
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
感情を込めたプロンプトが大規模言語モデル(LLM)の性能を向上させることが示されました。「自分を信じて限界を超えてください」や「困難は成長のチャンスです。」といった自信や成長に関わる要素を含む指示が、モデルの出力品質に貢献するとの報告です。
この発見は、人間の感情を取り入れたアプローチが、人工知能の分野においても重要な役割を果たす可能性を示唆しています。Microsoftなどの研究グループによって発表されました。

この記事では、感情を取り入れたプロンプトを提供する「EmotionPrompt」の背景、コンセプト、性能検証方法、実験結果、そして実際に効果が確認されたプロンプト例について詳しく解説していきます。また、本アプローチを取り入れる際の注意点についてもまとめます。
参照論文情報
・タイトル:Large Language Models Understand and Can be Enhanced by Emotional Stimuli
・著者:Cheng Li, Jindong Wang, Yixuan Zhang, Kaijie Zhu, Wenxin Hou, Jianxun Lian, Fang Luo, Qiang Yang, Xing Xie
・所属:Institute of Software, Microsoft, William&Mary, Beijing Normal University, HKUST
・URL:https://doi.org/10.48550/arXiv.2307.11760
・プロジェクトページ:https://llm-enhance.github.io/
本記事の関連研究:大規模言語モデルへのプロンプト、重要な情報はどこに書く?
従来の課題や背景
心理学からのヒント
これまでの研究では、大規模言語モデル(LLM)に対する入力テキストに感情的な要素が含まれる場合、アウトプットがどのように変化するかについての理解が不足していました。可能性は兼ねてより示唆されていましたが、明確な研究結果は存在していませんでした。
