
人物のイラスト生成AIも高度化しています。しかし、多くの生成モデルでは「不自然さ」や「人工物感」が残ってしまうことがまだ一般的です。この問題を解決するために、SnapChat運営のSnap Inc.などの研究者らが『HyperHuman(ハイパーヒューマン)』という新しい画像生成技術を開発しました。

AIが生成する人物イラストがどれだけリアルになるのかを体感することができます。
参照論文情報
・タイトル:HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion
・著者:Xian Liu, Jian Ren, Aliaksandr Siarohin, Ivan Skorokhodov, Yanyu Li, Dahua Lin, Xihui Liu, Ziwei Liu, Sergey Tulyakov
・所属:The Chinese University of Hong Kong, The University of Hong Kong, Nanyang Technological University, Snap Inc.
・URL:https://doi.org/10.48550/arXiv.2310.08579
・プロジェクトページ:https://snap-research.github.io/HyperHuman/
従来の課題と背景
人物画像生成の困難性
人物を画像生成する際には、多くの課題が存在しています。代表的なものが、非現実的なポーズや不自然な部分(手足など)が生成される問題です。生成モデルが人体の解剖学的な認識が不足しているために起こる現象です。
既存モデルの限界
既存のモデルは、構造に対する一貫性がない人物を生成する傾向があります。技術的な要因としては、不安定な訓練、モデルサイズの小ささなども存在します。
また既存のデータセットは、解像度が低い、多様性に欠ける、または規模が不十分など、多くの問題があります。これが高品質なモデルの訓練を妨げているとも考えられています。
また、最近その性能が高い評価を受けているDALL•E3は「リアルすぎる人物画像」はあえて出力を限定する方針も表明しています。そのような背景もあり、極めてリアルな人物の画像を生成したい場合に、どのモデルがベストなのかは明確ではない状況です。
本記事の関連研究:画像分析機能を持つオープンソースLLM『LLaVA-1.5』登場。手持ちの画像を分析可能。GPT-4Vとの違い
『HyperHuman』のフレームワーク
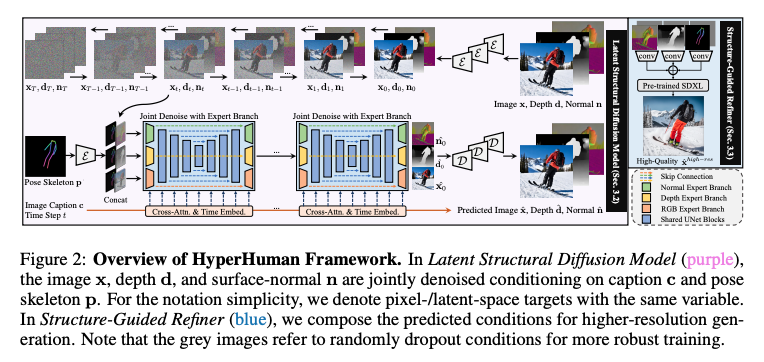
フレームワークの全体像と目的
『HyperHuman』は、人物画像生成における新たなパラダイムを提供する統一されたフレームワークです。人物画像が「多様な粒度で構造的に整っている」という基本的なコンセプトに基づいて設計されています。粗いレベルの体の骨格から、細かいレベルの空間幾何学まで、人物画像の多様な構造要素を網羅しています。
主要なコンポーネントとその機能
1. Latent Structural Diffusion Model(潜在構造拡散モデル)
モデルは、RGB画像、深度、表面法線の3つの要素を同時にデノイズ(ノイズ除去)する能力を持っています。画像の外観、空間関係、幾何学的特性を一つの統一されたネットワーク内で同時に学習することができます。各ブランチ(部分)は、構造的な認識とテクスチャの豊かさの両方で互いに補完します。
2. Structure-Guided Refiner(構造ガイドリファイナー)
このコンポーネントは、高解像度でより詳細な画像生成を目的としています。空間的に整列された構造マップを用いて、高解像度で詳細な生成を行います。生成された条件(例:ポーズ、表情など)を合成して、よりリアルな画像を出力します。
本記事の関連研究:OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化
評価データセットと実験
データセットの構築
研究者らは、まず、人体に関する大規模データセット『HumanVerse』を構築しました。『HumanVerse』は、既存のデータセット(例:Market-1501)に対し、比較的高品質な画像を提供します。
データセットは、LAION-2B-enとCOYO-700Mからキュレーションされ、人物が1〜3人含まれる画像のみが保持されました。さらに、人物が15%以上の面積で表示される画像が選ばれています。
注釈の包括性
『HumanVerse』データセットには、人間のポーズ、深度、表面法線などの包括的な注釈が含まれています。モデルにより正確な学習を可能とさせるための工夫です。
実験設定
研究者らは、定量的な分析と質的な分析の2つの設定で評価を行いました。
定量的な分析では、FID, KID, FIDCLIPなどの一般的に使用されるメトリクスを用いて評価が行われています。
質的な分析では、各モデルで高解像度の1024×1024の結果が生成され評価されました。
本記事の関連研究:画像セグメンテーションの革新「Segment Anything Model(SAM)」 Meta AIの論文から解説
実験の結果








