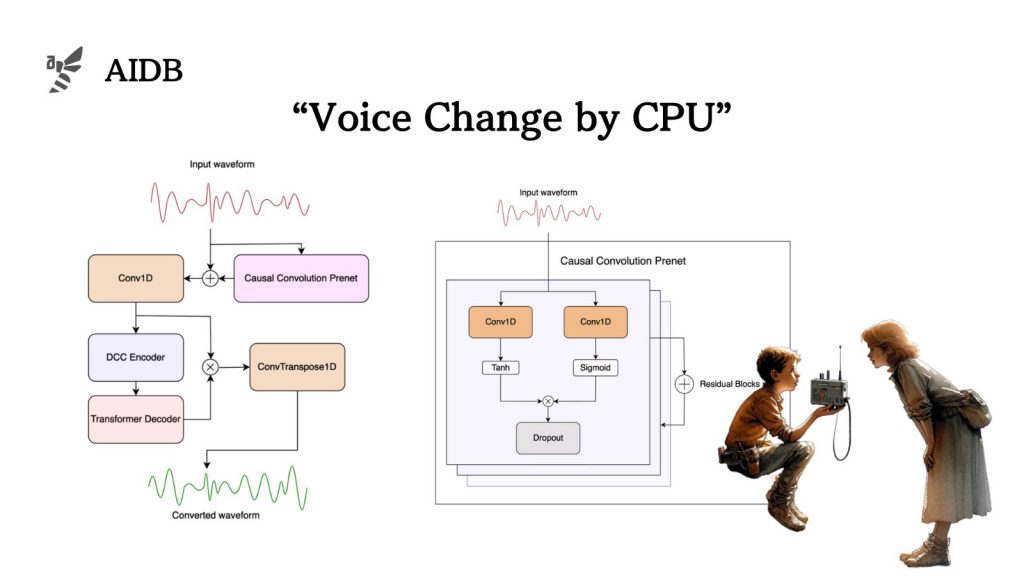
LLVCモデルのポイント
ジェネレータとディスクリミネータの組み合わせ
LLVCモデルは、ジェネレータとディスクリミネータの2つの主要なコンポーネントから構成されています。
ジェネレータは、実際の音声データを変換する役割を担い、ディスクリミネータは生成された音声が本物かどうかを評価します。二つの相互作用により、モデルはより自然で信頼性の高い音声変換を学習します。ただし、実際の音声変換の適用時には、ジェネレータのみが使用され、これにより処理速度が向上します。
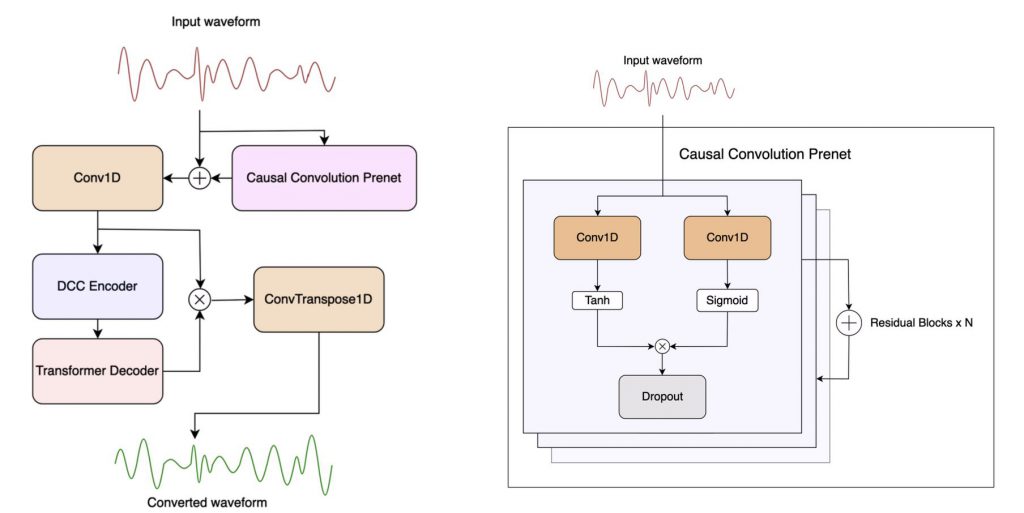
リアルタイム推論の実現
LLVCは、リアルタイム推論を可能にするために特別に設計されています。音声変換を行う際の遅延を最小限に抑え、ユーザーはほとんど遅延を感じることなく変換された音声を聞くことができるとのことです。モデルは、20ミリ秒以下の遅延で音声変換を行うことができるため、実際の会話やライブストリーミングなどのリアルタイムアプリケーションに適していると主張されています。
前置されたオーディオコンテキストの活用
LLVCは、過去のオーディオコンテキストを利用して、より自然な音声変換を実現するとも述べられています。単一の音声サンプルだけではなく、その前後の音声情報も考慮に入れることで、より流暢で自然な音声の連続性を保つとのことです。このアプローチにより、変換された音声はより自然に聞こえ、聞き手にとって快適な聞き取りが可能になるようです。
計算効率と変換品質のバランス
LLVCは計算効率と変換品質の間のバランスを見つけることに重点を置いています。高品質な音声変換を実現しつつも、一般消費者の手にある限られた計算リソースで動作する必要があるためです。このバランスを達成することで、モデルは幅広いデバイスでの使用が可能となり、より多くのユーザーがリアルタイム音声変換の恩恵を受けることができます。
本記事の関連研究:MRIデータから音声を合成する手法 UCバークレーなどが開発
性能のテスト結果
LLVCモデルの性能評価は、厳密に設計されたテストを通じて行われました。以下は、主なテスト内容と結果です。