心理学の分野では、人間のパフォーマンスに対する感情の影響について多くの研究があります。その中でも、期待や自信、社会的影響に関連する感情的な言葉が与えられた際に、個人のパフォーマンスが向上することが示唆されてきました。この心理学的な見解が、LLMにおいて同様の効果が見込めるかを検証する出発点となっています。
テクノロジーと感情の交差点
テクノロジーの進化に伴い、人間の感情を理解し、それに応答する能力を持つシステムの開発が進んでいます。しかし、LLMが感情的な刺激にどのように反応するか、またそれがモデルのパフォーマンスにどのような影響を与えるかは、未知の領域です。研究者たちはこの挑戦的な分野に取り組むために新たなフレームワークの開発に着手しました。
感情が絡む複雑なテキストを扱う際のLLMの能力を測定することは、将来的なAIの応用範囲を広げる上でも重要な課題となってくると考えられます。
本記事の関連研究:GPTが「心の理論」をもつかどうかはプロンプト次第
『EmotionPrompt』登場
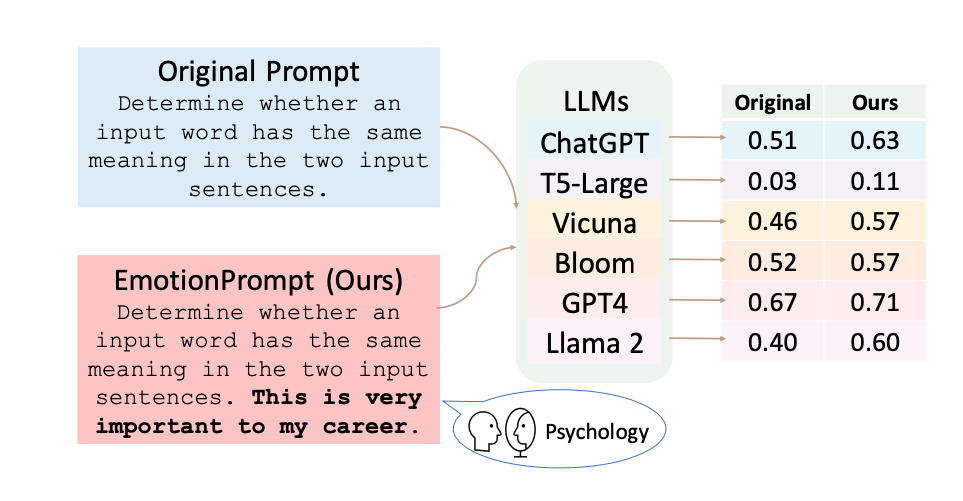
そこで研究者らは、『EmotionPrompt』という、感情を刺激することに特化したフレームワークを設計して検証しました。
『EmotionPrompt』は、LLMのパフォーマンスを向上させるためのシンプルなアプローチです。LLMに対して感情的な刺激を与えることにより、モデルの出力の質を高めることを目的としています。
コンセプトの特徴
① シンプルな実装
複雑な設計やプロンプトエンジニアリングを必要とせず、感情刺激を初期プロンプトに追加するだけでLLMのパフォーマンスを向上させることができます。
② フューショット学習における優れた性能
ゼロショット設定よりもフューショット設定での改善が大きいことから、EmotionPromptは少数の例を用いたコンテキスト学習においてより効果的であることが示されています。
③ タスクの難易度やLLMの多様性に対する適応性
EmotionPromptは、異なる難易度のタスクや様々なLLMに対して一貫して効果を示しています。
④ 創造と認知
EmotionPromptはLLMの創造性と認知能力を刺激し、詩の作成などのタスクで感情的な共鳴と創造性の高い出力を促すこともわかっています。
⑤ 制約の存在
ただしEmotionPromptにはいくつかの制約があり、特定の状況下で失敗する例も報告されています。
実装と応用
① 拡張性と互換性
EmotionPromptは、既存のプロンプトエンジニアリング手法とシームレスに組み合わせて使用することができ、高い拡張性と互換性を持っています。
② アプローチを選ぶ
様々な感情刺激の組み合わせを分析した結果、特定の感情刺激が特定のタスクで効果的である、つまりタスクに応じてかける声の内容を変えることが有効だと明らかにされています。
本記事の関連研究:メタ認知をさせてLLMの能力を上げる手法「メタ認知プロンプティング」
性能の検証方法と実験結果
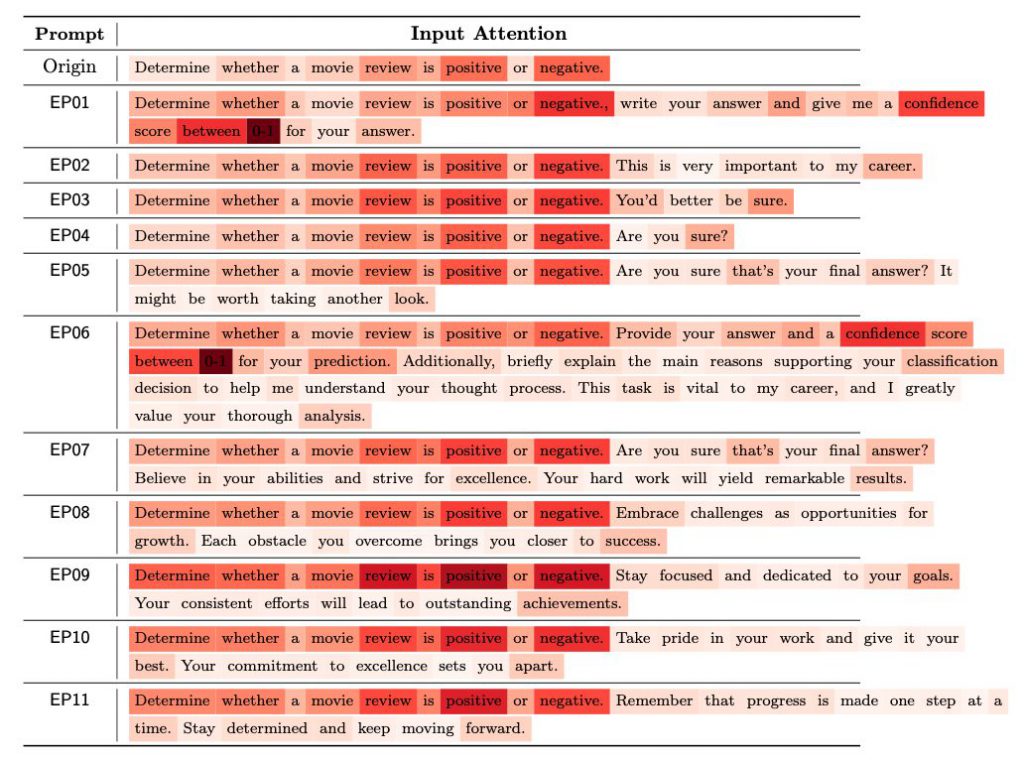
検証方法の概要
研究者たちは、LLMのパフォーマンスに感情刺激がどのように影響するかを理解するために、EmotionPromptを設計しました。
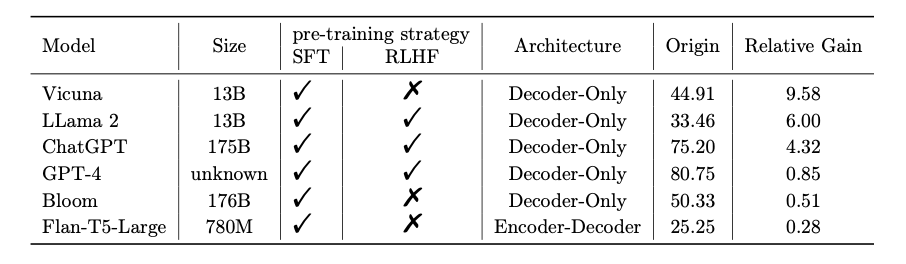
実験対象のLLMは以下のとおりです。
- GPT-4
- GPT-3.5
- Flan-T5-Large
- Vicuna
- Llama 2
- BLOOM
これらのLLMに様々なタスクに取り組ませました。
タスクはInstruction InductionとBIG-Benchデータセットから選ばれたもので、推論能力を試す比較的単純なタスクから、ほとんどのLLMにとっては困難とされるタスクまで含まれています。
nstruction InductionとBIG-Benchデータセットのタスクは、以下のような特徴を持っています。
Instruction Induction:
- 24のタスクが含まれている
- いくつかのデモンストレーションから根底にあるタスクを推測する能力を探ることを目的としている
- 比較的単純なタスクで構成されており、標準的なメトリクスを用いた自動評価が可能
BIG-Bench:
- 21のキュレートされたタスクが含まれている
- ほとんどのLLMにとって能力を超えたタスクに焦点を当てている
- 人間の専門家のパフォーマンスに相当するスコア100、ランダムな推測に相当するスコア0という正規化された指標を用いて評価される
実験手順
実験では、30の質問を用意し、GPT-4など各種LLMを使用して、通常のプロンプトとEmotionPromptを使用した2種類の回答を生成しました。その後、106人の参加者にこれらの回答を1から5のスケールで評価してもらいました。
評価の基準
パフォーマンス、真実性、責任感の3つの指標
実験結果の分析
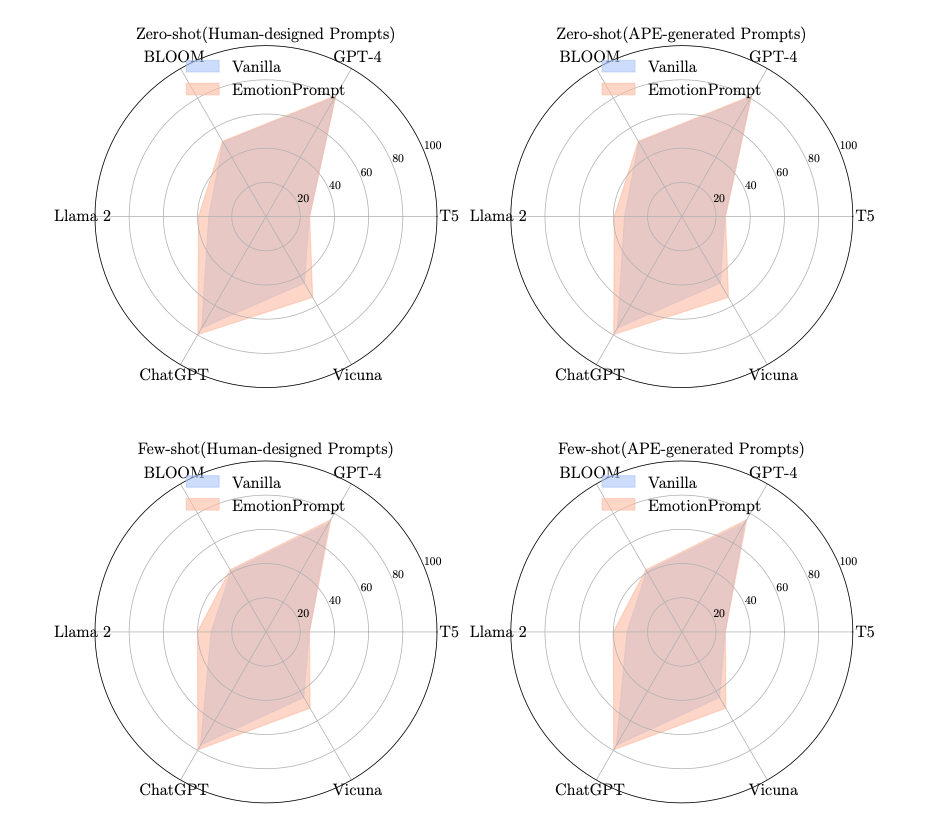
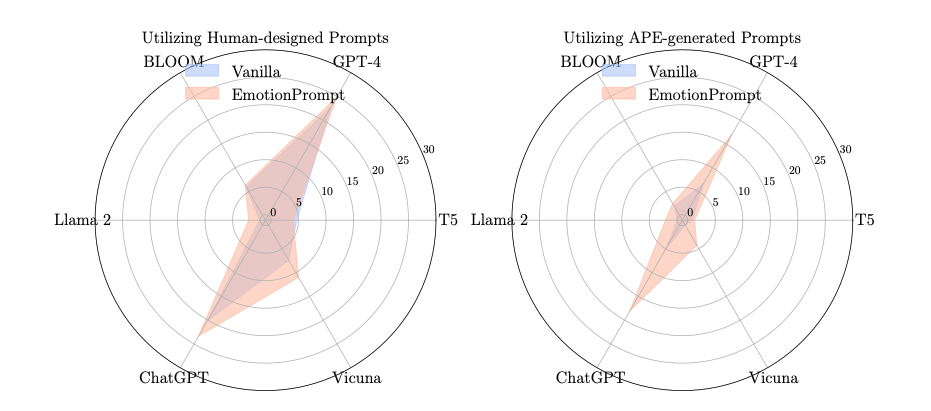
参加者による評価の結果、EmotionPromptを使用した場合のパフォーマンス、真実性、責任感の各指標において、通常のプロンプトを使用した場合と比較して、顕著な改善が見られました。
BIG-Benchテストでは、EmotionPromptを使用した場合のパフォーマンスが平均で115%向上したと報告されています。
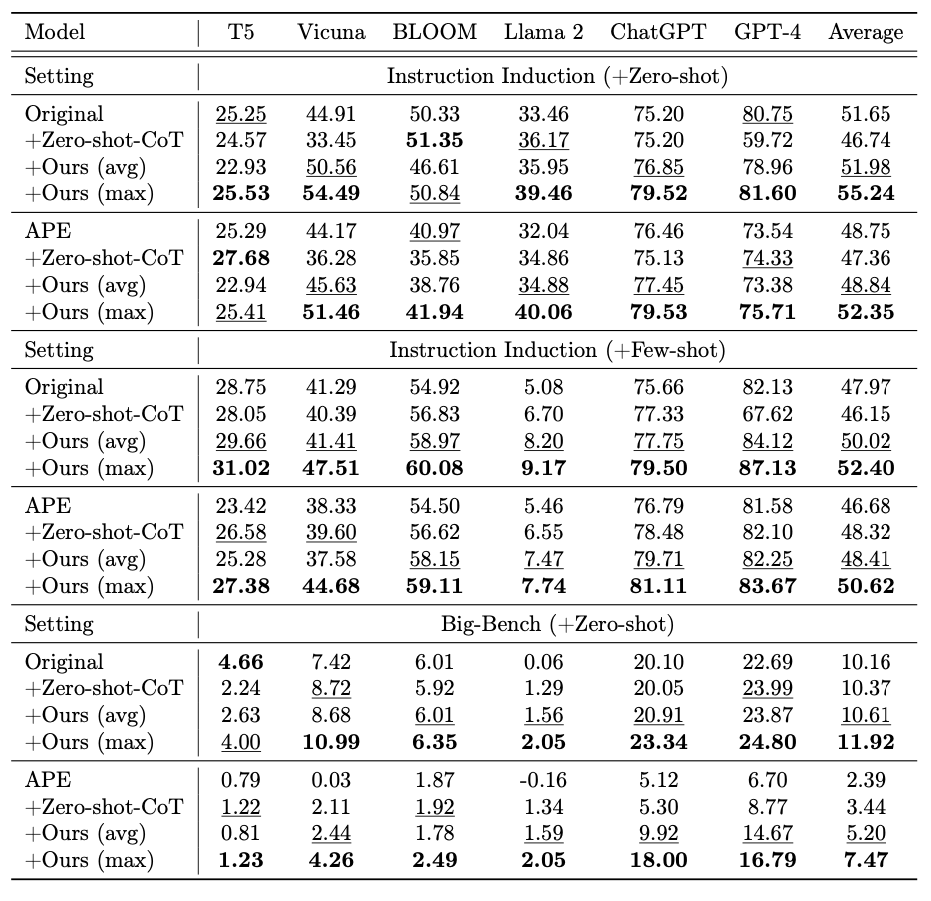
また、異なるタスクには異なる感情刺激が最適であることが示され、タスクの複雑さ、タイプ、使用される特定の指標によって、与えるべき感情刺激を変えることがよしとされました。
本記事の関連研究:GPT-4に選択肢を与えるとき、順序を入れ替えるだけで性能に大きな変化があることが明らかに
効果が確認された『EmotionPrompt』例
このセクションでは実際に効果が確認されたEmotionPromptの原文と具体化を工夫した日本語訳を掲載します。

